High throughput, low cost batch inference tailored for enterprise scale
We provide fast turnaround times, exceptional throughput, and significant cost savings for complex batch inference workloads of any scale, all while ensuring high accuracy.


80% cheaper
2x faster inference
85% cheaper
Industry leading speed and accuracy at the lowest cost with our unique ability to procure and utilize dynamically priced low cost GPUs.
Trillion-token scale
Higher rate limits & throughput than other providers. Scale instantly to 3,000 GPUs and trillions of tokens if needed, or pace it out throughout the year.
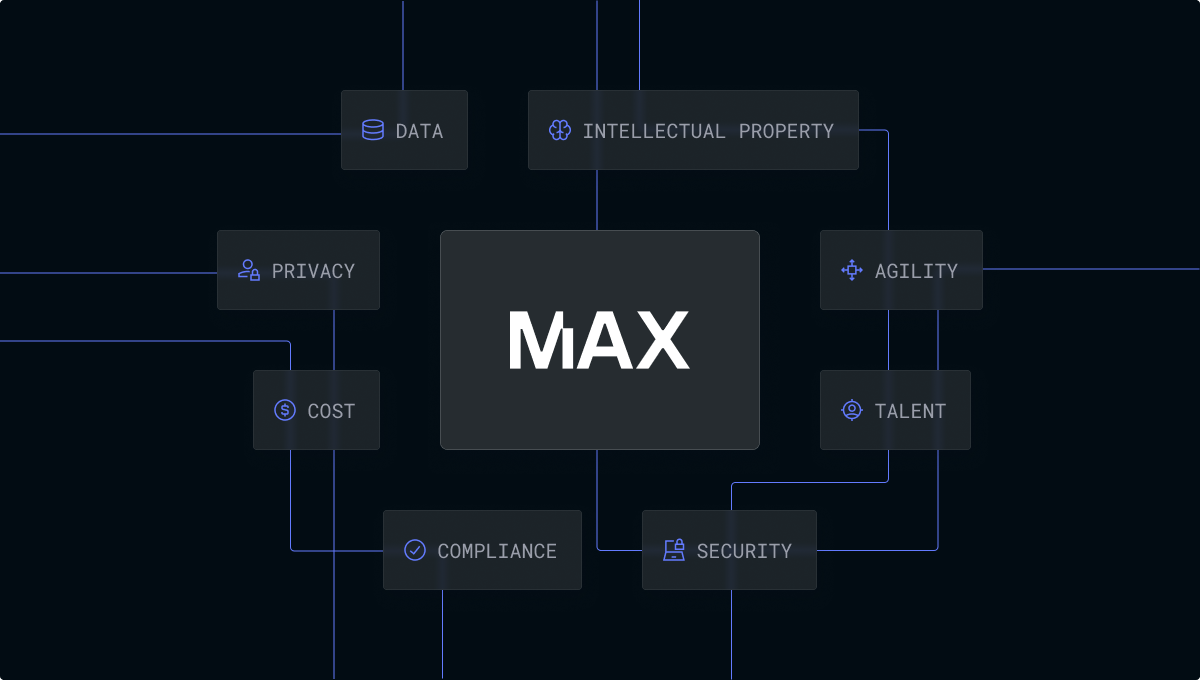
Keep your data private
We connect with your data storage, process the batches, and save the results back. Your data is never uploaded or stored on our servers.
Where we stand out
The best available pricing
Unlike other providers, our inference prices are market-based. The token price tracks the underlying market-based compute cost. In other words, we give you the lowest available price for the fastest GPU. We also run across multiple hardwares to give you the best price performance.
up to
67%
Cheaper content
summarization

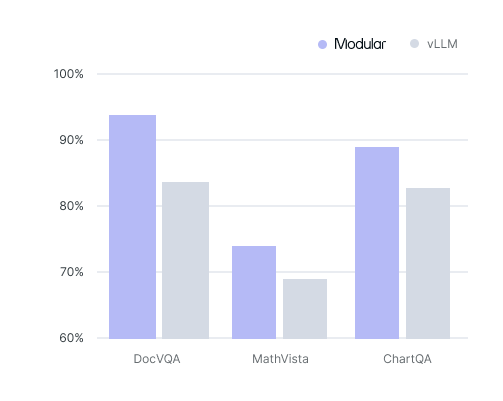
The best available accuracy
Our MAX inference engine consistently outperforms other providers across key benchmarks like DocVQA, MathVista, and ChartQA on accuracy. Let us know what benchmarking you prefer, and we’ll deliver custom accuracy benchmarks on the first batch workload of your contract.
up to
10%
Higher accuracy than other providers
Simple Process
Discovery Call
A short call to understand your workload, choose your right batch size, model, and price.
Kick off workloads
In as soon as 24 hours, we’ll kick off the first workload, after signing a contract.
Track batches in realtime
Onboard our scalable batch API and monitor progress of your submitted batches.
Invoice & Payment
Receive usage analytics for the entire job with your invoice.
Built for trillion-token, sensitive, multimodal use cases
We natively support very large scale batch inference, with far higher rate limits & throughput than other providers. Unlike other services, we don't force you to upload petabytes of data on our servers. We natively handle multimodal use cases, supporting any open source or proprietary model you want to run batches on.
Bespoke enterprise support
Our batch inference is designed for large scale, mostly enterprise, use cases. That lets us be more hands on than traditional, self-serve providers.
- Want a custom deployment?
- Need to hit specific latency, throughput, or cost requirements?
- Is there a model that's performing better in your evals, but we're not serving it?
We'll work with you to get the best possible outcomes.
Trusted hardware providers
Modular has teamed up with San Francisco Compute to deliver the most competitively priced OpenAI-compatible batch inference available. Our solution is over 85% cheaper than most open-source models. Through this exclusive partnership, we utilize their advanced hardware pricing technology, enabling us to efficiently run MAX at a trillion-token scale.
Kickoff a workload now
Hop on a quick call to get started, and then start sending your batches.
Supported models
We currently support the following models below the cost of every current provider on average. Exact prices, latency, and throughput depend on the use case & current market conditions.
Model
Hugging Face Name
Size
Price 1M Tokens
gpt‑oss‑120b
openai/gpt-oss-120b
120B
$0.04 input
$0.20 output
gpt‑oss‑20b
openai/gpt-oss-20b
20B
$0.02 input
$0.08 output
Llama‑3.1‑405B‑Instruct
meta-llama/Llama-3.1-405B-Instruct
405B
$0.50 input
$1.50 output
Llama‑3.3‑70B‑Instruct
meta-llama/Llama-3.3-70B-Instruct
70B
$0.052 input
$0.156 output
Llama‑3.1‑8B‑Instruct
meta-llama/Meta-Llama-3.1-8B-Instruct
8B
$0.008 input
$0.02 output
Llama 3.2 Vision
meta-llama/Llama-3.2-11B-Vision-Instruct
11B
$0.072 input
$0.072 output
Qwen‑2.5‑72B‑Instruct
Qwen/Qwen2.5-72B-Instruct
72B
$0.065 input
$1.25 output
Qwen2.5-VL 72B
Qwen/Qwen2.5-VL-72B-Instruct
72B
$0.125 input
$0.325 output
Qwen2.5-VL 32B
Qwen/Qwen2.5-VL-32B-Instruct
32B
$0.125 input
$0.325 output
Qwen3 32B
Qwen/Qwen3-32B
32B
$0.05 input
$0.15 output
Qwen3 A3B 30B
Qwen/Qwen3-30B-A3B-Instruct-2507
30B
$0.05 input
$0.15 output
Qwen 3‑14B
Qwen/Qwen3-14B
14B
$0.04 input
$0.12 output
Qwen 3‑8B
Qwen/Qwen3-8B
8B
$0.014 input
$0.055 output
QwQ‑32B
Qwen/QwQ-32B
32B
$0.075 input
$0.225 output
Gemma‑3‑27B‑in‑chat
google/gemma-3-27b-it
27B
$0.05 input
$0.15 output
Gemma‑3‑12B‑in‑chat
google/gemma-3-12b-it
12B
$0.04 input
$0.08 output
Gemma‑3‑4B‑in‑chat
google/gemma-3-4b-it
4B
$0.016 input
$0.032 output
Mistral Small 3.2 2506
mistralai/Mistral-Small-3.2-24B-Instruct-2506
24B
$0.04 input
$0.08 output
Mistral Nemo 2407
mistralai/Mistral-Nemo-Instruct-2407
12B
$0.02 input
$0.06 output
InternVL3‑78B
OpenGVLab/InternVL3-78B
78B
$0.125 input
$0.325 output
InternVL3‑38B
OpenGVLab/InternVL3-38B
38B
$0.125 input
$0.325 output
InternVL3‑14B
OpenGVLab/InternVL3-14B
14B
$0.072 input
$0.072 output
InternVL3‑9B
OpenGVLab/InternVL3-9B
9B
$0.05 input
$0.05 output
DeepSeek‑R1
deepseek-ai/DeepSeek-R1
671B
$0.28 input
$1.00 output
DeepSeek‑V3
deepseek-ai/DeepSeek-V3
671B
$0.112 input
$0.456 output
Llama‑4‑Maverick‑17B‑128E‑Instruct
deepseek-ai/DeepSeek-V3
671B
$0.112 input
$0.456 output
Llama‑4‑Maverick‑17B‑128E‑Instruct
meta-llama/Llama-4-Maverick-17B-128E-Instruct
400B
$0.075 input
$0.425 output
Llama‑4‑Scout‑17B‑Instruct
meta-llama/Llama-4-Scout-17B-16E-Instruct
109B
$0.05 input
$0.25 output
Qwen3 Coder A35B 480B
Qwen/Qwen3-Coder-480B-A35B-Instruct
480B
$0.32 input
$1.25 output
Qwen3 A22B 2507 235B
Qwen/Qwen3-235B-A22B-Instruct-2507
480B
$0.32 input
$1.25 output
Kimi K2
moonshotai/Kimi-K2-Instruct
1T
$0.30 input
$1.25 output
GLM 4.5
zai-org/GLM-4.5
358B
$0.30 input
$1.10 output
GLM 4.5 Air
zai-org/GLM-4.5-Air
110B
$0.16 input
$0.88 output
GLM 4.5V
zai-org/GLM-4.5V
108B
$0.30 input
$0.90 output
Scales for enterprises

Dedicated enterprise support
We are a team of the world's best AI infrastructure leaders who are reinventing and rebuilding accelerated compute for everyone.

Infinitely scalable to reduce your TCO
Optimize costs and performance with multi-node inference at massive scale across cloud or on-prem environments.

Enterprise grade SLA
Our performance is backed with an enterprise grade SLA, ensuring reliability, accountability, and peace of mind.
Developer Approved

actually flies on the GPU
@ Sanika
"after wrestling with CUDA drivers for years, it felt surprisingly… smooth. No, really: for once I wasn’t battling obscure libstdc++ errors at midnight or re-compiling kernels to coax out speed. Instead, I got a peek at writing almost-Pythonic code that compiles down to something that actually flies on the GPU."

pure iteration power
@ Jayesh
"This is about unlocking freedom for devs like me, no more vendor traps or rewrites, just pure iteration power. As someone working on challenging ML problems, this is a big thing."

impressed
@ justin_76273
“The more I benchmark, the more impressed I am with the MAX Engine.”

performance is insane
@ drdude81
“I tried MAX builds last night, impressive indeed. I couldn't believe what I was seeing... performance is insane.”

easy to optimize
@ dorjeduck
“It’s fast which is awesome. And it’s easy. It’s not CUDA programming...easy to optimize.”

potential to take over
@ svpino
“A few weeks ago, I started learning Mojo 🔥 and MAX. Mojo has the potential to take over AI development. It's Python++. Simple to learn, and extremely fast.”

was a breeze!
@ NL
“Max installation on Mac M2 and running llama3 in (q6_k and q4_k) was a breeze! Thank you Modular team!”

high performance code
@ jeremyphoward
"Mojo is Python++. It will be, when complete, a strict superset of the Python language. But it also has additional functionality so we can write high performance code that takes advantage of modern accelerators."

one language all the way
@ fnands
“Tired of the two language problem. I have one foot in the ML world and one foot in the geospatial world, and both struggle with the 'two-language' problem. Having Mojo - as one language all the way through would be awesome.”

works across the stack
@ scrumtuous
“Mojo can replace the C programs too. It works across the stack. It’s not glue code. It’s the whole ecosystem.”
completely different ballgame
@ scrumtuous
“What @modular is doing with Mojo and the MaxPlatform is a completely different ballgame.”

AI for the next generation
@ mytechnotalent
“I am focusing my time to help advance @Modular. I may be starting from scratch but I feel it’s what I need to do to contribute to #AI for the next generation.”

surest bet for longterm
@ pagilgukey
“Mojo and the MAX Graph API are the surest bet for longterm multi-arch future-substrate NN compilation”
potential to take over
@ svpino
“A few weeks ago, I started learning Mojo 🔥 and MAX. Mojo has the potential to take over AI development. It's Python++. Simple to learn, and extremely fast.”
12x faster without even trying
@ svpino
“Mojo destroys Python in speed. 12x faster without even trying. The future is bright!”

feeling of superpowers
@ Aydyn
"Mojo gives me the feeling of superpowers. I did not expect it to outperform a well-known solution like llama.cpp."

very excited
@ strangemonad
“I'm very excited to see this coming together and what it represents, not just for MAX, but my hope for what it could also mean for the broader ecosystem that mojo could interact with.”

impressive speed
@ Adalseno
"It worked like a charm, with impressive speed. Now my version is about twice as fast as Julia's (7 ms vs. 12 ms for a 10 million vector; 7 ms on the playground. I guess on my computer, it might be even faster). Amazing."

amazing achievements
@ Eprahim
“I'm excited, you're excited, everyone is excited to see what's new in Mojo and MAX and the amazing achievements of the team at Modular.”

Community is incredible
@ benny.n
“The Community is incredible and so supportive. It’s awesome to be part of.”
excited to see this coming together
@ strangemonad
“I'm very excited to see this coming together and what it represents, not just for MAX, but my hope for what it could also mean for the broader ecosystem that mojo could interact with.”
everyone is excited
@ Eprahim
“I'm excited, you're excited, everyone is excited to see what's new in Mojo and MAX and the amazing achievements of the team at Modular.”
one language all the way through
@ fnands
“Tired of the two language problem. I have one foot in the ML world and one foot in the geospatial world, and both struggle with the 'two-language' problem. Having Mojo - as one language all the way through is be awesome.”
huge increase in performance
@ Aydyn
"C is known for being as fast as assembly, but when we implemented the same logic on Mojo and used some of the out-of-the-box features, it showed a huge increase in performance... It was amazing."
The future is bright!
@ mytechnotalent
Mojo destroys Python in speed. 12x faster without even trying. The future is bright!








.png)









.png)


















.jpeg)


















































.png)


.png)