
Mojo 24.4 is now available for download, and this release includes several core language and standard library enhancements. In this blog post, we’ll dive deep into many of these features using code examples. One of the biggest highlights of this release is that we received 214 pull requests from 18 community contributors for new product features, bug fixes, documentation enhancements, and code refactoring. These contributions resulted in 30 net new features in the standard library, accounting for 11% of all improvements in this release. We’re incredibly proud of the momentum we’re seeing with community contributions, and it goes without saying – you are the real star of this release. On behalf of the entire Mojo team, we’d like to thank you for all your contributions to making Mojo awesome!

Throughout the rest of the blog post, we’ll discuss many of the new features in this release with code examples that you can find in a Jupyter Notebook on GitHub. As always, the official changelog has an exhaustive list of new features, what’s changed, what’s removed, and what’s fixed. Before we continue, don’t forget to upgrade your Mojo🔥. Let’s dive into the new features.
Improved Collections: New List and Dict features
In Mojo 24.4 List and Dict introduce several new features to make them even more Pythonic. Many of these features have come directly from our community:
- List has new index(), count(), __contains__() and conforms to Stringable trait, thanks to contributions by @gabrieldemarmiesse, and @rd4com
- Dict has new clear(), reversed(), get(key), items(), values() and conforms to Stringable trait, thanks to contributions by @jayzhan211, @gabrieldemarmiesse, and @martinvuyk
Let’s take a look at how to use these through code examples.
Enhancements to List
In this example, we’ll calculate word frequency from the contents of a webpage and plot the results as a word cloud. In the code below, we use Mojo's Python interoperability feature to preprocess the text, tokenize it, and remove stop words. We also use the Python interoperability features to plot the results. For the purpose of demonstration, we’ll use the url = "https://docs.modular.com/mojo/manual/basics" to generate the word cloud from the Mojo manual. Feel free to experiment with different URLs. Now, let’s take a look at the code.
Output:

In the example above, first we fetch a list of filtered words from the webpage in url using utils.fetch_and_preprocess_text(url). After that we’re ready to calculate word frequencies.
We highlight the use of __contains__() in the code word[] not in unique_words: where the condition checks whether the current word is already in the unique_words list. If the word is not in unique_words, it means this is the first time we are encountering this word. If the word is not already in unique_words, we append it to the unique_words list. We then count how many times this word appears in the original words list using the count() method. mojo_word_list.count(word) counts the number of occurrences of word[] in mojo_word_list. The frequency count of the word is appended to the word_frequencies list at the same index as the word in unique_words. This means that unique_words and word_frequencies will have corresponding elements.
To plot the word cloud, each word is plotted at a random position with a size proportional to its frequency, and random colors are used for the words. We use the Python interoperability features to call the plotting function in utils.plot_word_cloud().
Enhancements to Dict
In this example we’ll use the Monte Carlo method for approximating the approximate value of Pi using new Dict features. The Monte Carlo method approximates pi by randomly generating points within a unit square and counting the number of points that fall within the unit circle inscribed within the square. The ratio of the points inside the circle to the total points can be used to approximate. We’ve written about this in more detail in an earlier blog post. Be sure to read that for more details on the math behind why this works. In this demo below we use Dict to methods exclusively instead of Arrays to implement the solution.
Output:
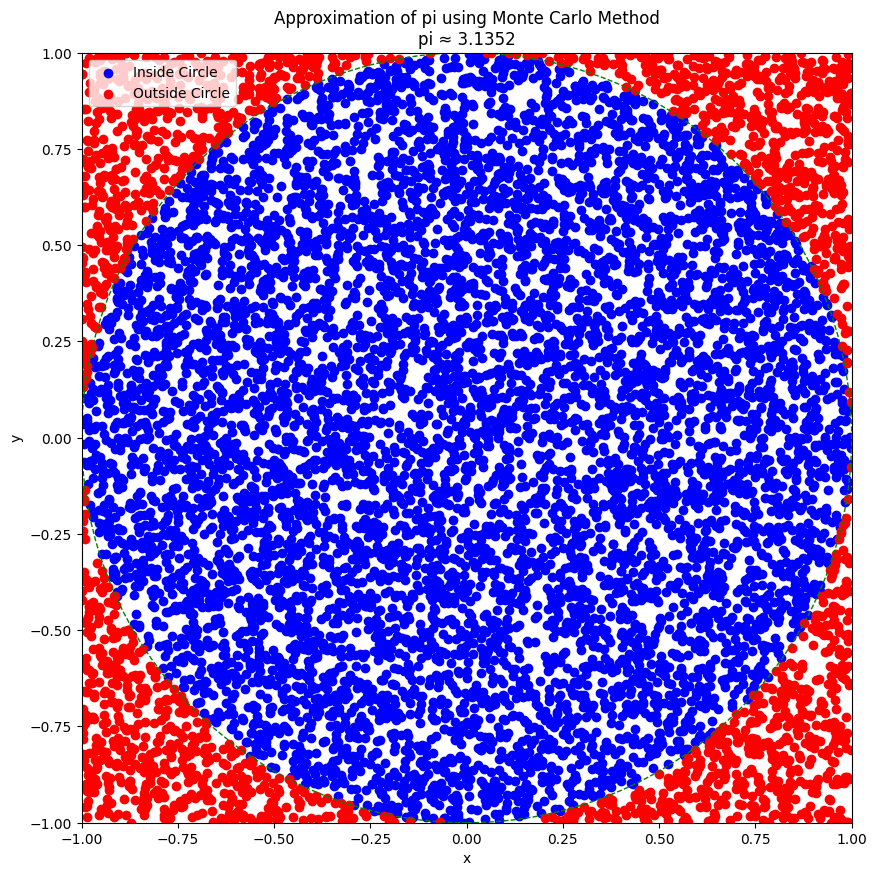
In the example above, we first create a Points dictionary, from new fromkeys static method to initialize Dict with keys from the List variable keys and set values to be empty lists. We use points_data.items() to print each items’ key and value. We also use reversed() to print the reversed order of keys. We also use get(key) to retrieve the points data for a specific key ("inside" in this case) and since the output of get() is an Optional type we use the take() function to retrieve the value. Finally we also demonstrate the use of clear to clear the dictionary. To plot the image above we made use of a utility function in Python using Python interoperability, called utils.plot_points()
New traits: Absable, Powable, Representable, Indexer
Mojo 24.4 also includes new traits to make writing Math equations simpler, print string representation of objects and define containers that can be indexed using integral values.
- Structs that conform to Absable and Powable traits will work with built in abs() and pow() functions. Absable types must implement __abs__() dunder method and Powable type must implement the __pow__() dunder method. Powable types can also be used with operator ** in addition to the pow() function.
- Objects of structs that conform to the Representable trait must implement a __repr__() dunder method, which enables the repr() to be called on objects to provide a string that can, if possible, be used to recreate the object and can be very useful for debugging. Thanks to @gabrieldemarmiesse for contributing this feature.
- Structs that conform to the Indexer trait allow their objects to be used as index variables that can be passed to __getitem__() and __setitem__(). Types conforming to the Indexer trait implement __index__() dunder method and are implicitly convertible to Int or by calling the built in function index().
In the example below I’ve implemented a struct called MojoArray that conforms to Absable, Powable, and Representable traits, therefore it implements __abs__(), __pow__() and __repr__() dunder methods. Here is the skeleton of our struct, the full implementation is available on GitHub.
In the code example above, we compute vectorized __abs__() and __pow__() as follows:
And __repr__() as follows:
Now, let’s create an object of the MojoArray struct to see these methods in action.
Output:
As you can see writing abs(v1-v2)**exp is a very expressive way to write math equations with these new traits vs. something like (v1-v2).abs().pow(exp) which is what we’d have done previously.
Mojo 24.4 also includes a few other math specific traits math.Ceilable, math.CeilDivable, math.CeilDivableRaising, math.Floorable, and Truncable. See the changelog for more details.
os module enhancements
Mojo 24.4 also includes several file IO enhancements that makes Mojo standard library’s os module more Pythonic. Particularly, this release introduces the following functions: mkdir(), rmdir(), os.path.getsize(), os.path.join() and a new tempfile module that implements gettempdir() and mkdtemp() functions, thanks to contributions from @artemiogr97. Let’s take a look at an example to see how to use these methods in your own projects.
Output:
base64 package enhancements
This release also includes a new base64 package that offers encoding and decoding support for both the Base64 and Base16 encoding schemes. Base64 encoding is often used in tokenizers for large language models (LLMs) and we use it in our implementations of bpe and tiktoken tokenizer utilities for Llama3. Check out our Llama3 example in this repository. Let’s take a look at an example that show you how to use this new package in the Mojo standard library.
Output:
You can see that the original and decoded images plotted side by side are the same. We use the utils.plot_original_decoded_images() helper function written in Python and called from Mojo using the Python interoperability feature.

Core language features
Mojo 24.4 also includes several core language features that are a bit harder to demonstrate with code examples. Most notably, this release Mojo has updated how def function arguments are handled. Previously, arguments were copied by default (owned convention), making them mutable but potentially causing performance issues due to unnecessary copies. Now, arguments use borrowed convention by default and only copied if mutated within the function.
In this release you can also return multiple values from a function as a Tuple that can be unpacked into individual variables. For example in the earlier Enhancements to Dict section we define a method: def approximate_pi(num_points: Int) -> (Float64, Dict[String, List[List[Float64]]]). We call this method in this way to get the values of the Tuple into separate variables: pi_approximation, points_data = approximate_pi(num_points), where as previously we had to get the value as a Tuple variable and index into it to extract the values.
This release also introduces the new @parameter loop decorator which can be used with for loops where the loop variable is a compile time constant. This allows the Mojo compiler to perform a full unroll of the loop to improve performance. With the introduction of @parameter decorator for loops, the previously recommended @unroll decorator has now been deprecated.
There are many more core language enhancements in this release, see the changelog for a complete list.
New documentation pages
We also updated our documentation to include dedicated pages that dive deeper into the following topics:
- Control flow: https://docs.modular.com/mojo/manual/control-flow
- Testing: https://docs.modular.com/mojo/tools/testing
- Unsafe pointers: https://docs.modular.com/mojo/manual/pointers
But wait, there’s more!
Mojo 24.4 includes many more features that we didn’t cover in this blog post. Check out the changelog for a detailed list of what’s new, changed, moved, renamed, and fixed in this release.
MAX 24.4 is also available for download today and for the first time we’re making it available on Mac OS. This release of MAX also includes several enhancements including New Quantization API for MAX Graphs, and full implementation of Llama 2 and Llama 3 models using Graph API with quantization. Read more in the MAX 24.4 announcement blog post.
All the examples I used in this blog post are available in a Jupyter Notebook on GitHub, check it out!
- Download MAX and Mojo.
- Head over to the docs to read the Mojo🔥 manual and learn about APIs.
- Explore the examples on GitHub.
- Join our Discord community.
- Contribute to discussions on the Mojo GitHub.
- Read and subscribe to Modverse Newsletter.
- Read Mojo blog posts, watch developer videos and past live streams.
- Report feedback, including issues on our GitHub tracker.
Until next time! 🔥


