
Infinite scale made easy for the largest AI workloads
MAX simplifies the entire AI agent workflow, ensuring your solutions are built quickly, run efficiently, and scale effortlessly across any environment.
- Performance out-of-the-box
- Long context windows
- Bring your own model
- Build your own embeddings
- configurable KVCache
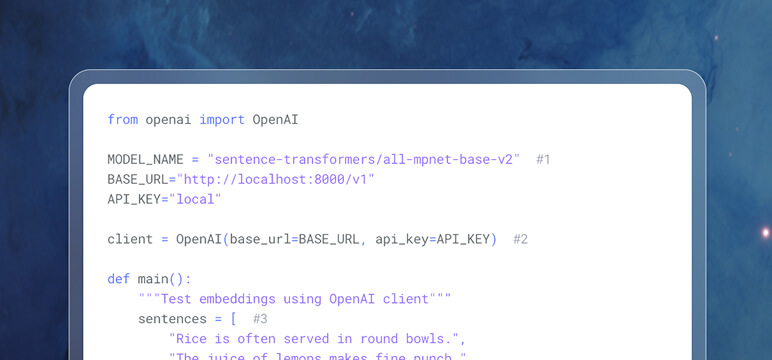
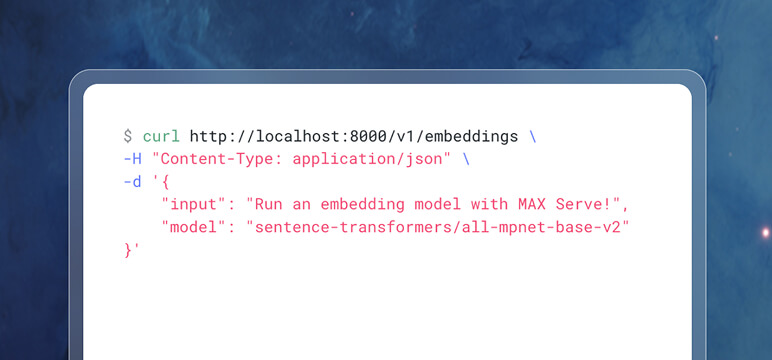
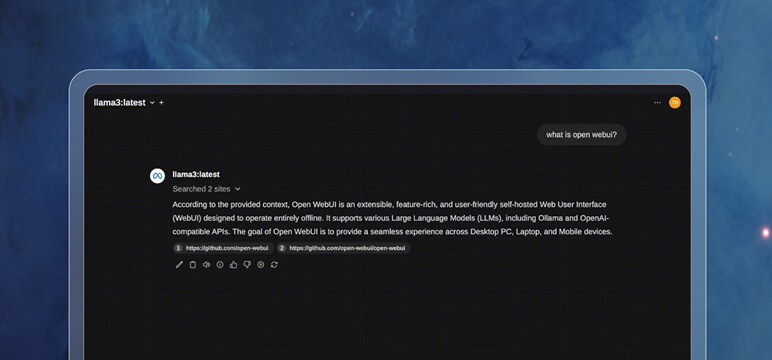
Instant Performance
Out-of-the-box performance: Hundreds of GenAI models, optimized by MAX, with no further code changes needed for blazing fast inference. Browse models
Optimize performance further: Get fastest realtime inference ever with Mojo for maximum efficiency and scalability on any hardware.
Cost-to-Performance Ratio: MAX's speed will bring your overall AI budget down. Read our paper for how much you save at scale.


Hardware Portability
Local to Cloud: Develop and test your models on your laptop, then deploy effortlessly to NVIDIA GPUs in the cloud—no code changes needed.
No Vendor Lock-in: Use the best hardware for your AI needs without proprietary software constraints.
Optimize any GPU: Achieve maximum performance and efficiency across different GPU hardware, regardless of vendor.
Seamless Deployment
Effortless Cloud Deployment: Scale across cloud providers with ready-to-use Docker containers and Kubernetes-native orchestration.
OpenAI-compatible endpoint: Seamlessly integrate with existing AI workflows and applications.
Hardware Optionality: Run AI models on any hardware, giving you complete deployment flexibility.

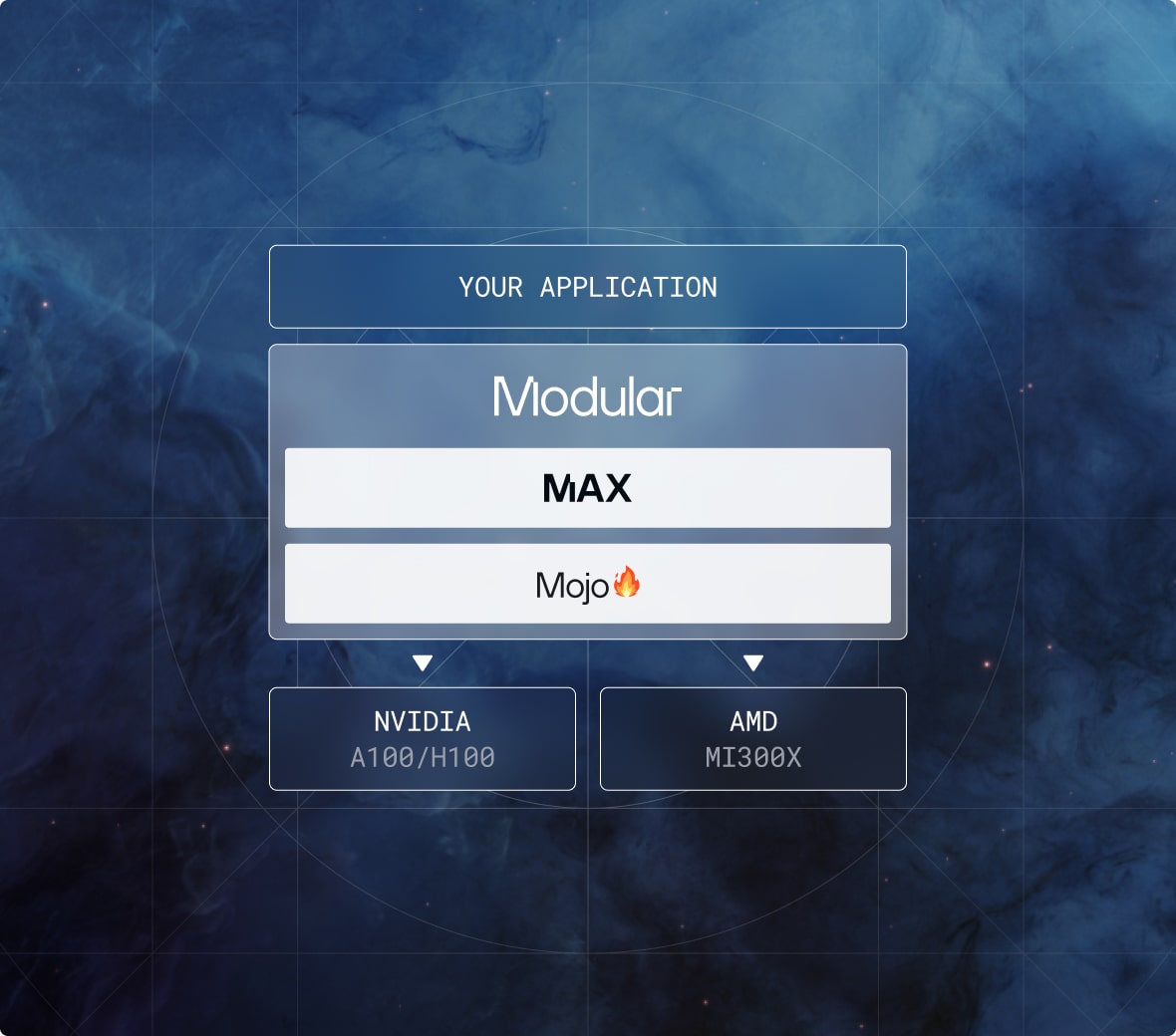
Build from the ground up
Minimal Dependencies: MAX runs with just NVIDIA and AMD GPU drivers, freeing you from proprietary software constraints.
Lightweight & Optimized Deployment: Minimize deployment binaries, ensuring faster builds, seamless scaling, and improved performance.
Vertically Integrated: MAX unifies AI tooling into a single stack, reducing dependencies and streamlining your workflow.
Core APIs
Graph-Based Execution: Transform AI models into optimized computational graphs, unlocking faster execution, reduced latency, and peak efficiency across hardware.
Unified Programming Model: Write high-performance AI code in an intuitive Pythonic environment, with Mojo’s low-level power when you need it—no switching between languages.
Effortless Host-Device Compute: MAX’s heterogeneous compute support ensures smooth coordination between CPUs, GPUs, and accelerators—maximizing performance without hardware constraints.
Multi-GPU Scaling: Distribute workloads across multiple GPUs, ensuring high efficiency, minimal bottlenecks, and lightning-fast AI inference and training.
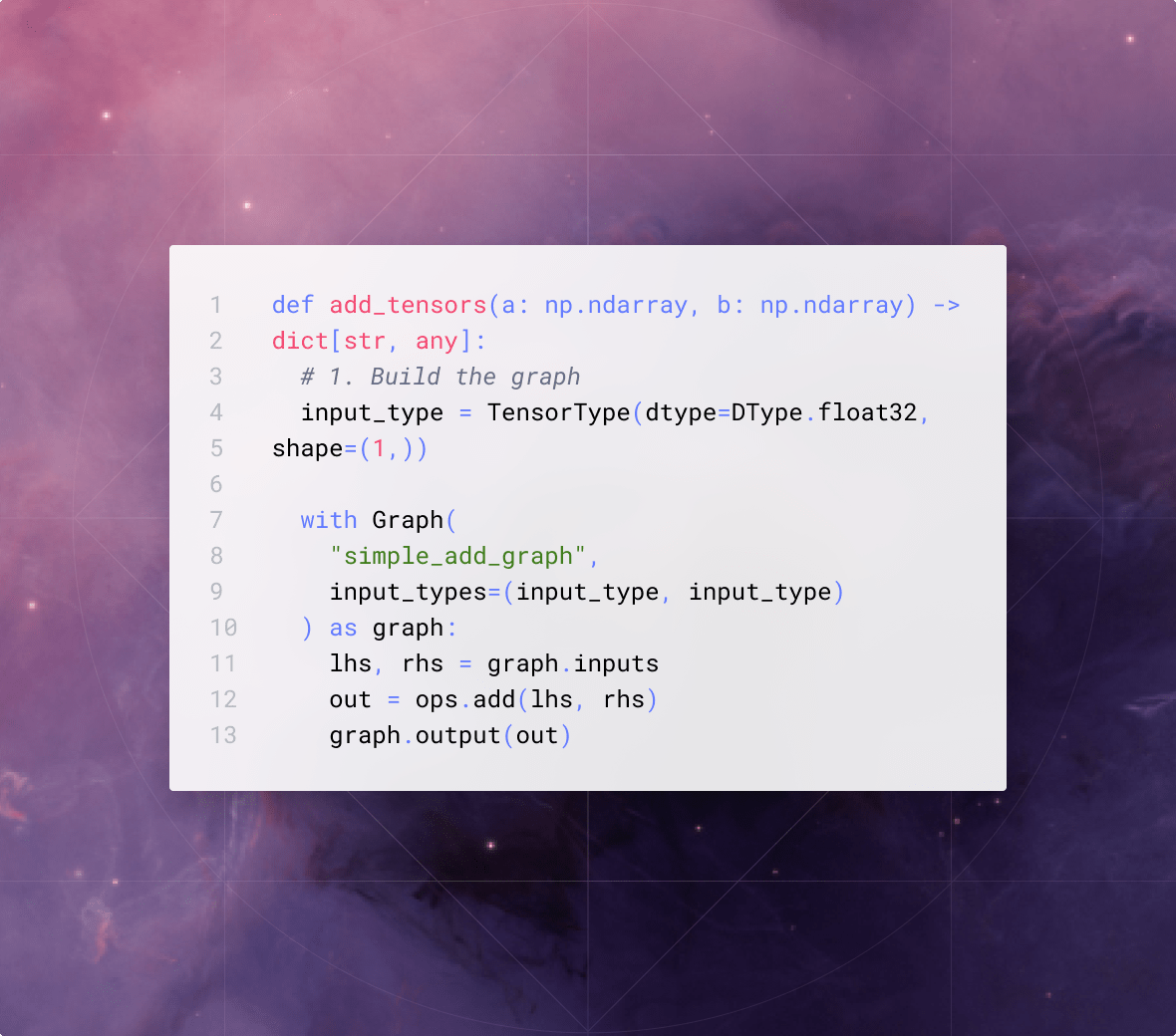



Mojo: Fast, portable code
Pythonic: An innovative, high-performance pythonic language designed for writing systems-level code for AI workloads.
Incredible tooling: Utilize a incredible range of tools including a LLDB debugger, Cursor Integration and a full package manager.
Low-level control: With an ownership memory model that gives developers complete and safe control of memory lifetime, along with compile time parameterization and generalized types.
Accelerator Programming
Hand-Tune Performance: Write custom workload-specific optimizations, eliminating inefficiencies and maximizing hardware performance.
Hardware-Specific Tuning: Customize operations to take full advantage of different AI accelerators (GPUs, TPUs, custom ASICs) for optimized execution.
Future Proof AI Development: Ensure that you can adapt and optimize your AI models without being locked into a specific ecosystem.

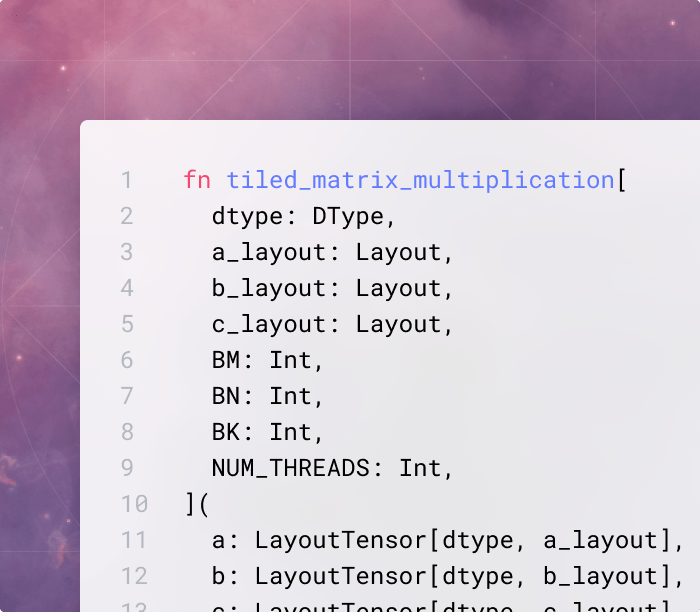
Build even more solutions with MAX



FREE for everyone
Paid support for scaled enterprise deployments
Developer Approved


The future is bright!
mytechnotalent
Mojo destroys Python in speed. 12x faster without even trying. The future is bright!

performance is insane
drdude81
“I tried MAX builds last night, impressive indeed. I couldn't believe what I was seeing... performance is insane.”

huge increase in performance
Aydyn
"C is known for being as fast as assembly, but when we implemented the same logic on Mojo and used some of the out-of-the-box features, it showed a huge increase in performance... It was amazing."

easy to optimize
dorjeduck
“It’s fast which is awesome. And it’s easy. It’s not CUDA programming...easy to optimize.”

impressive speed
Adalseno
"It worked like a charm, with impressive speed. Now my version is about twice as fast as Julia's (7 ms vs. 12 ms for a 10 million vector; 7 ms on the playground. I guess on my computer, it might be even faster). Amazing."

works across the stack
scrumtuous
“Mojo can replace the C programs too. It works across the stack. It’s not glue code. It’s the whole ecosystem.”

12x faster without even trying
svpino
“Mojo destroys Python in speed. 12x faster without even trying. The future is bright!”

high performance code
jeremyphoward
"Mojo is Python++. It will be, when complete, a strict superset of the Python language. But it also has additional functionality so we can write high performance code that takes advantage of modern accelerators."

amazing achievements
Eprahim
“I'm excited, you're excited, everyone is excited to see what's new in Mojo and MAX and the amazing achievements of the team at Modular.”

impressed
justin_76273
“The more I benchmark, the more impressed I am with the MAX Engine.”

was a breeze!
NL
“Max installation on Mac M2 and running llama3 in (q6_k and q4_k) was a breeze! Thank you Modular team!”

pure iteration power
Jayesh
"This is about unlocking freedom for devs like me, no more vendor traps or rewrites, just pure iteration power. As someone working on challenging ML problems, this is a big thing."
completely different ballgame
scrumtuous
“What @modular is doing with Mojo and the MaxPlatform is a completely different ballgame.”
potential to take over
svpino
“A few weeks ago, I started learning Mojo 🔥 and MAX. Mojo has the potential to take over AI development. It's Python++. Simple to learn, and extremely fast.”

Community is incredible
benny.n
“The Community is incredible and so supportive. It’s awesome to be part of.”

actually flies on the GPU
Sanika
"after wrestling with CUDA drivers for years, it felt surprisingly… smooth. No, really: for once I wasn’t battling obscure libstdc++ errors at midnight or re-compiling kernels to coax out speed. Instead, I got a peek at writing almost-Pythonic code that compiles down to something that actually flies on the GPU."

very excited
strangemonad
“I'm very excited to see this coming together and what it represents, not just for MAX, but my hope for what it could also mean for the broader ecosystem that mojo could interact with.”

one language all the way through
fnands
“Tired of the two language problem. I have one foot in the ML world and one foot in the geospatial world, and both struggle with the 'two-language' problem. Having Mojo - as one language all the way through is be awesome.”

surest bet for longterm
pagilgukey
“Mojo and the MAX Graph API are the surest bet for longterm multi-arch future-substrate NN compilation”
feeling of superpowers
Aydyn
"Mojo gives me the feeling of superpowers. I did not expect it to outperform a well-known solution like llama.cpp."
Get started guide
Install MAX with a few commands and deploy a GenAI model locally.
Read Guide
Browse open models
500+ models, many optimized for lightning-fast performance
Browse models