.png)

Modular Platform 25.5 is here, and introduces Large Scale Batch Inference: a highly asynchronous, at-scale batch API built on open standards and powered by Mammoth. We're launching this new capability through our partner SF Compute, enabling high-volume AI performance with a fast, accurate, and efficient platform that seamlessly scales workloads across any hardware.
This release also features the open source launch of the MAX Graph API and expanded support for writing custom PyTorch operators directly in MAX. In addition, we’ve made Modular Platform development and deployment easier with optimized Docker containers and new standalone Mojo Conda packages.
Large Scale Batch Inference, powered by Mammoth
As AI workloads grow in complexity and scale, infrastructure needs to be smarter, faster, and more efficient. That’s why we partnered with SF Compute to build the Large Scale Batch Inference API, a high-throughput serving product powered by Mammoth, Modular’s intelligent Kubernetes-native cluster orchestration layer. To maximize throughput and efficiency, Mammoth continuously distributes jobs across GPU clusters using an optimized scheduler to maintain over 90% utilization of cluster resources.
This offering supports more than 20 state-of-the-art models across language, vision, and multimodal domains, runs on both NVIDIA and AMD hardware, and includes an OpenAI-compatible API. Watch our joint launch video and check out the blog post to learn more about SF Compute’s Large Scale Inference API. Sign up to get access to Large Scale Batch Inference through SF Compute.

Lightweight, modular packaging
Standalone Mojo packages
Mojo has empowered a new generation of GPU developers to write portable, performant code that breaks free from vendor lock-in. With 25.5, we're making GPU programming with Mojo even more accessible through two new standalone Conda packages.
The mojo package delivers everything you need for AI-independent CPU and GPU kernel development: compiler, runtime, debugger, and LSP, without requiring additional MAX packages. For streamlined distribution of Mojo-only or hybrid Python/Mojo packages, the mojo-compiler package includes just the essentials: compiler and runtime. This lightweight option provides a solid foundation for distributing Mojo applications and libraries through the official Modular community package repository. A Python wheel distribution is currently in the works to further simplify integration workflows.
Whether you’re new to GPU development or looking to optimize the performance of your existing system, our Mojo GPU Puzzles and GPU programming docs will take you from writing basic operations to crafting high-performance matrix multiplication.
Lighter-weight MAX serving packages
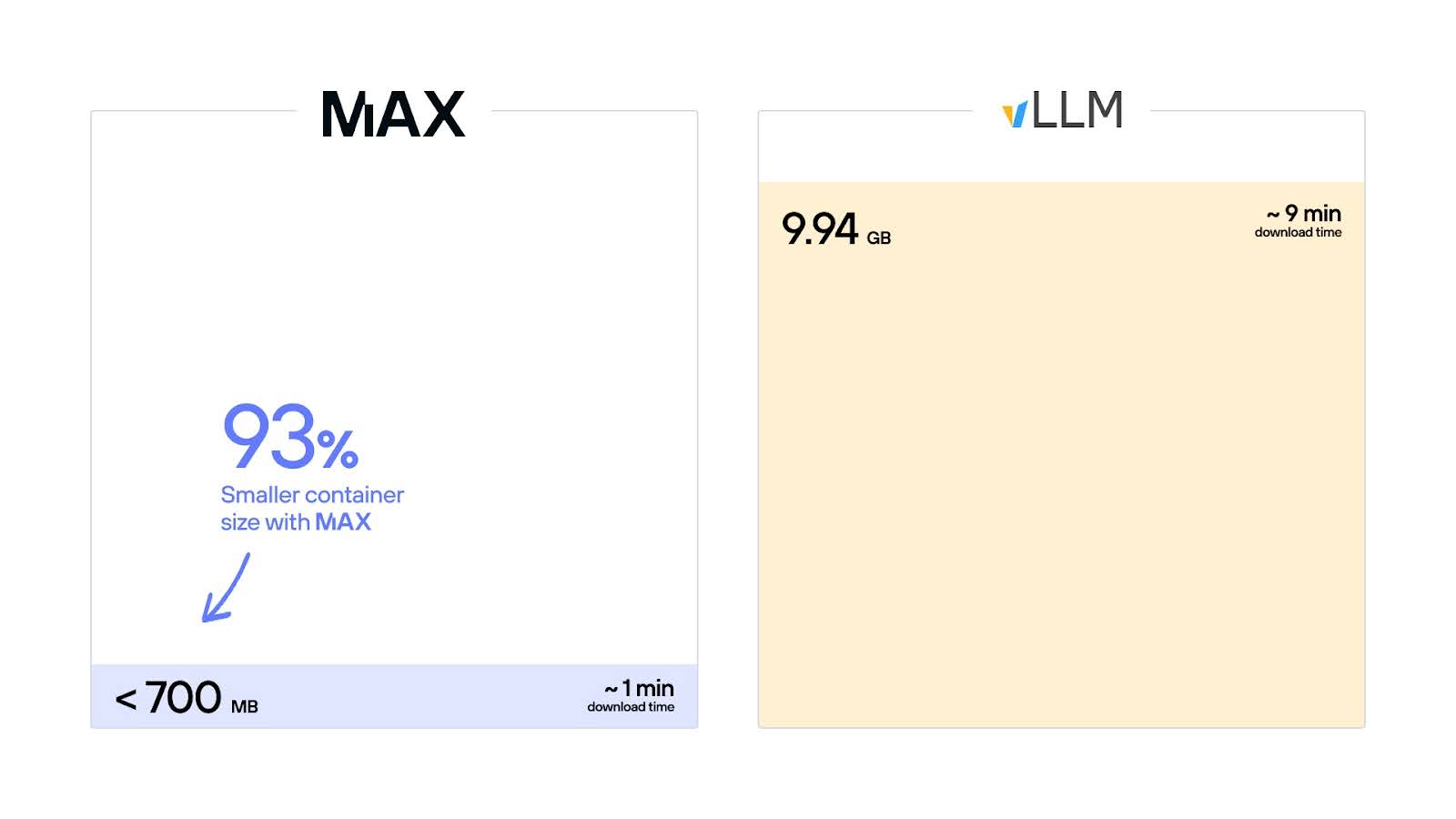
To further reduce deployment overheads and drastically reduce cold start time in production, we’ve eliminated PyTorch dependencies from our containers, making MAX serving packages leaner than ever. Now under 700 MB for NVIDIA GPUs, you can deploy and scale your production workloads even faster, with a container that is over 90% smaller than the vLLM equivalent.
Open source MAX Graph API
This release also includes the open source launch of the MAX Graph API – the Python-based engine behind our state-of-the-art models, powered by the Mojo kernel library. With it, you can now build open, portable, GPU-accelerated graphs directly in Python.
Freely available code means that AI coding assistants can leverage the full source as a reference, making it faster and easier to port your most critical models to the Modular Platform. We’ve also enhanced the Graph API to perform compile-time verification of custom graphs, reducing development cycles and ensuring model correctness.
Earlier this year, we open-sourced all MAX kernels. Now, you can explore the model-building interfaces themselves – complete with supporting code and unit tests that demonstrate each kernel in small, well-defined examples.
Want to learn more? Connect with our growing community of AI developers, share your breakthroughs, and get expert help on the Modular community forum.
Seamless MAX and PyTorch integration
New in 25.5, MAX graphs can now be seamlessly integrated into PyTorch workflows as custom operators.
With the new @graph_op decorator, any MAX graph can be automatically wrapped as a custom PyTorch operator – dramatically expanding how you can extend PyTorch with MAX. This makes it easy to replace slow, platform-specific PyTorch kernels with high-performance MAX implementations, or even swap out entire sections of a model for faster, portable MAX graphs.
Best of all, you can do this while preserving your existing PyTorch codebase, ensuring minimal disruption and maximum performance gains.
Explore the full update
Check out all of 25.5’s updates with the full MAX and Mojo changelogs. Mojo adds parametric aliases, improved string handling, the Iterator trait, and stronger type-checking for custom GPU functions. MAX improvements include faster prefix caching using Mojo, up to 12x faster support for the OpenAI API’s logprobs and echo request parameters, and Idefics3 model support.
Get started now!
Ready to experience Modular 25.5? Get started by installing Modular and running GPU-accelerated inference with our quickstart guide, then explore our tutorials for step-by-step production deployment. Tune into next week's livestream to get an inside look at what's new in Modular Platform 25.5 and a chance to ask the team your questions live.


