.png)

Modular is excited to announce a partnership with Advanced Micro Devices, Inc. (AMD), one of the world’s leading AI semiconductor companies. Together, we’re bringing the benefits of the Modular Platform to AMD GPUs, delivering infrastructure solutions optimized for today and tomorrow’s most demanding AI workloads.
“We're truly in a golden age of AI, and at AMD we're proud to deliver world-class compute for the next generation of large-scale inference and training workloads… We also know that great hardware alone is not enough. We've invested deeply in open software with ROCm, empowering developers and researchers with the tools they need to build, optimize, and scale AI systems on AMD. This is why we are excited to partner with Modular… and we’re thrilled that we can empower developers and researchers to build the future of AI. “ – Vamsi Boppana, Senior Vice President, AI - AMD
This partnership marks the general availability of the Modular Platform across AMD's GPU portfolio, a significant milestone in heterogeneous AI computing infrastructure. Effective immediately, developers can deploy the Modular Platform on AMD's flagship datacenter accelerators, including the MI300 and MI325 series.
The Modular Platform, powered by the MAX inference server and the Mojo programming language, delivers unprecedented performance optimization for AMD hardware. In rigorous benchmarking against existing open source AI infrastructure stacks, we demonstrate superior inference efficiency, achieving up to 53% better throughput on prefill-heavy, BF16 workloads on Llama 3.1, Gemma 3, Mistral, and other state-of-the-art language models—all from a single container that scales across NVIDIA and AMD GPUs.
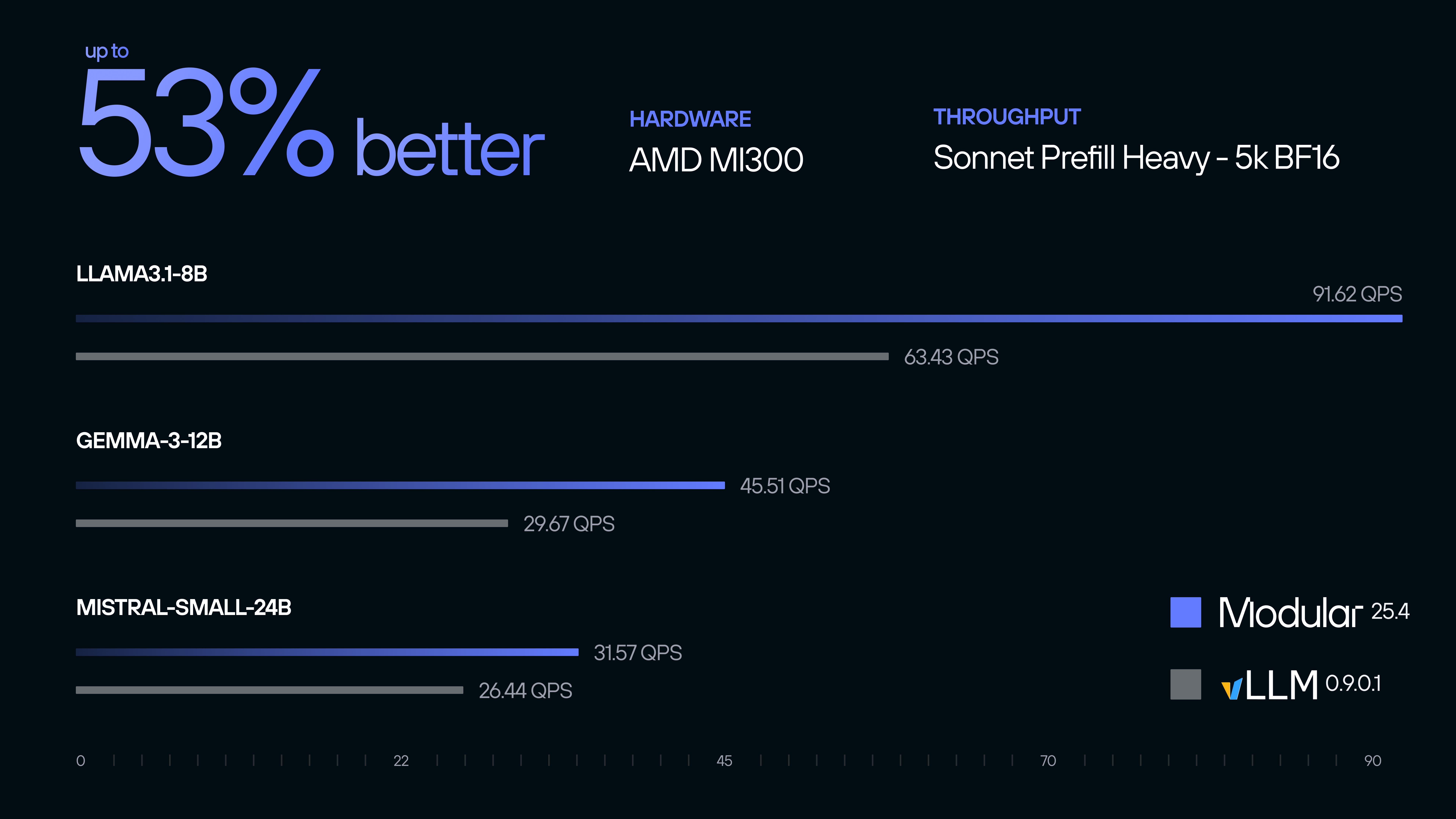
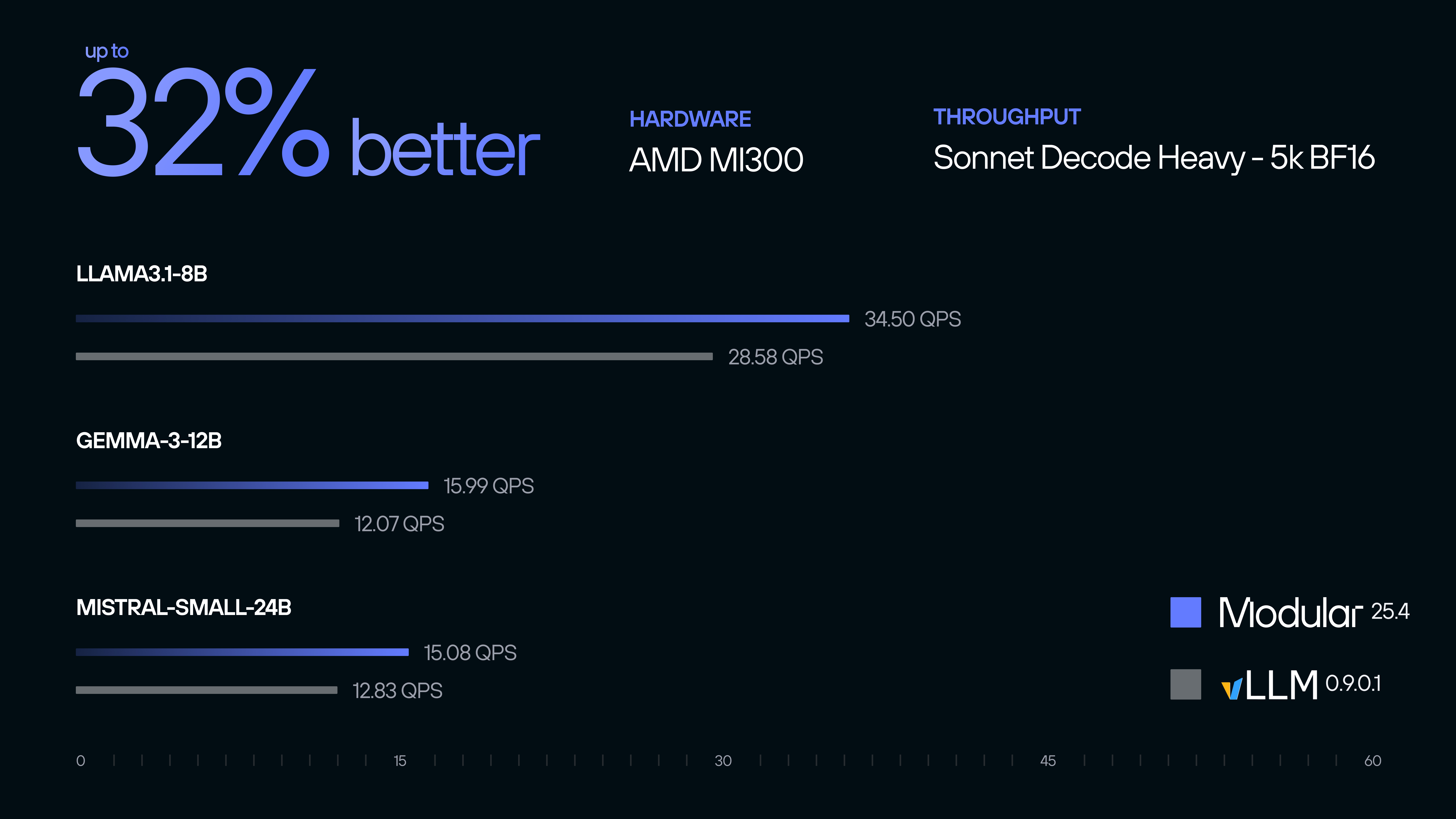
For decode-heavy BF16 workloads, we demonstrate up to 32% better throughput performance against existing AI infrastructure stacks.
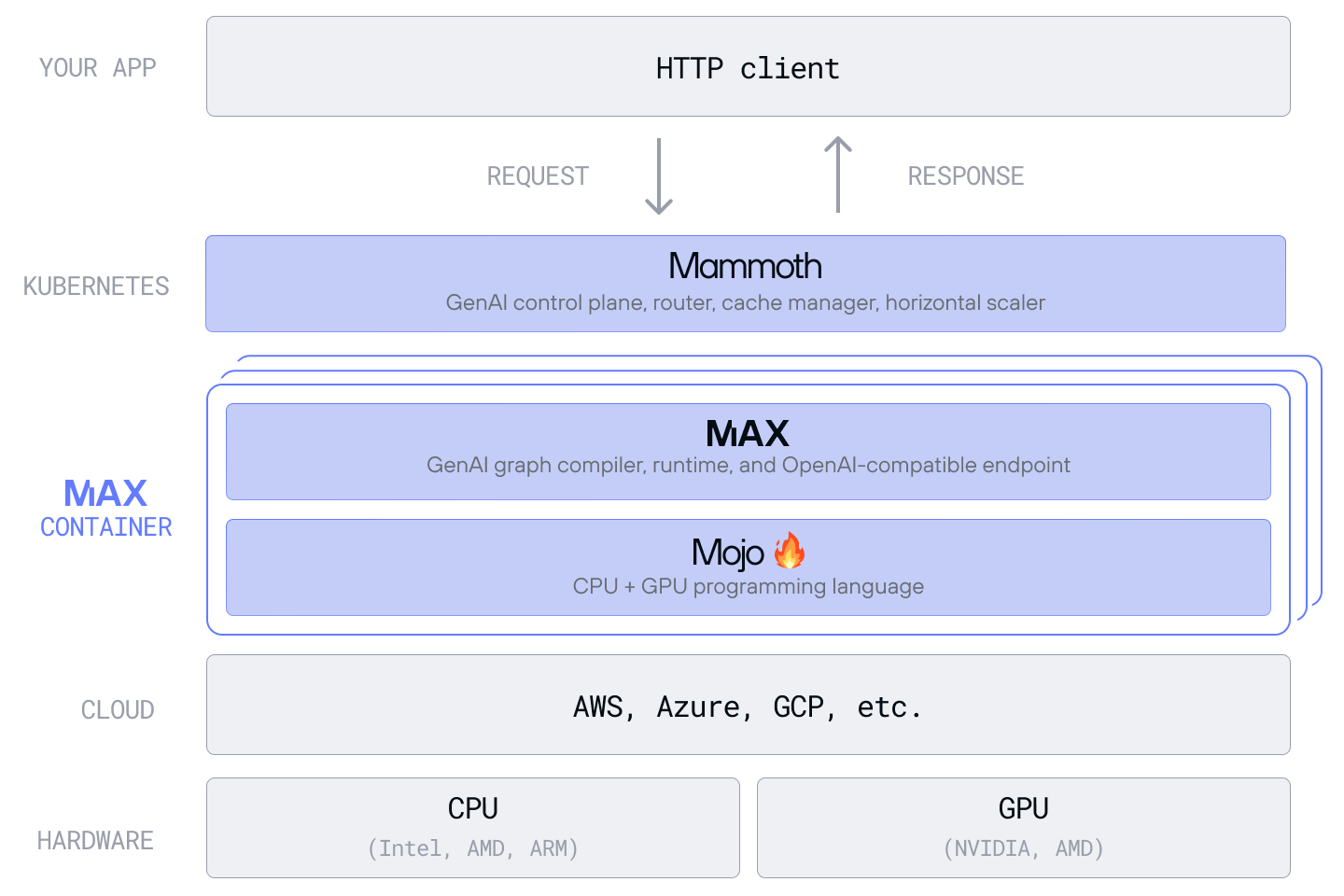
These breakthroughs are made possible by Modular Platform, the industry’s first truly hardware-agnostic AI infrastructure stack—delivering a unified platform that enables seamless deployment across diverse hardware architectures without modifying a single line of code.
Developers can now build portable, high-performance GenAI deployments that run on any platform.
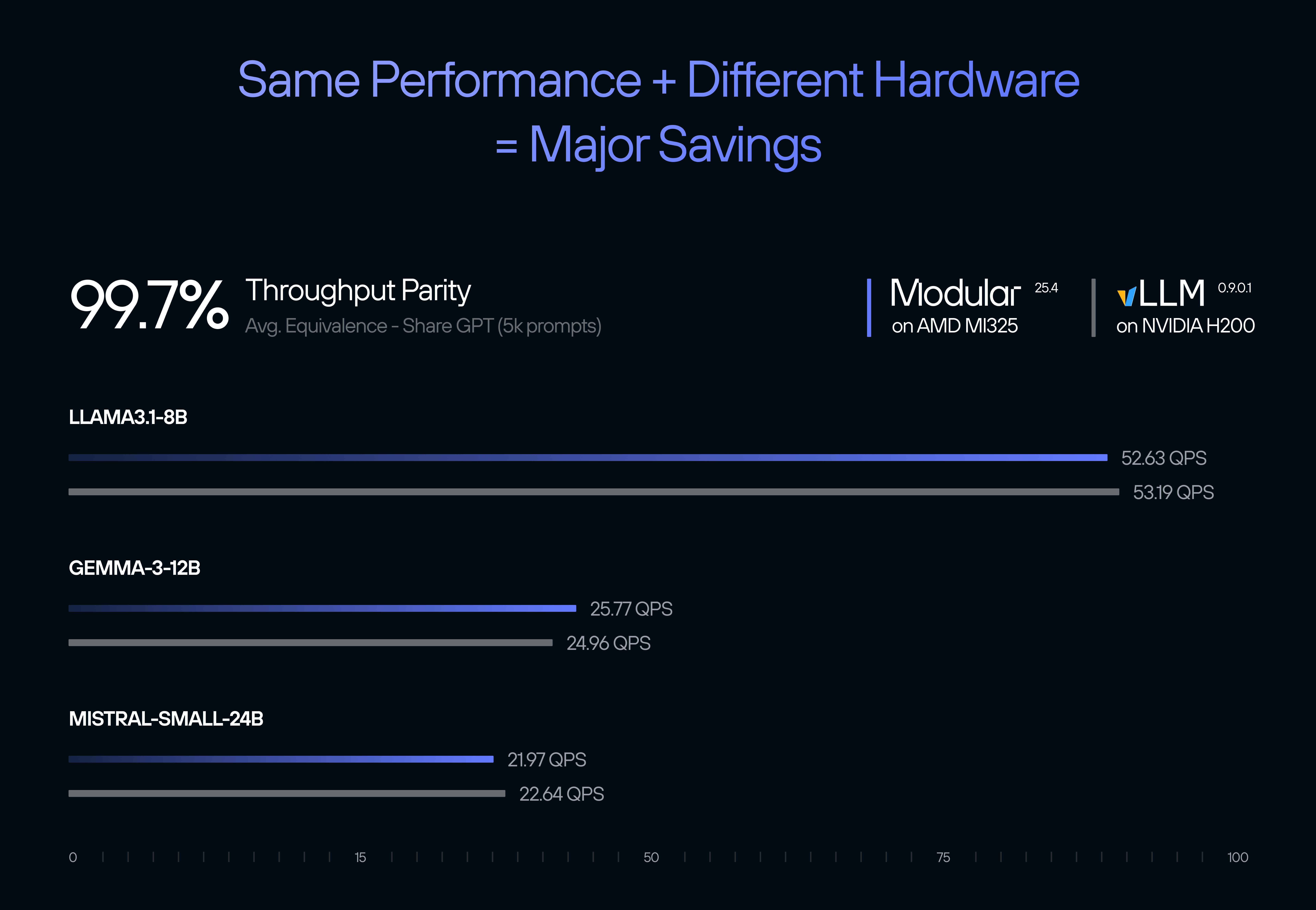
Enterprises finally gain real freedom to choose the best hardware for their workloads—optimizing for both performance and total cost of ownership. Compared to vLLM on NVIDIA H200, MAX models on AMD MI325 match or exceed throughput parity for ShareGPT.
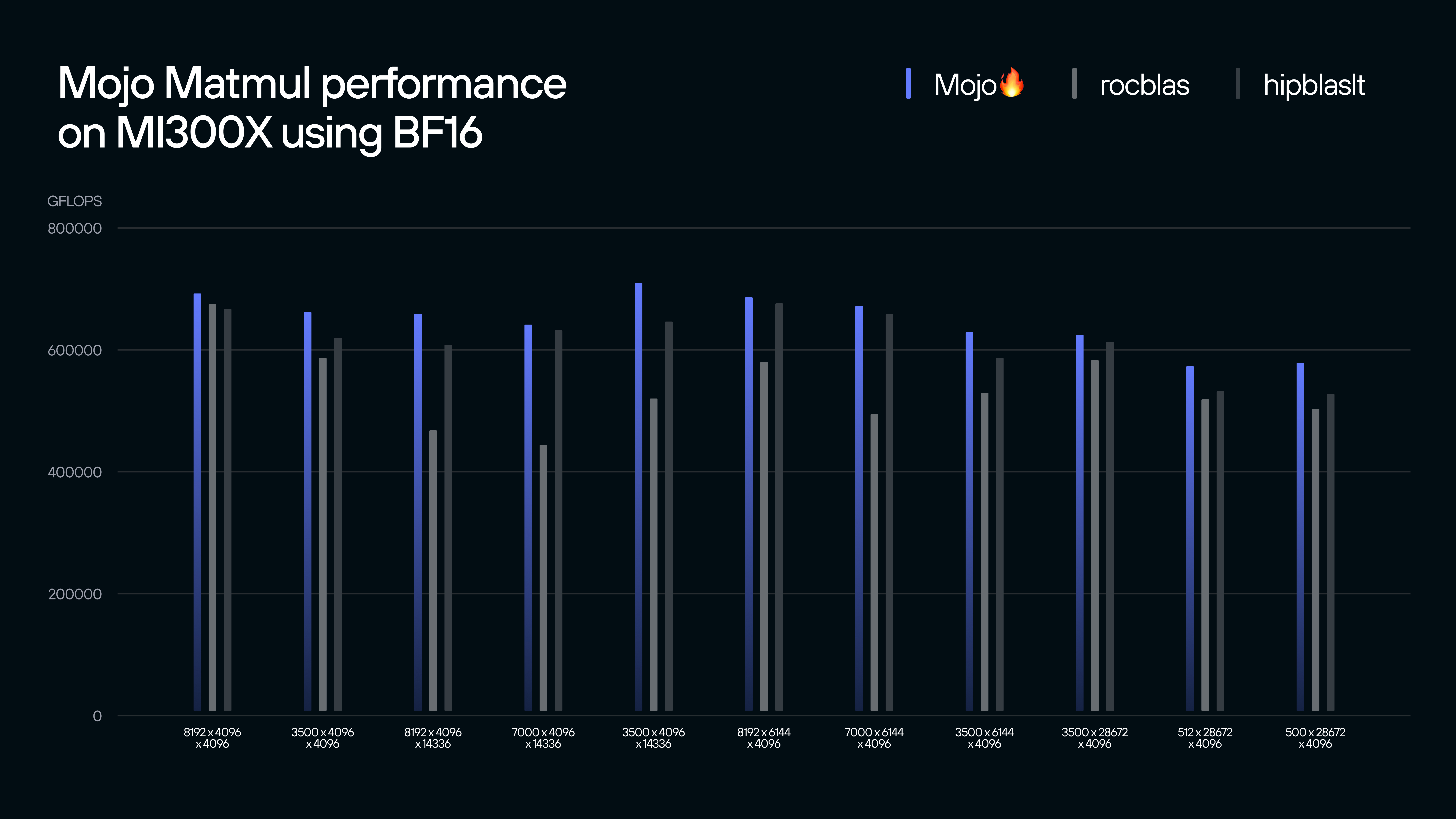
This optionality is made possible by Mojo 🔥, a Python family language designed from the ground up to easily unlock the best performance on a variety of hardware. Unlike most programming languages that are primarily targeted for CPUs, Mojo is built for the new era of heterogeneous computing across GPUs and other accelerators. Thanks to features like strong static typing, compile time meta programming, and seamless hardware dispatch, Mojo kernels are faster to write, easier to maintain, and portable across the latest hardware accelerators. For example, the Mojo kernel library implementation of matmul for BF16 outperforms equivalent hand-tuned kernels on MI300X, while maintaining portability to other hardware.
Lastly, we’re taking hardware choice even further with today’s preview launch of Mammoth—our Kubernetes-native orchestrator purpose-built for large-scale, architecture-agnostic inference. Mammoth delivers exceptional performance and operational simplicity across clusters of thousands of heterogeneous GPUs, making AI infrastructure scalable, efficient, and future-proof.
To harness the full power of the Modular Platform on AMD GPUs, download our nightly builds or pull our Docker container. To help you get started today, Modular has partnered with TensorWave to offer complimentary access to high-performance AMD datacenter GPUs—just visit modular.com/tensorwave. We can’t wait to see what you build!


