.png)

Today, we’re excited to announce a public preview of Mammoth, Modular’s Kubernetes-native platform for scalable, high-performance GenAI serving. Mammoth marks a major step in our mission to democratize AI infrastructure.
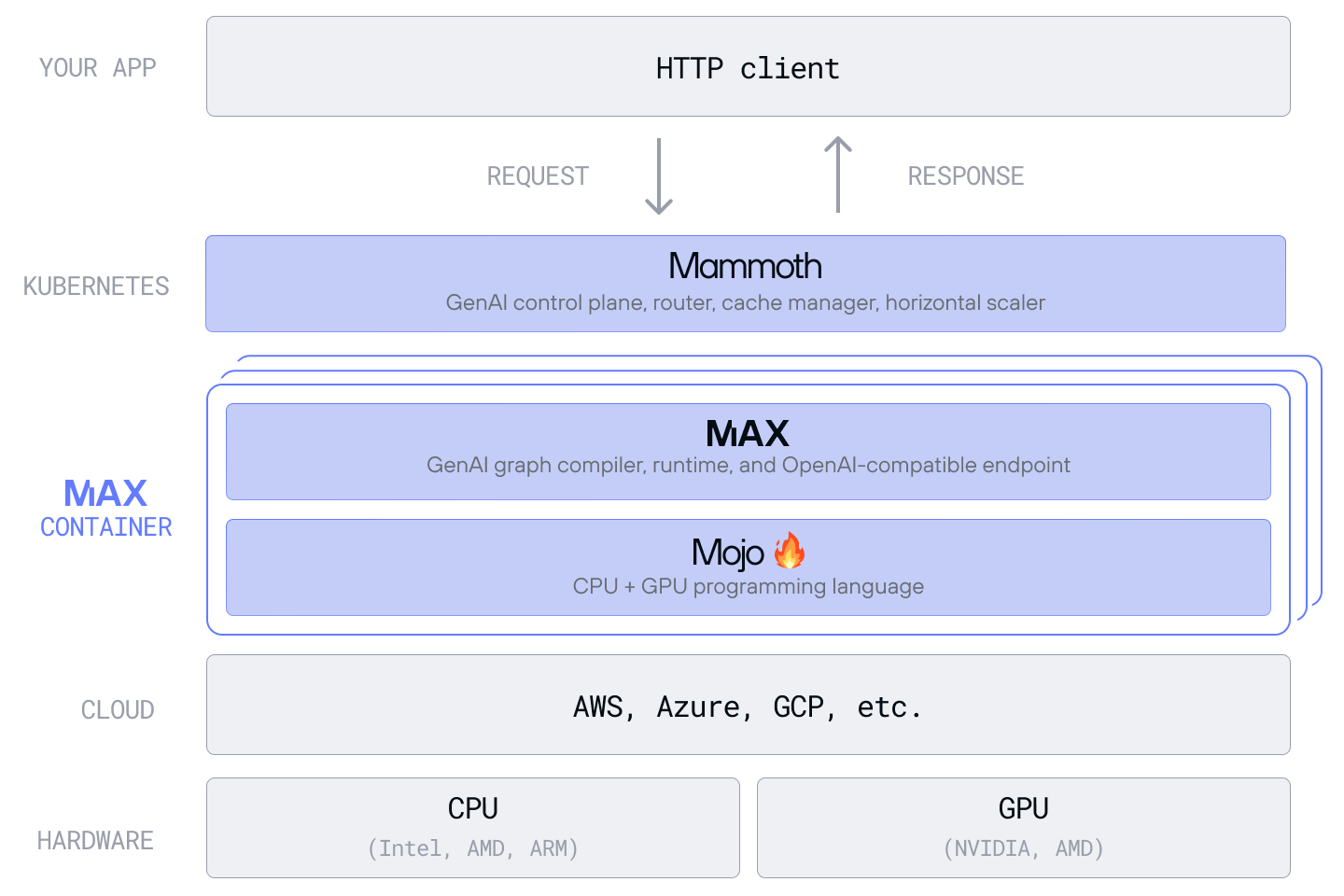
What is Mammoth?
Mammoth is a distributed AI serving tool designed for enterprise-scale deployment. It bridges the gap between models and production-grade inference infrastructure, enabling you to serve multiple models efficiently across diverse hardware—while optimizing performance, controlling costs, and reducing operational complexity.
While existing serving solutions force you to choose between simplicity and scale, Mammoth delivers both through intelligent automation and vertical integration with the MAX Platform.
Why we built Mammoth
Our journey to build Mammoth began with listening to our enterprise customers. Time and again, we heard the same frustrations:
"We can run one model well, but managing dozens of models across our infrastructure is a nightmare."
"Our GPU utilization is terrible because we can't efficiently share resources between different AI workloads."
"Our competitors ship new AI features monthly while we're stuck in multi-month deployment cycles just to get our latest models into production."
These challenges intensify as organizations move from prototypes to production AI services and from smaller to larger models. What worked in controlled demos fails at production scale with millions of users.
These issues aren't just technical inconveniences—they're fundamental barriers to AI adoption at scale. Companies are spending more time managing infrastructure than innovating. They're watching expensive GPU resources sit idle while simultaneously struggling to meet performance demands.
The industry needs a platform that abstracts away the complexity of distributed AI serving while preserving performance and hardware flexibility. Mammoth delivers exactly that—built on MAX’s unmatched speed and portability.
The power of intelligent orchestration
Mammoth’s intelligent control plane sets it apart—it acts as the brain of your AI infrastructure, automatically optimizing model placement based on performance needs, cluster state, and hardware capabilities.
Imagine you're a media company running several AI applications across a mixed GPU fleet. Your content moderation system relies on Llama models for fast text analysis during peak hours, while your video platform uses Gemma models for real-time analysis and ultra-low latency chat moderation. Meanwhile, your tagging system uses embedding models to categorize massive volumes of content, optimizing for throughput over speed.
To support these use cases, your infrastructure spans a mix of GPUs—new NVIDIA B200s and H100s, older A100s from earlier deployments, and recently added AMD MI300x and MI325x GPUs to cut costs and avoid vendor lock-in.
"Traditional approaches force you to manually configure each model for specific hardware, leading to complex deployment processes, suboptimal performance, and poor resource utilization."
Mammoth's intelligent orchestration changes this equation entirely by transforming how workloads run across your GPU fleet. It prioritizes live content analysis on your fastest GPUs during peak hours, runs moderation models efficiently on A100s, and shifts tagging to cost-effective AMD hardware. As demand shifts—like tagging ramping overnight—Mammoth automatically reallocates resources to maintain performance and maximize efficiency.
The result: every model runs on the right hardware at the right time, turning your diverse infrastructure into a unified, adaptive system optimized for price-performance and your changing business needs.
Features that matter in production
Multi-Model, Multi-Hardware Efficiency: Deploy and serve multiple models simultaneously across different hardware types without complex configuration. Mammoth handles the orchestration seamlessly.
Automatic Scaling with Intelligence: Mammoth's auto-scaling isn't just about spinning up more instances—it's about understanding your application's performance requirements and scaling in ways that maintain those guarantees while optimizing cost.
Advanced Resource Optimization: Mammoth implements disaggregated inference architecture that automatically separates workloads into specialized prefill nodes for prompt processing and decode nodes for token generation. This intelligent separation matches each inference phase to optimal hardware while automatically handling complex distributed optimizations, allowing your teams to focus on model quality rather than infrastructure tuning.
Enterprise-Grade Reliability: Built on Kubernetes with enterprise reliability patterns, Mammoth provides the fault tolerance and observability that production AI applications require.

Incredible performance benefits
Mammoth isn’t just another Kubernetes operator or serving framework. Instead of orchestrating bespoke components, Mammoth offers a vertically integrated stack—where each layer, from MAX to the Mojo programming language, works in concert to amplify performance, efficiency, and portability beyond what traditional frameworks can deliver.
Deploying through Mammoth means MAX’s compiler, scheduling, and batching optimizations are automatically tuned to your hardware and traffic, while Mammoth understands both model characteristics and cluster state, and seamlessly coordinates between inference phases. The result: multiplicative performance improvements.
In benchmarks comparing Mammoth's intelligent routing against standard load balancing approaches used with vanilla serving frameworks, we've demonstrated over 2x improved throughput for multi-turn chat scenarios.
Most importantly, Mammoth evolves with the rest of our system. As we advance serving optimizations, hardware support, and model architectures, your deployments automatically benefit—no rewrites, no manual integration. The stack upgrades seamlessly, so your AI infrastructure stays cutting-edge instead of turning into technical debt.
Get started today
Mammoth public preview is available now for organizations ready to streamline and scale their AI infrastructure.
- For AI Teams: Eliminate the complexity of multi-model deployment.
- For CTOs: Turn unpredictable AI infrastructure costs into scalable, high-ROI operations.
- For Business Leaders: Bring AI features to market faster—with less overhead and greater agility.
The future of AI infrastructure is intelligent, automated, and built for scale. With Mammoth, you're not just adapting—you're leading it.
Ready to experience Mammoth? Visit our documentation to get started with the public preview, or contact our team to discuss how Mammoth can transform your AI infrastructure strategy.


