




In late August, AMD and TensorWave reached out to collaborate on a presentation for AMD’s Media Tech Day—they asked if we could demo MAX on AMD Instinct™ MI355 on September 16th. There was just one problem: no one at Modular had access to an MI355.
That gave us just two weeks from the point we’d first have access. We saw this as an opportunity: could we achieve state-of-the-art performance on MI355 in just 2 weeks? We were confident we could, because we had spent several years building a technology platform to enable rapid AI hardware bringup.
Why AI Hardware Enablement Is Hard
Bringing new AI hardware online isn’t supposed to happen in just two weeks.
Why? The modern AI software ecosystem is fragmented. Different companies own different layers — hardware vendors are chasing silicon sales, researchers are prototyping bleeding-edge ideas, and application developers are stitching things together. The result? Complex, brittle stacks that are hard to extend and even harder to optimize.
That’s why, from day one, we built the Modular stack to make AI hardware enablement fast, consistent, and maintainable.
We often joke that the hardware is no longer the hard part — it’s the software that slows everyone down.
A Foundation Built for Portability
The Modular software stack — from Mojo (our programming language), to MAX (our inference framework) and Mammoth (our distributed serving system) — is architected for portability, meaning it can quickly move onto the latest hardware architectures and get SOTA performance.
Here’s how our design pays off:
- Architecture-agnostic design. Mojo and MAX do not hardcode GPU knowledge and optimizations. Instead, they delegate all hardware-specific details to libraries.
- Library-directed execution. Offloading, scheduling, and instruction selection are controlled through abstractions rather than hard-coded pathways in the compiler.
- Parametric operations. Instead of “magic constants” (like SIMD widths or tile shapes), we use parameterized kernels that can be retuned for new hardware.
Because 99.9% of the stack is architecture-agnostic, adding support for a new GPU mostly involves updating a few kernels. MAX and Mammoth just work — out of the box.
That design is what allowed us to move so quickly once MI355 hardware arrived. In fact, we only need to revise the parts that changed in the hardware itself. These all reside in specific kernels—so let's look at the new features in MI355.
What’s New in AMD MI355
To understand why MI355 requires only incremental kernel updates, let's examine what the MI355 architecture offers and how Modular kernels address these features:
These new hardware features in MI355 are specifically designed to optimize matmul-like operations, so that’s the only category that required changes in the Modular stack.
Two Weeks to SOTA: A Day-by-Day Story
Thanks to our stack design as described above, our work on AMD's MI355 started well before we had hardware access—we simply architected the Modular stack to enable fast hardware bringup.
With only 2 weeks until the demo, we had to be selective about what we could develop in a reasonable timeframe. While Modular moves fast, we pride ourselves on maintaining a good work-life balance—so we wanted to accomplish our goals without going into crunch mode.
Day 0: Preparing Without Hardware
Before we even touched an MI355, we began testing code generation offline. Mojo’s hardware-agnostic backend allowed us to simulate instruction paths — verifying the emitted assembly matched expectations. Try it yourself with Compiler Explorer.

By understanding the features available in the new hardware and ensuring we emit the correct instructions, we can prototype optimizations without actually running the program on the new hardware 🤯.
Day 1: First Login, First Success
On September 1st, TensorWave provisioned MI355 systems for us. We logged in, ran amd-smi, and saw the new hardware come online:
We ran pip install modular, launched a serving endpoint with MAX, and everything worked out of the box—you can do the same by following our quickstart guide.
We weren't leveraging MI355's new hardware features yet, but we could profile and identify execution bottlenecks. We also mapped our execution against an internal performance estimation tool (stay tuned for an upcoming blog post about this).
With the hardware and initial validation in hand, we could now form a plan.
Week 1: Finding the Levers
We benchmarked the MI355 GPUs against B200 GPUs, running models such as Llama, Gemma, and Mistral. We analyzed the results against theoretical upper bounds to identify optimization opportunities—we've developed tools to automate much of this analysis. The tools pointed to matmul optimization as the path to a significant performance gains and SOTA results.
The matmul implementation — only about 500 lines of well-commented code — was easy to adapt to run efficiently on MI355 hardware. We also wanted portability across AMD hardware—the same code running at SOTA on MI300, MI325, and MI355—because even with tight deadlines, we still value good software design.
After working on the matmul code for a few hours and fixing the M=N=K=8192, we proved that minor parameterization changes could deliver performance close to AMD’s hipBLASLt library (which we measured to be SOTA and faster than hipBLAS).
With a few more tweaks the same day, the Mojo matmul kernel was now 3% faster than SOTA. This day-one experiment proved our goal was achievable.
The rest of our week 1 effort included:
- Generalizing our implementation across the different shapes present in the models
- Refining our heuristics for optimal kernel parameter selection
- Setting up automation for benchmarking
- Configuring our remote login system to make compute resources easy to access and share
Of course, the first week wasn’t without some issues. We encountered delays due to hardware misconfiguration and missing GPU operators in the Kubernetes integration. Despite the setbacks, we had strong performance numbers by the end of the week and we enjoyed the weekend.
Week 2: From Optimization to Demo
We had one week to go—the demo presentation was the following Tuesday.
We continued optimizing the matmul kernel and began exploring other opportunities, such as optimizing the Attention kernel’s performance. By the middle of week 2, we had strong numbers to share with our partners.
The demo preparation was also in full swing now. The effort required that the IT department make sure we could present live benchmark results, the design department make our presentation professional, and the product team help craft the message.
Meanwhile, our engineering team continued to optimize our stack for the new hardware, using the automation we enabled in week 1 to feed live numbers to the other teams.
By Friday, MAX nightlies were running smoothly on MI355, and our benchmarks were consistently leading AMD’s custom fork of vLLM. With these results we were ready to demo on Tuesday!
💡 Fun fact: The MI355 bring-up wasn’t just fast, it was done by only two engineers working normal working hours, no late nights, and zero crunch. Turns out, great architecture scales both performance and sanity.
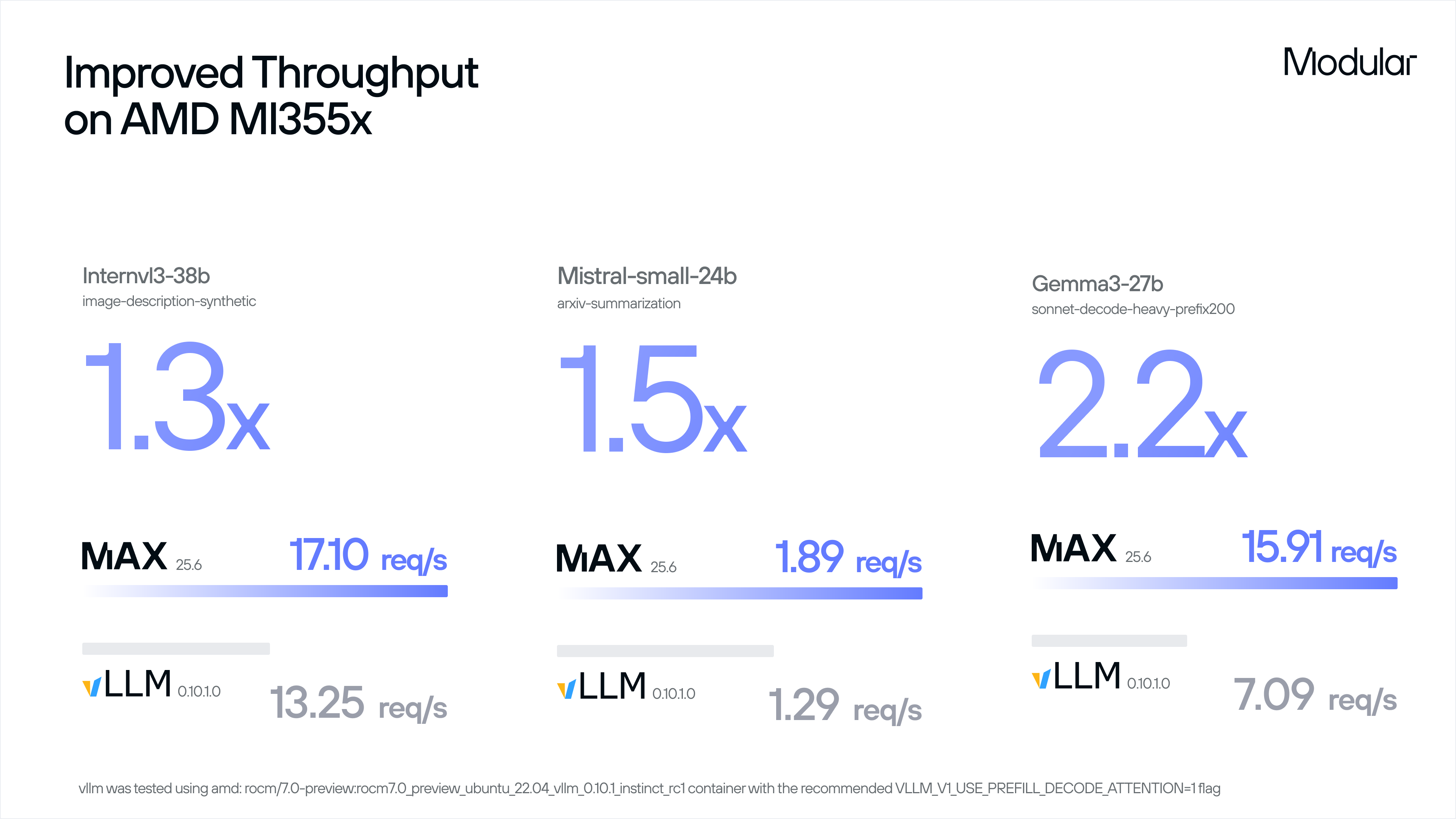
Results: Outperforming the Field
By the end of two weeks, MAX outperformed AMD’s optimized vLLM fork by up to 2.2× across multiple workloads — all while maintaining full portability across MI300, MI325, and MI355. These gains came partly from the kernels, but also from the entire stack working together to deliver both performance and portability.
Even more remarkably, the entire bring-up effort involved just two engineers working on MI355 bringup for just two weeks, one of which had a pre-planned vacation, so in reality we had 1.5 engineers working for two weeks. In total, this effort resulted in 20 small PRs and zero late nights. This is a textbook case of software architecture enabling velocity.
The performance results speak for themselves.
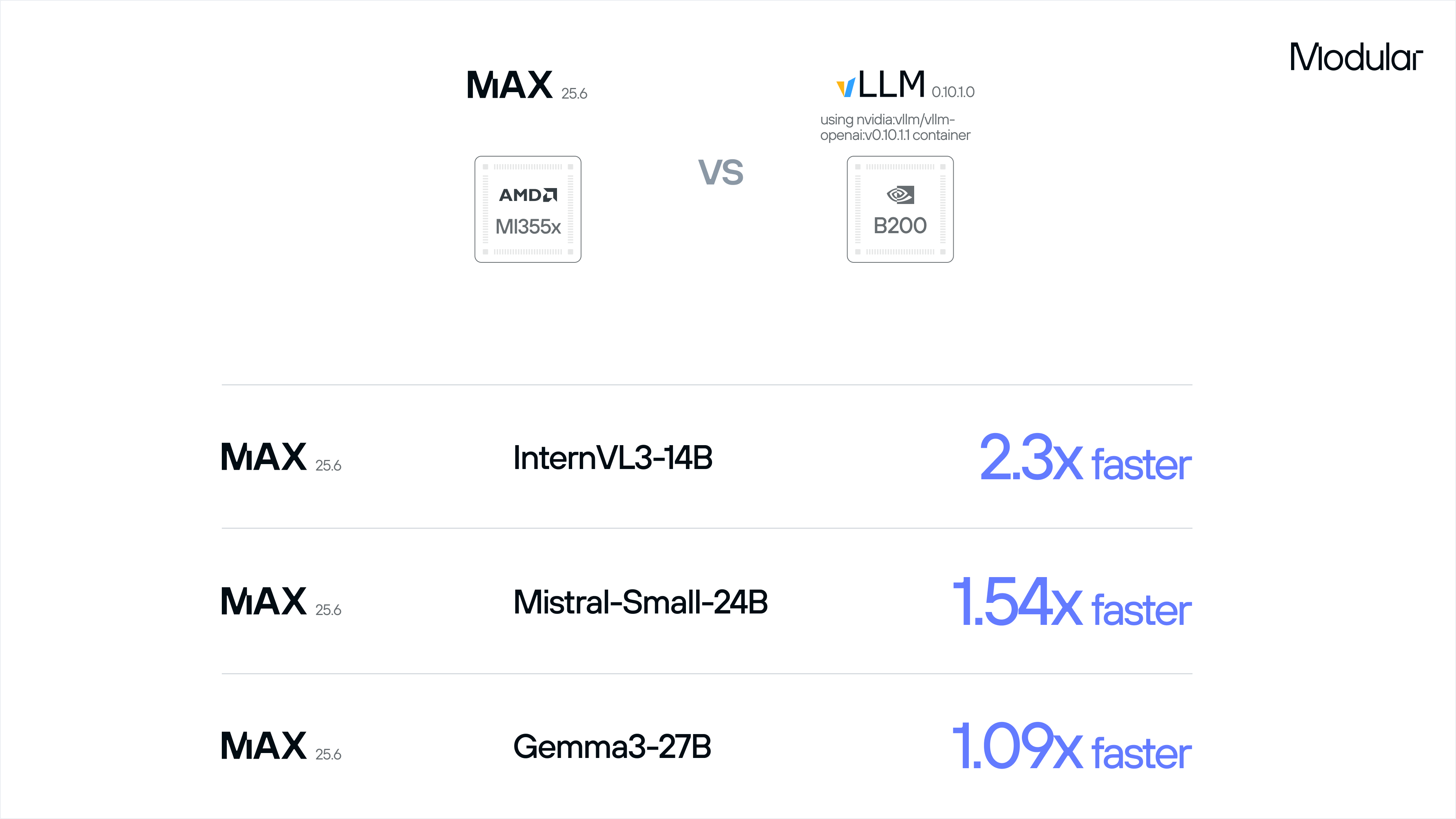
At the AMD Media Tech Day, MAX was the only inference solution to demonstrate clear TCO advantages when compared to NVIDIA’s flagship Blackwell architecture.
Are We Done? Not Even Close.
This two-week sprint was just the beginning. Since that demo, we’ve expanded MI355 support, added early Apple silicon support, and achieved state-of-the-art performance on both NVIDIA Blackwell and AMD MI355X. Check out our recent 25.6 release.
Our mission at Modular remains the same: To make AI hardware enablement fast, portable, and universal — no matter whose silicon it runs on.
Thank you to TensorWave for partnering with us as well as providing the MI355X systems and to AMD for inviting us to their Media Tech Day event.
Stay tuned for more updates — and for upcoming deep-dives on the kernel optimizations that made this milestone possible. Or feel free to reach out for a demo and we can talk about your AI use case.
Discover what Modular can do for you


