.png)

Introducing 25.6
We’re excited to announce Modular Platform 25.6 – a major milestone in our mission to build AI’s unified compute layer. With 25.6, we’re delivering the clearest proof yet of our mission: a unified compute layer that spans from laptops to the world’s most powerful datacenter GPUs. The platform now delivers:
- Peak performance on NVIDIA Blackwell (B200) GPUs: MAX achieves industry-leading throughput and latency wins, fully reproducible with our public benchmarking scripts.
- Peak performance on AMD MI355X GPUs: Modular’s performance uplift is even more pronounced on AMD’s latest MI355X GPUs - early benchmarks show MAX on MI355X can even outperform vLLM on Blackwell - and we’re not done yet!
- Developer support for Apple, AMD, and NVIDIA consumer GPUs: Developers can now use Mojo to program many consumer GPUs from AMD, NVIDIA, and - highly requested - Apple Silicon GPUs. Mojo’s unified programming model enables accessibility for a wide range of developers learning GPU programming, not just enterprises with datacenter scale accelerators.
Beyond new hardware, this release builds in countless improvements from our 25.5 release just 7 weeks ago: Developers will enjoy new pip install mojo support, enhanced VS Code support, a wide range of improvements to Mojo and MAX APIs, increased model support, and many other features covered in our changelogs (MAX🧑🚀, Mojo🔥).
Why Unified Compute? Why Now?
AI is desperate for more compute! Models are bigger, prompts are longer, reasoning is more complex, and inference demand is exploding. Datacenter construction is surging, with new “neo-clouds” emerging and governments racing to build sovereign capacity. GPU vendors like NVIDIA and AMD are accelerating product cycles – shipping yearly upgrades with more memory, bandwidth, and new datatypes (FP4, FP6, and beyond). Hardware startups are raising billions aiming to break in, while hyperscalers are designing their own silicon to secure supply and reduce dependence on third-party GPU vendors.
But hardware alone isn’t enough. Without the right software, even the most powerful hardware can’t deliver on its promise. Developers have been stuck with fragmented, inefficient stacks that make portability and peak performance elusive. Anthropic recently pulled back the curtain on the pain of juggling NVIDIA GPUs, Google TPUs, and AWS Trainium: the bottleneck isn’t FLOPs – it’s the lack of full-stack software that provides abstractions, portability, and end-to-end performance. This is a deployment and maintenance nightmare!
The industry has long sought a simple, scalable foundation for AI: a unified compute layer delivering state-of-the-art performance and portability across the most advanced hardware. With the Modular 25.6 release, that vision is now reality – a unified software layer that unifies the latest GPUs from NVIDIA, AMD, and Apple.
Deep Dives: Performance Highlights
NVIDIA B200: Incredible Performance on NVIDIA’s Best
MAX delivers industry leading performance on NVIDIA Blackwell 200s, NVIDIA’s current flagship datacenter GPU. Following our partnership with Inworld, where we delivered 2.5x throughput wins and 3.3x latency wins (time to first audio) for their state-of-the-art text-to-speech model, we’ve now optimized MAX on B200 for additional use cases:
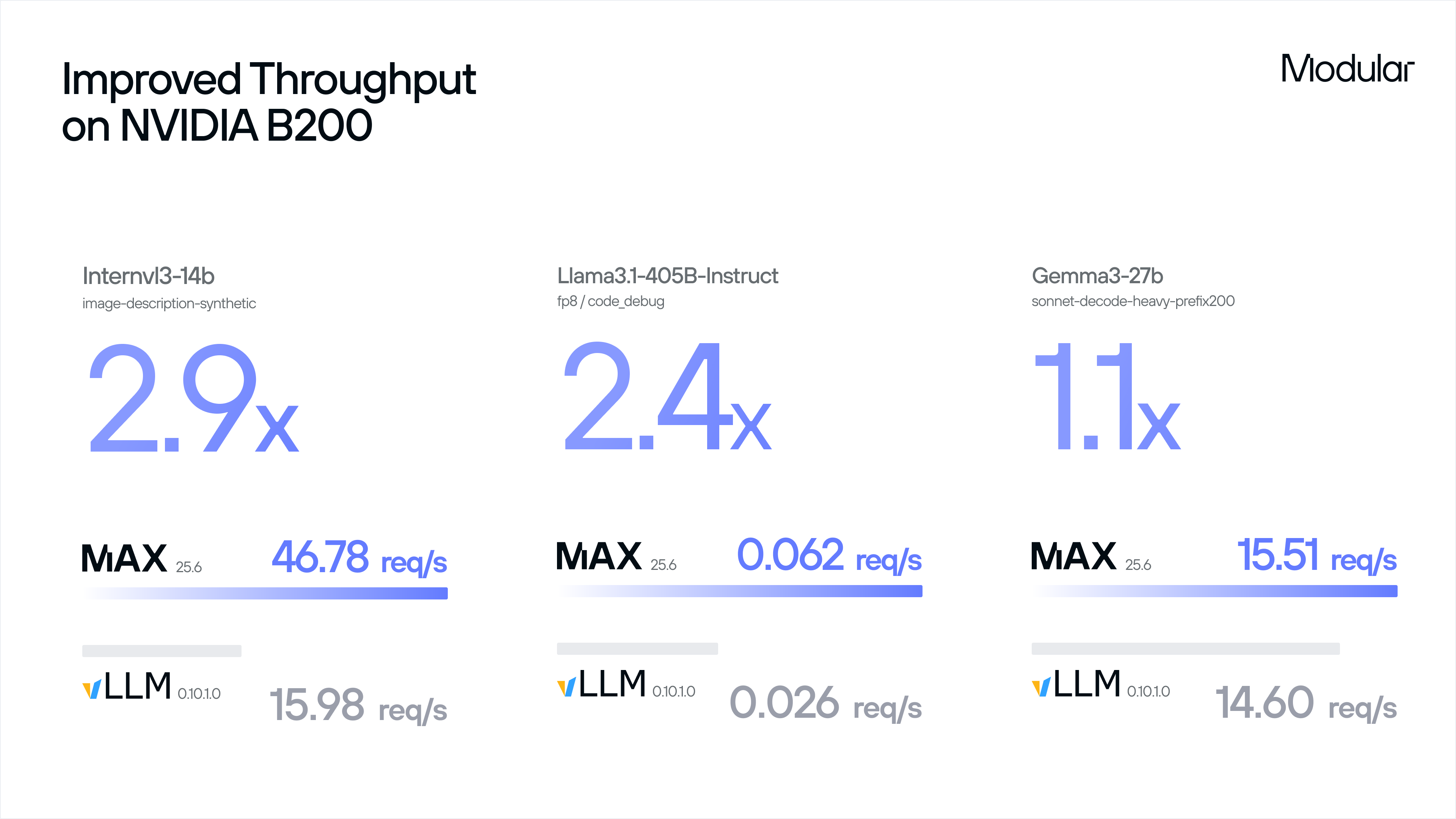
All results are fully reproducible: you can validate these numbers yourself by running our public benchmarking script on an endpoint deployed with the MAX container or pip package. To better understand how we’ve achieved these results, we’ve written a 4-part deep dive on how we were able optimize the matrix multiplication by fully utilizing Blackwell’s exotic architecture.
AMD MI355X: Head-to-Head with Blackwell
AMD has released the MI355X to go head-to-head with NVIDIA’s Blackwell – and it’s already being deployed by major cloud providers worldwide, including by our partner TensorWave. Thanks to TensorWave, we got first access to MI355X hardware on September 5th – barely two and a half weeks ago – and we’re excited to share that we’re already seeing strong results.
The obvious question is: can MI355X compete with Blackwell? Early signs point to yes. While performance always depends on the workload, MAX on MI355X delivers clear gains over vLLM on Blackwell, multiplying AMD’s existing price advantage into a significant TCO opportunity:
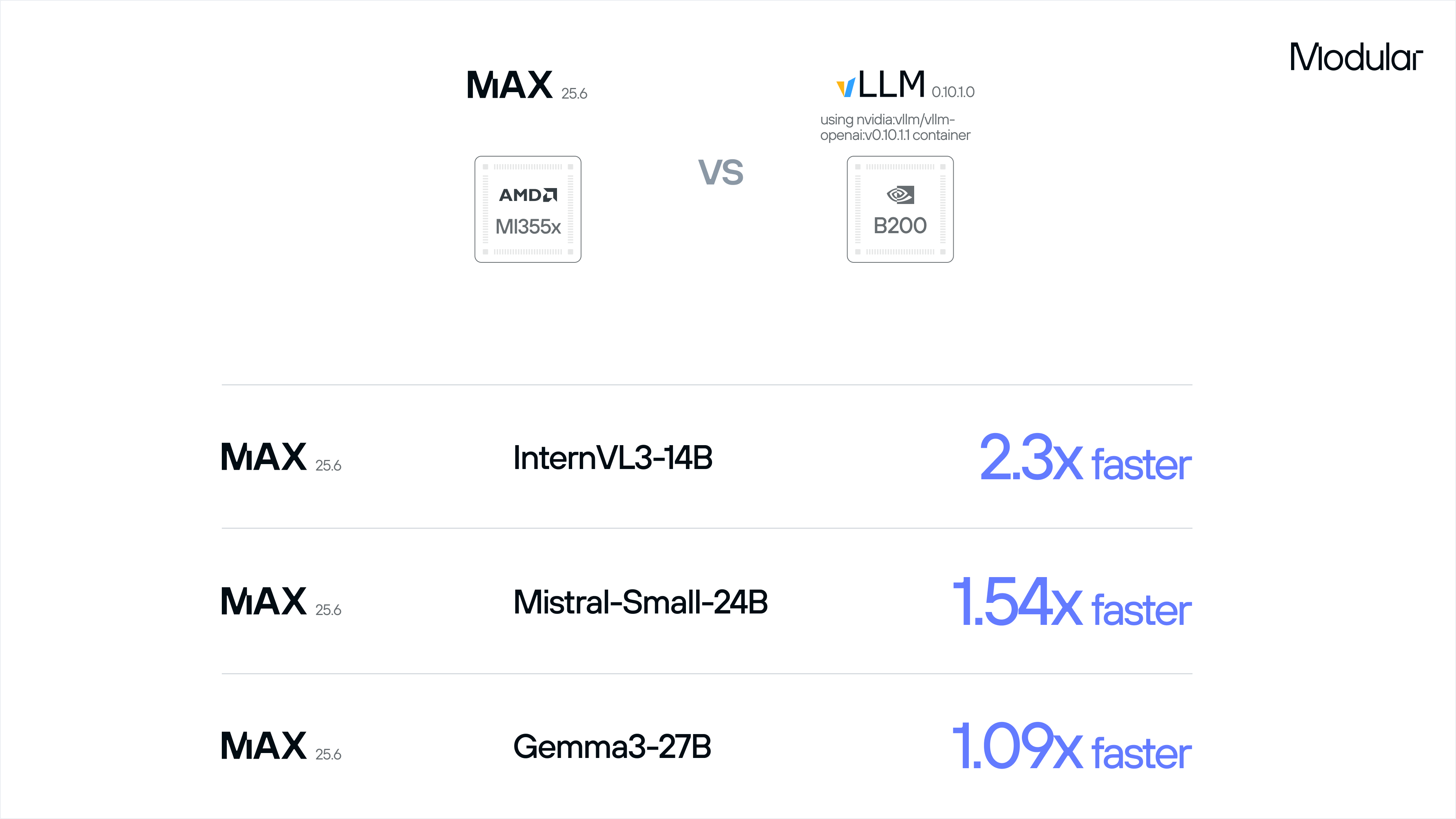
Modular achieves these performance results by bringing Modular’s advanced software to AMD’s impressive hardware. You can see this contribution more directly by comparing MAX to vLLM directly on AMD MI355X, where MAX outperforms vLLM by wide margins:
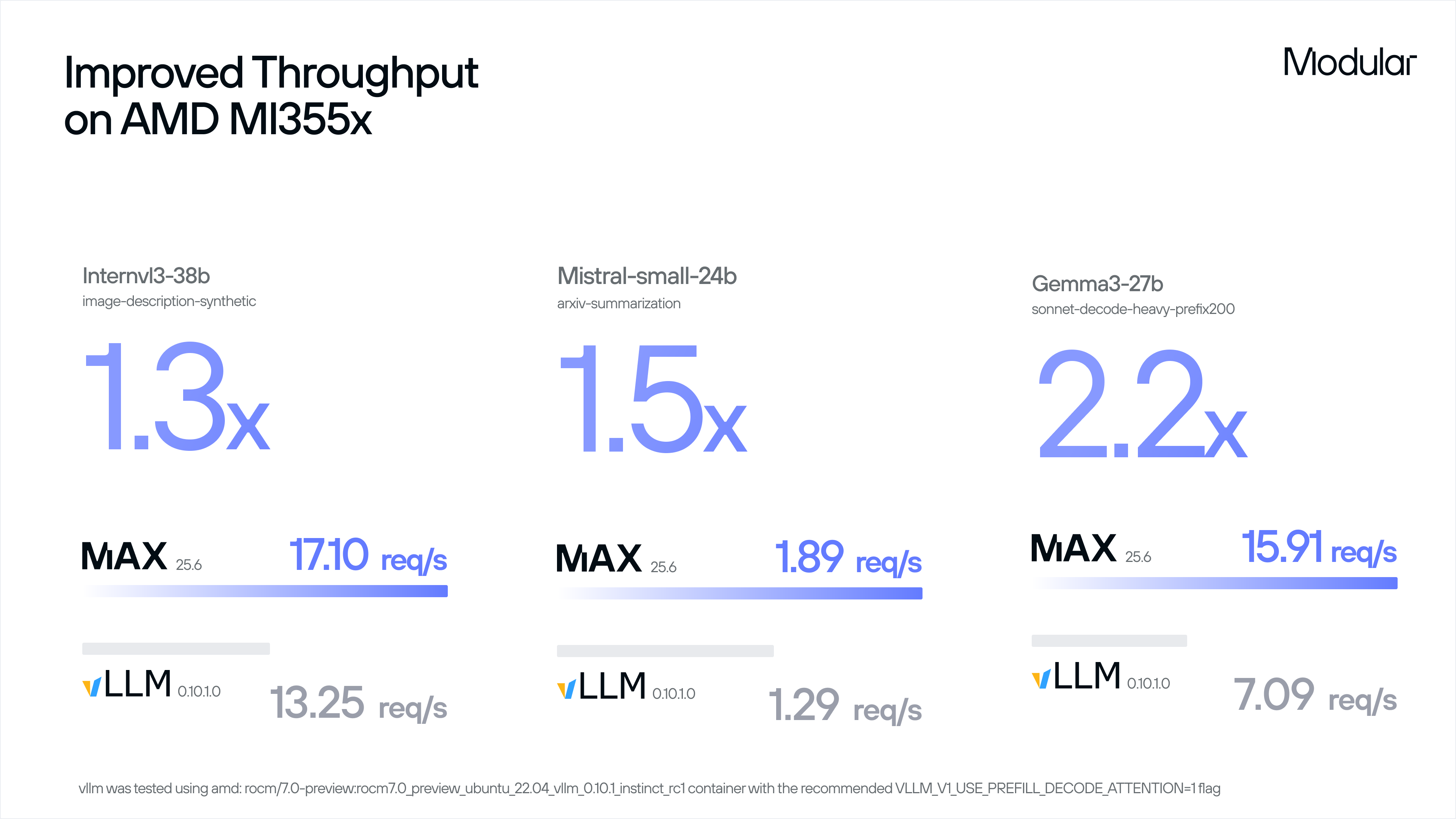
Note that Modular has only had access to this architecture for a short time - these results reflect the benefits that our portable-by-design software brings to new hardware enablement, but we expect these numbers to improve even further as we have more time with the architecture.
Getting started is simple: deploy our AMD container on an MI355X GPU. You can reproduce our results today by running our benchmarking script.
Mojo🔥 Support for Apple Silicon GPUs
Modular’s mission is to democratize AI compute, and we know that datacenter accelerators are not within reach of many developers. With 25.6, we’ve begun to break down this barrier by enabling initial support for Apple Silicon GPUs - as well as many NVIDIA and AMD consumer GPUs.
For the first time, Mac users can directly tap into laptop or desktop GPUs with Mojo and try out the first seven Mojo GPU puzzles. This step enables these GPU algorithms to run unmodified across Apple Silicon GPUs, NVIDIA Blackwell, AMD MI325X, AMD MI355X, not to mention the Hopper, Ampere, MI300 and other GPUs Modular already supports. Write once, run anywhere.
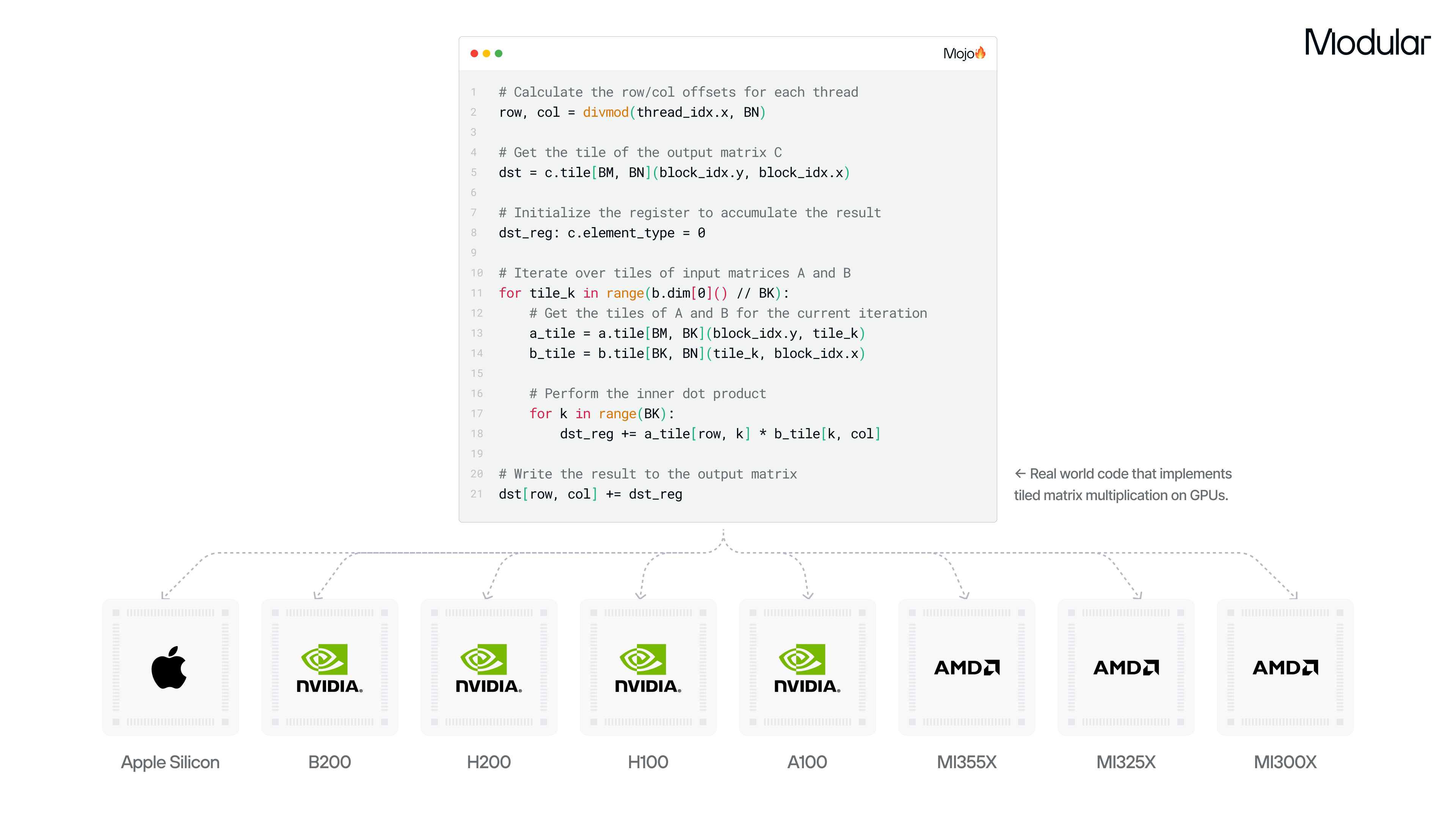
Modular’s support for Apple Silicon GPUs is evolving rapidly: we encourage developers to utilize our nightly releases, which will enable end-to-end GenAI model execution soon.
pip install mojo and a New Mojo LSP
Mojo development is now one command away: pip install mojo.
For the first time, the Mojo PyPI packages ship with the compiler, Language Server Protocol (LSP) server, and debugger all bundled together. That means developers using pip or uv get the full Mojo experience out of the box – and can even publish their own PyPI packages that depend directly on Mojo.
We’re also rolling out a significantly improved Mojo VS Code extension. It is rebuilt from the ground up to support both nightly and stable projects and deliver a more streamlined experience – it’s faster, more flexible, and completely open source! Over time, it will become even more customizable, improving life for Mojo developers whether you’re coding in VS Code, Cursor, or another IDE.
Mojo as a language has also received some exciting new capabilities, like stack traces on crashes, default methods on traits, significant extensions to the standard library, and far more.
Get started now and dig into the details!
Ready to dive into Modular 25.6? Jump right in by deploying and benchmarking a MAX endpoint using our quickstart guide. You can deploy a wide range of high-performance LLMs on NVIDIA or AMD GPUs using the MAX container. Or you can pip install Mojo and start writing code accelerated by NVIDIA, AMD, and Apple Silicon GPUs.
If you have access to NVIDIA B200 or AMD MI355X hardware, we encourage you to follow the quickstart which shows how to use our included benchmark script to validate the performance gains shown above on your own workloads. And if you're an advanced enterprise pushing the boundaries of Blackwell and MI355X, please reach out here.
For a deeper look at what’s new, a full list of changes are available in the MAX and Mojo changelogs. As always, your feedback and contributions help shape the future of the Modular platform. Join the discussion on our community forum – and come build with us in open source!


