

This guest blog post is by Ash Vardanian, founder of Unum. He's focused on building high-performance computing and storage systems as part of the open-source Unum Cloud project.
Modern CPUs have an incredible superpower: super-scalar operations, made available through single instruction, multiple data (SIMD) parallel processing. Instead of doing one operation at a time, a single core can do up to 4, 8, 16, or even 32 operations in parallel. In a way, a modern CPU is like a mini GPU, able to perform a lot of simultaneous calculations. Yet, because it’s so tricky to write parallel operations, almost all that potential remains untapped, resulting in code that only does one operation at a time
Recently, the four of us, Ash Vardanian (@ashvardanian), Evan Ovadia (@verdagon), Daniel Lemiere (@lemire), and Chris Lattner (@clattner_llvm) talked about what's holding developers back from effectively using super-scalar operations more, and how we can create better abstractions for writing optimal software for CPUs.
Here, we share what we learned from years of implementing SIMD kernels in the SimSIMD library, which currently powers vector math in dozens of Database Management Systems (DBMS) products and AI companies–with software deployed on well over 100 million devices. While the first SIMD instruction sets were defined as early as 1966, the pain points of working with SIMD have been persistent:
- High-performance computing is practically reverse-engineering of architecture details.
- Auto-vectorization is unreliable: the compiler can't reliably figure this out for us.
- SIMD instructions are complex, and even Arm is starting to look more “CISCy” than x86!
- Performance is unpredictable, even for the same instruction sets shared across different CPUs.
- Debugging is complex: there's no easy way to view the registers.
- CPU-specific code is tricky, whether it be compile-time or dynamic dispatch.
- Computation precision is inconsistent for floating point operations across different CPUs and instruction sets.
Let's explore these challenges and how Mojo helps address them by implementing one of the most trivial yet widespread operations in machine learning: cosine similarity. Cosine similarity computes how close two vectors are to one another by measuring the angle between the vectors.
Introduction to cosine similarity
You might be surprised by the widespread use of cosine similarity. Farming robots use it to zap 200,000 weeds per hour with vision-guided lasers, new ML-based methods use it for improving the speed and accuracy of climate models, and nearly every Retrieval Augmented Generation (RAG) pipeline measures the similarity of user prompts to existing knowledge bases with cosine similarity.
The following simplified diagram illustrates how RAG uses cosine similarity. A language processing ML pipeline converts text into vectors that numerically capture the meaning of words and sentences, with similar vectors sharing similar meanings. These semantically meaningful vectors are called embeddings. Cosine similarity is a way to compute the difference between embedding vectors, determining if they are semantically similar.
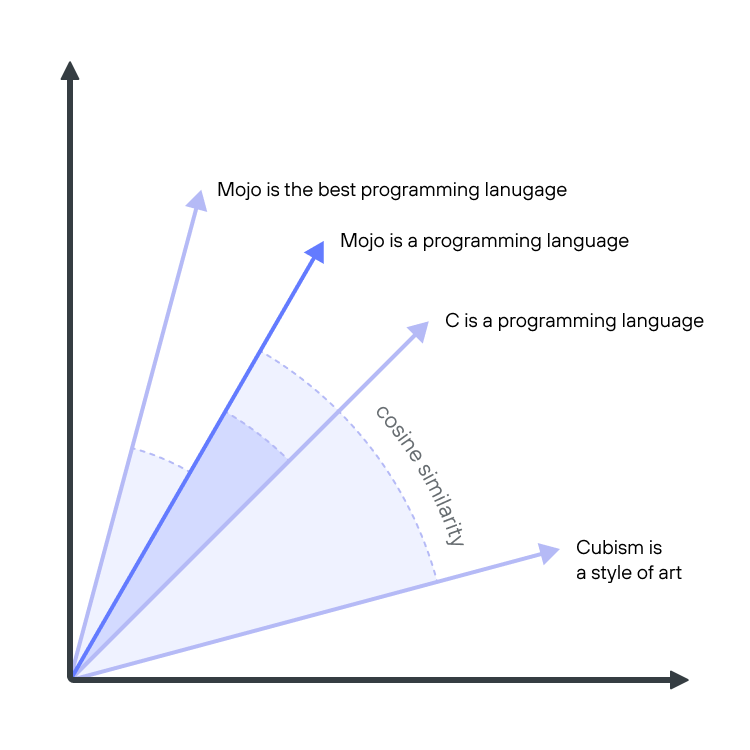
Cosine similarity can be expressed with this trivial Python code snippet, which takes the dot product of two vectors normalized by the length of the vectors:
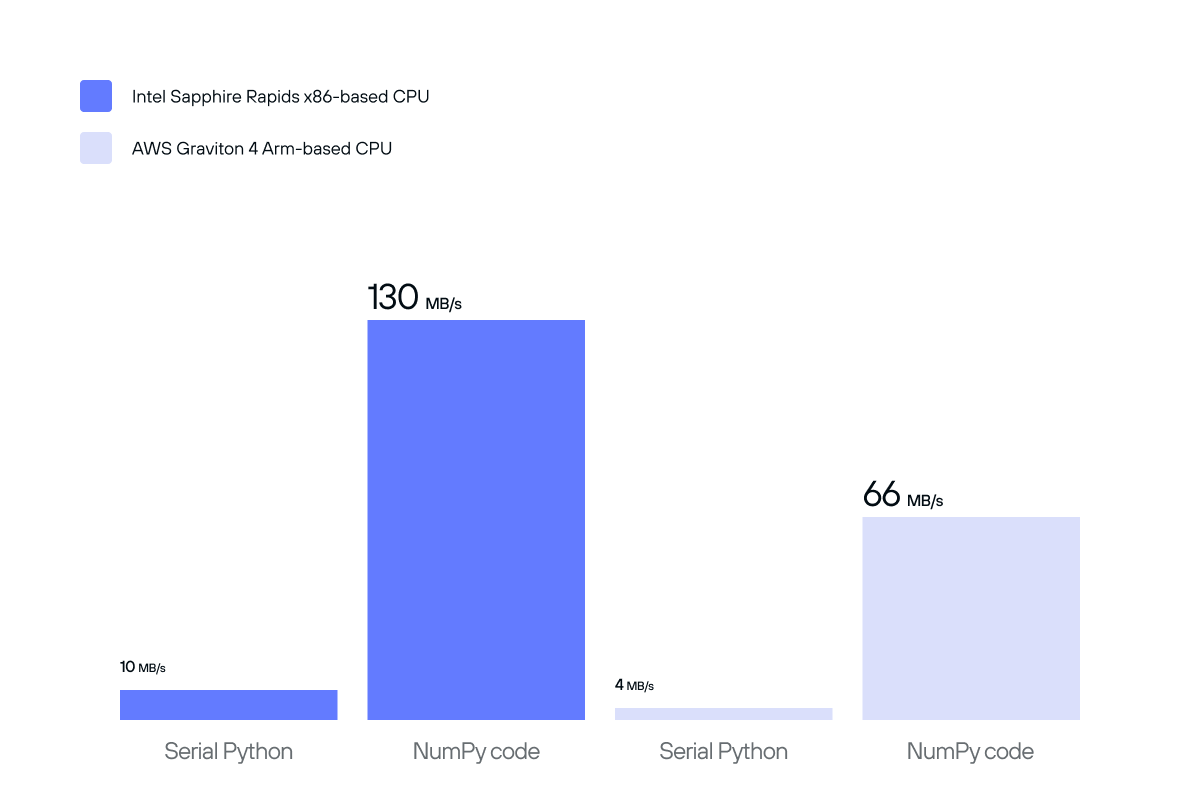
Despite this algorithm’s simplicity, we can squeeze several orders of magnitude of performance out of this code. In NumPy, the same algorithm can be implemented as follows:
The NumPy implementation illustrates a marked improvement over the naive algorithm, but we can do even better!
In the remainder of this article, we’ll implement cosine similarity using C, taking advantage of common SIMD instructions available for various CPUs. We will also write a dispatch function that chooses different algorithms depending on our CPU. Along the way, we'll discuss the intricacies and complexities of SIMD programming and how to solve them.
In Part 2 of this series, we'll show how Mojo makes it easy to write similarly performant algorithms using built-in language features, so subscribe to the RSS feed to get notified when that comes!
Mixed precision
For the remainder of this article, we'll be using the most common numeric type in Machine Learning these days, the bfloat16 type.
bfloat16 is a 16-bit floating point number type with a much smaller range and precision than the IEEE-standard float32 type, making it much faster to compute with. It's also different from the IEEE-standard float16 type.
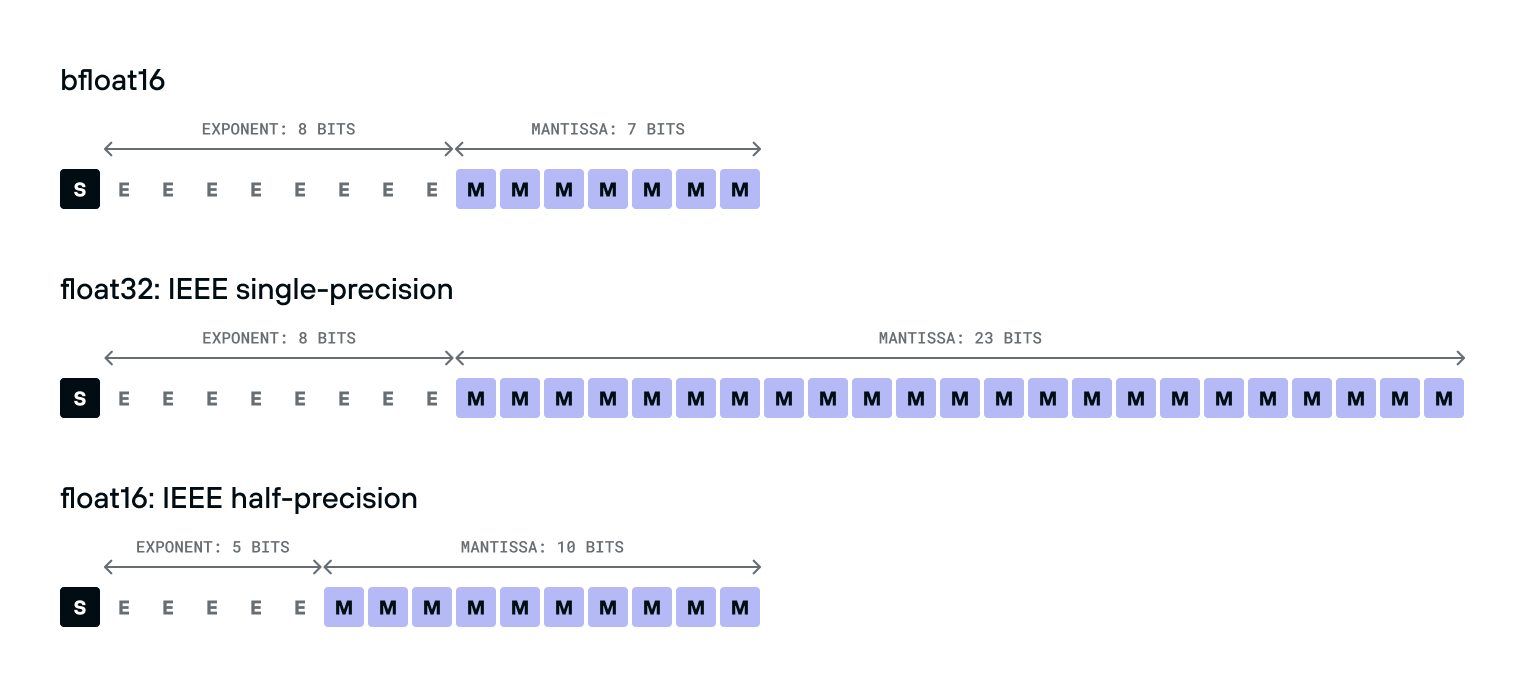
Surprising to many, the bfloat16 is much easier to convert to and from float32 than float16 is -- it's just a single bit shift, because its exponent takes the same number of bits. This makes it much easier to use in practice, even on older hardware without native support: just shift to convert it to a float32, use a float32 instruction, and shift to convert it back.
But as much as we like bfloat16, we shouldn't use it exclusively. The imprecision introduced by the type can compound quickly leading to wildly inaccurate results. To address this, we can mix different numeric types in the same computation.
For example, we could use bfloat16 for the vectors, multiply into float32 accumulators, and upcast further to float64 for the final normalization. In C++23 it would look like this:
Unfortunately, there are several issues with this code.
First, the C++ standard doesn't require those types to be defined, so not every compiler will have them. Portable code with these faster data types generally requires more effort.
Second, it's well known that even in data-parallel code like this, compilers have a hard time vectorizing low-precision code, sometimes leaving as much as 99% of single-core performance on the table, and with mixed precision it's even worse! One needs to be explicit if they want reliable data parallelism.
Lastly, double-precision division, combined with a bit-accurate std::sqrt implementation, introduces several code branches and a lot of latency for small inputs. We can avoid these by using faster instructions.
To solve these problems, let's use rsqrt reciprocal square root (1/√x) approximations, and explicitly use SIMD intrinsics to accelerate this code for every common target platform.
Let's start by looking at some C 99 cross-platform kernels from my SimSIMD library.
Baseline implementation for Intel Haswell
Intel Haswell and newer generations of x86 CPUs all support AVX2, which is a 256-bit SIMD instruction set for the 32 new YMM register files on the CPU. This allows us to do 8 simultaneous float32 operations at a time.
Here's roughly what our above kernel would look like, specialized for AVX2 hardware.
We'll implement the TODO blocks later below, but you can also see the completed simsimd_cos_bf16_haswell implementation in simsimd/spatial.h.
This loop does three main things.
First, it uses _mm_loadu_si128 to load 128 bits from a potentially unaligned memory address. One should be careful to use this instead of _mm_load_si128 which crashes if the address of the vector is not divisible by 16, which is the XMM register size in bytes.
Second, it uses _simsimd_bf16x8_to_f32x8_haswell to convert from bfloat16 to float32. It interprets the input as 8 16-bit integers and converts them to 32-bit integers, and then shift them left by 16 bits:
Third, we use _mm256_fmadd_ps to accumulate our dot product into ab_vec's 8 scalars by multiplying a_vec's 8 words with b_vec's 8 words. This is a fused multiply-add (FMA) instruction, which is faster than multiplying and adding numbers individually:
For most of those instructions and CPU core designs, two such operations can be performed simultaneously. We call FMA three times in each cycle. Once for the actual dot product and twice to accumulate "squared norms" into a2_vec and b2_vec.
After the loop, we'll need to horizontally accumulate, which means add the 8 words of ab_vec together to get one single number. Let's talk about how!
Reducing horizontal accumulation
A tricky part of SIMD in practice is to avoid horizontal accumulation of the entire register, because it’s a slow operation.
Whenever possible, accumulation should be placed outside of the loop, which generally requires some intra-register shuffling for a tree-like reduction.
For example, _simsimd_reduce_f32x8_haswell may look like this under the hood:
In our function, we'll use it like this:
Now, we have:
- A single
abnumber, the dot product ofaandb. - A single
a2number, the dot product ofawith itself, the "squared norm" of `a`. - A similar squared norm of `b`.
Reciprocal square root approximation in AVX2
Our function's last line will be this:
It will need to do the dot product of a and b, divided by the normalized a and the normalized b, like this pseudocode:
That's right: to normalize the result, not one, but two square roots are required.
We'll use the _mm_rsqrt_ps instruction. It's not available for double-precision floats, but it's still a great choice for single-precision floats. Our function would look something like this:
However, the _mm_rsqrt_ps instruction can introduce errors as high as 1.5*2^-12, as documented by Intel.
A great 2009 article Timing Square Root comparing the accuracy and speed of the native rsqrt instruction (present in SSE and newer x86 SIMD instruction sets) with John Carmack's fast inverse square root mentions using a Newton-Raphson iteration as an alternative to improve numerical accuracy, and we'll do something similar here to improve our algorithm:
One must keep in mind, various CPUs' rsqrt instructions will have different performance and accuracy. After we finish our simsimd_cos_bf16_haswell function, we'll see how this compares to AVX-512 further below.
Partial Loads
There's still an assumption we have to fix, inside our loop:
Potentially the ugliest part of this and many other production SIMD codebases is the "partial load" logic.
It's a natural consequence of slicing variable-length data into fixed-register-length chunks.
Because of this, almost every kernel has the "main loop" and a "tail loop" for the last few elements.
Prior to AVX-512 on x86 and SVE on Arm, there was no way to load a partial register, so the code has to be a bit more complex.
In Part 2, we'll talk about how Mojo solves this problem. But for now, we'll handle it manually by adding this inside the loop:
That's it! Here's the complete function below. And as a bonus, we changed the while loop to a goto because that's just how I roll. Oftentimes, goto usage is discouraged in modern codebases, but in small functions they don’t convolute the control flow and can help reason about code in a more machine-accurate way. CPU’s don’t have for loops after all. Moreover, this way we avoid code duplication for the primary logic instead of repeating it twice in the main loop and the tail.
You can also see simsimd_cos_bf16_haswell live, in simsimd/spatial.h.
Now we are done with one of the most "vanilla" kernels in SimSIMD. It targets broadly available CPUs starting with Intel Haswell, shipped from 2013 onwards. It is forward-compatible with 11 years of x86 hardware, performing mixed-precision operations in bf16-f32-f64, including numeric types not natively supported by hardware. This is a good warmup, but the most exciting parts of SimSIMD, and the reason it runs on hundreds of millions of devices, are still ahead!
Baseline implementation for AMD Genoa
Let's kick it up a notch, and bring in AVX-512, which is a 512-bit SIMD instruction set for the 32 new ZMM register files on the CPU. AMD Genoa is the first AMD CPU to support it, and it's also the earliest publicly available CPU with AVX512_BF16 "extension of extension" for the bfloat16 type, including the vdpbf16ps instruction for dot products.
Before we show the masking and the vdpbf16ps parts, here's roughly what our simsimd_cos_bf16_genoa will look like:
Structurally, the kernel is similar, but the loop step size grew from 8 to 32, and even bigger changes are hiding behind those TODOs.
You may have noticed that a_i16_vec and b_i16_vec are represented with __m512i, as opposed to the bfloat16 vector type __m512bh. This is caused by incomplete support for loadu intrinsics, missing a bfloat16 overload in some compilers.
Now, let's resolve those TODOs, starting with the masked loads.
Masking in x86 AVX-512
AVX-512 was the first SIMD instruction set to introduce masking, which is a way to partially execute instructions based on a mask. For example, if you have a register containing 8 words/scalars, you can use a mask to increment only 5 of them.
Each core contains not only 32 ZMM registers, but also 8 KMASK registers, which can be used to control the execution of instructions. Think of them as 8 additional normal scalar registers, containing 8, 16, 32, or 64 bits. Moving between those and general-purpose registers isn't free, but using them for masking is still better than branching.
Interleaving, testing, and merging masks with each other is also natively supported with these special mask manipulation instructions:
When using SIMD, it can be easy to accidentally load past the end of the array, since we're loading in chunks, and the array might not be a multiple of our vector size. To avoid that, we'll do some masking to partially load from a and b in the last iteration. Our if-else looks like this now:
Dot products with vdpbf16ps
Let's resolve this TODO now:
Previously, in our simsimd_cos_bf16_haswell kernel, we added 8 input bfloat16s to ab_vec etc. with this code:
ab_vec is 512 bits wide, and holds 16 bfloat32s. You might think that we would now add 16 input bfloat16s to it, but it's even better than that: the vdpbf16ps processes 32 input numbers into our 16-word ab_vec. It takes the dot product of the first two words of each input, and add their dot-products to the first word of the result (like ab_vec[0] += a[0] * b[0] + a[1] * b[1]), and then it does that for the rest of the words as well.
We'll use the _mm512_dpbf16_ps function to do this instruction, and add this to our loop:
Here's the full function:
Now let's implement that _simsimd_cos_normalize_f64_skylake call at the end!
Reciprocal square root approximation for AVX-512
We need to conceptually calculate ab / (sqrt(a2) * sqrt(b2)).
In our _simsimd_cos_normalize_f64_haswell function from before, we used the rsqrtps instruction (via the _mm_rsqrt_ps intrinsic) to calculate our reciprocal square root. In AVX-512, those are superseded by the _mm512_rsqrt14_ps intrinsic and vrsqrt14ps instruction.
And fortunately, the maximum error bound improved from 1.5*2^-12 to 2^-14.
There is also a double-precision instruction vrsqrt14pd (via the _mm512_rsqrt14_pd intrinsic).
It has the same precision, but we can avoid casting.
A natural question may be: how important is this Newton-Raphson iteration?
As you can see, it reduces our relative error by a lot. On 1536-dimensional inputs, the impact is as big as 2-3 orders of magnitude!
Keep this impact in mind. In a little bit, we'll see the error rate for Arm NEON's rsqrt instruction, and just how necessary it is to stay on top of our floating point precision for specific CPUs.
This is also why abstraction can be difficult and/or counterproductive when dealing with SIMD. The entire shape of the algorithm (such as whether we do a Newton-Raphson iteration) can change depending on the CPU or the precision of its instructions.
Baseline implementation for Arm NEON
Most CPUs aren't running x86, but Arm. Apple alone today accounts for 2.2 billion devices, and almost all of them run on Arm. Arm devices also have a SIMD instruction set, called NEON, which is similar to SSE, also with 128-bit registers.
You may be wondering, what happened to our ab_vec, and what are these ab_high_vec and ab_low_vec things?
These, my friends, are a perfect example of my next point.
CISC vs RISC, it's not what people say
The Arm instruction set is often called RISC (Reduced Instruction Set Computer), and the x86 instruction set is often called CISC (Complex Instruction Set Computer).
But in practice, the Arm instruction set is potentially more complex, especially given that all of those instructions practically apply only to 64-bit and 128-bit registers, as opposed to the x86 instructions which also include 256-bit and 512-bit registers!
Here is an example.
Before discovering the vbfdotq_f32 intrinsic (suggested by Mark Reed), SimSIMD used the vbfmmlaq_f32 and vbfmmlaq_f32 intrinsics to compute the dot product of two vectors.
It's also a Fused Multiply-Add instruction, but designed to take only odd or even components of the vectors, so we aggregate them differently:
In other words, ab_high_vec contains only the even components, and ab_low_vec contains only the odd components.
This instruction probably makes more sense for complex dot-products, where we might want to load only the real words or only the imaginary words from a vector of complex numbers.
As for the cosine distance, there is one more non-obvious approach previously tested in SimSIMD.
NEON contains a BFMMLA instruction:
Doesn't look very RISCy to me! But at some point it looked promising. Concatenating vectors \(a\) and \(b\) into a matrix \(X\) and computing the dot product \(X^T X\) in a single instruction is a great idea. It will contain 4 dot products, and we can drop 1 of them, keeping 3 products: \(a \cdot b\), \(a \cdot a\), and \(b \cdot b\), all needed for cosine similarity. That kernel may look similar to this:
Unfortunately, this approach ended up being 25% slower than the naive approach.
When dealing with x86 ISA, if you find a weird rare instruction that can be used in your program, it's often a good idea to apply it.
In Arm it doesn't help most of the time, so in my opinion, Arm is more CISCy than x86.
This is also why it's important to have CPU-specific code, rather than relying on coarse abstractions that just use whatever instruction is present.
Reverse engineering Arm accuracy
Similar to x86, the rsqrt instruction is available in NEON, but only for single-precision floats.
Unlike x86, the documentation is limited:
1. We can't know the latency of the instruction.
2. We are not even informed of the maximum relative error.
The first can be vaguely justified by the fact that Arm doesn't produce its chips, it licenses the designs to other companies. Still, a repository of timings for different chips would be very helpful. Second is just a mystery. Until you reverse engineer it!
I wrote this benchmark program, which estimates the accuracy of rsqrt approximations in Arm NEON, SSE, AVX2, and AVX-512.
Luckily, it's only 4 billion unique inputs to test, just a few seconds on a modern CPU.
Baseline implementation for Arm SVE
Arm SVE is unusual.
It's not the first to support masking, like AVX-512.
But it is the first to define variable-width implementation-defined registers, which can be 128, 256, 512, 1024, or 2048 bits wide.
That means that on one CPU, a svbfloat16_t might be 128 bits wide (8 bfloat16s) and on another CPU it might be 1024 bits wide (fitting 64 bfloat16s), yet the compiled program is the same. One can only know their width at run-time by calling the svcnth function, which tells us how many 16-bit words fit in a SVE vector on this CPU.
At the end of this spectrum (2048 bits) the CPUs are practically converging with GPUs, but despite that, all real implementations are 128-bit wide.
This is what a kernel may look like:
This is another reason it's important to have CPU-specific code, and to not rely too heavily on abstractions: some architectures are very unusual.
Masking in Arm SVE
Seeing “variable-width implementation-defined registers” you may ask yourself, how does the final iteration of the loop handle the remainder of the elements, if they don't fill up an entire vector? In SVE, the recommended approach is to use “progress masks” (like that progress_vec) and build them using “while less than” intrinsics (like that svwhilelt_b16). It’s a more powerful alternative to _bzhi_u32 that we’ve used for AVX-512 tails.
Adding up the performance gains
Taking a look back at all of the hardware-specific optimizations, we can see an orders-of-magnitude improvement over our initial naive implementation and stock NumPy implementation. Utilizing and exploiting hardware features has delivered performance boosts from 10 MB/s to 60.3 GB/s on Intel hardware, and 4 MB/s to 29.7 GB/s on Arm hardware. It underscores the absolute importance that specialized hardware acceleration libraries have on even the simplest of computational algorithms.
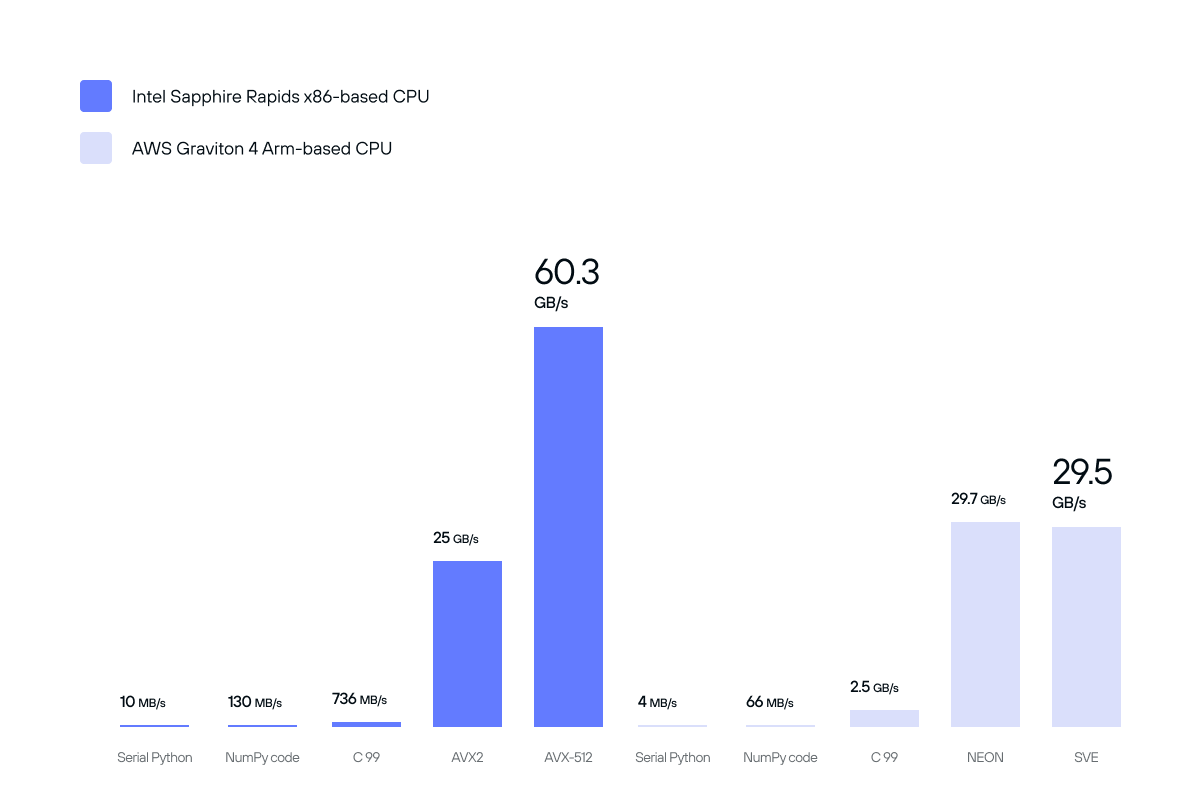
Packaging and distributing libraries
Throughout this post, I've mentioned a few times that CPU-specific code is important. But shipping CPU-specific code correctly can be tricky.
The easiest and fastest approach is just to compile for a specific hardware platform. With -march=native, for example, your compiler will compile the code assuming the target machine that will run this software supports all the same Assembly instructions as this one. We can implement several kernels for different platforms and select the best backend at compile time.
But if we don't know the target machine ahead of time, we'll want to ship multiple optimized kernels for every function in one binary, and differentiate at runtime. When the program starts, it checks the model or the capabilities of the current CPU, and selects the right implementation. It’s generally called “dynamic dispatch”. To implement it, on x86, we call the CPUID instruction to query several feature registers:
This code uses inline Assembly, when compiled with Clang and GCC. Microsoft Visual Studio Compiler doesn’t support inline assembly, but provides an intrinsic to compensate for that.
Once the feature flags are queried, they must be unpacked and used to select the right kernel implementation for every combination of input argument types and CPU capabilities. In my other library StringZilla (which has a much smaller collection of defined string operations), that’s done at a function-level individually. But in SimSIMD, which already has over 350 kernels and is rapidly growing, all the kernels are grouped into several categories for different generations of CPUs, like “Haswell” and “Ice Lake” for Intel or “Genoa” for AMD. It was a simpler and more future-proof design to dispatch to dozens of similar kernels given the fragmentation of the x86_64 ISA:
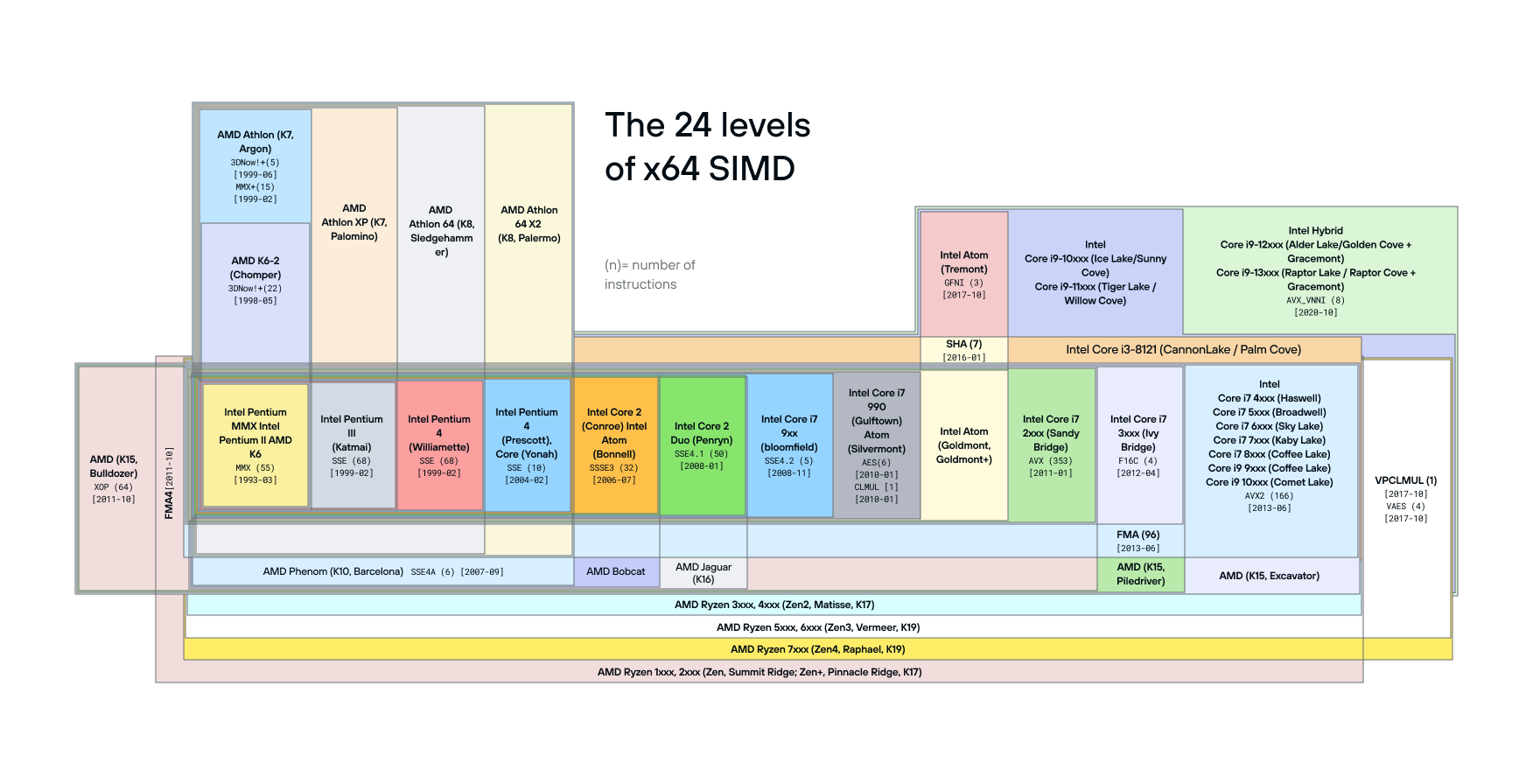
In other words, instead of having a separate implementation for every one of dozens of x86 core designs across Intel, AMD, and Centurion, SimSIMD selects several “capability levels” named after the first server-side CPU line-up that supports a specific family of instructions: Sapphire Rapids for AVX512-FP16, Genoa for AVX-512BF16, Ice Lake for VNNI/VBMI and other AVX-512 integer-processing instructions, Skylake-X for basic AVX-512 support, Haswell for AVX2, F16C, and FMA, etc.
The next step is to map supported CPU features into our “capability levels”:
This approach won't work on Arm. On Arm and Linux, again we can query CPU registers, but on Apple devices we must query the OS. The process is no less convoluted than with x86.
Feature resolution (like the CPUID above) is great, but it can be slow, sometimes even up to 300 CPU cycles. So you should only do it once, and cache the list of available CPU capabilities.
Conclusion
As you can see, SIMD is full of challenges! And keep in mind, this is just one simple case of us calculating a cosine distance.
But it's worth it. When one navigates the hurdles and harnesses SIMD correctly, it unlocks incredible performance, often an order of magnitude higher than naive serial code.
I hope you enjoyed this whirlwind tour of SIMD’s complexities! It was quite long, but we didn’t even try analyzing port utilization for different families of instructions on x86. We haven’t looked into SME and streaming SVE modes for recent arm cores. We didn’t study the CPU frequency scaling license, even though many of those aspects are already covered by SimSIMD kernels running under the hood of your favorite data products. So much is still ahead!
In Part 2, we'll talk about how Mojo helps with a lot of these problems! Ping me (@ashvardanian) or anyone related (@verdagon, @lemire, @clattner_llvm) if you have any questions, and join the Modular Discord server if you have special requests for Part 2!


