.png)

We're excited to announce Modular Platform 25.4, a major release that brings the full power of AMD GPUs to our entire platform. This release marks a major leap toward democratizing access to high-performance AI by enabling seamless portability to AMD GPUs. Developers can now build and deploy models optimized for peak performance, with zero reliance on any single hardware vendor—unlocking greater flexibility, lower costs, and broader access to compute.
🚀 AMD GPUs now officially supported
The headline feature of 25.4 is official support for AMD GPUs, backed by our newly announced partnership with AMD. You can now deploy Modular with full acceleration on AMD MI300X and MI325X GPUs using the exact same code and container as NVIDIA, with zero changes or workflow tweaks. For the first time, enterprises can build portable, high-performance GenAI deployments that run on any platform without vendor lock-in or platform-specific optimizations.
Compared to existing infrastructure, Modular delivers substantial performance gains on AMD GPUs with popular LLM workloads—achieving competitive results even when compared with running the same workloads on NVIDIA GPUs:
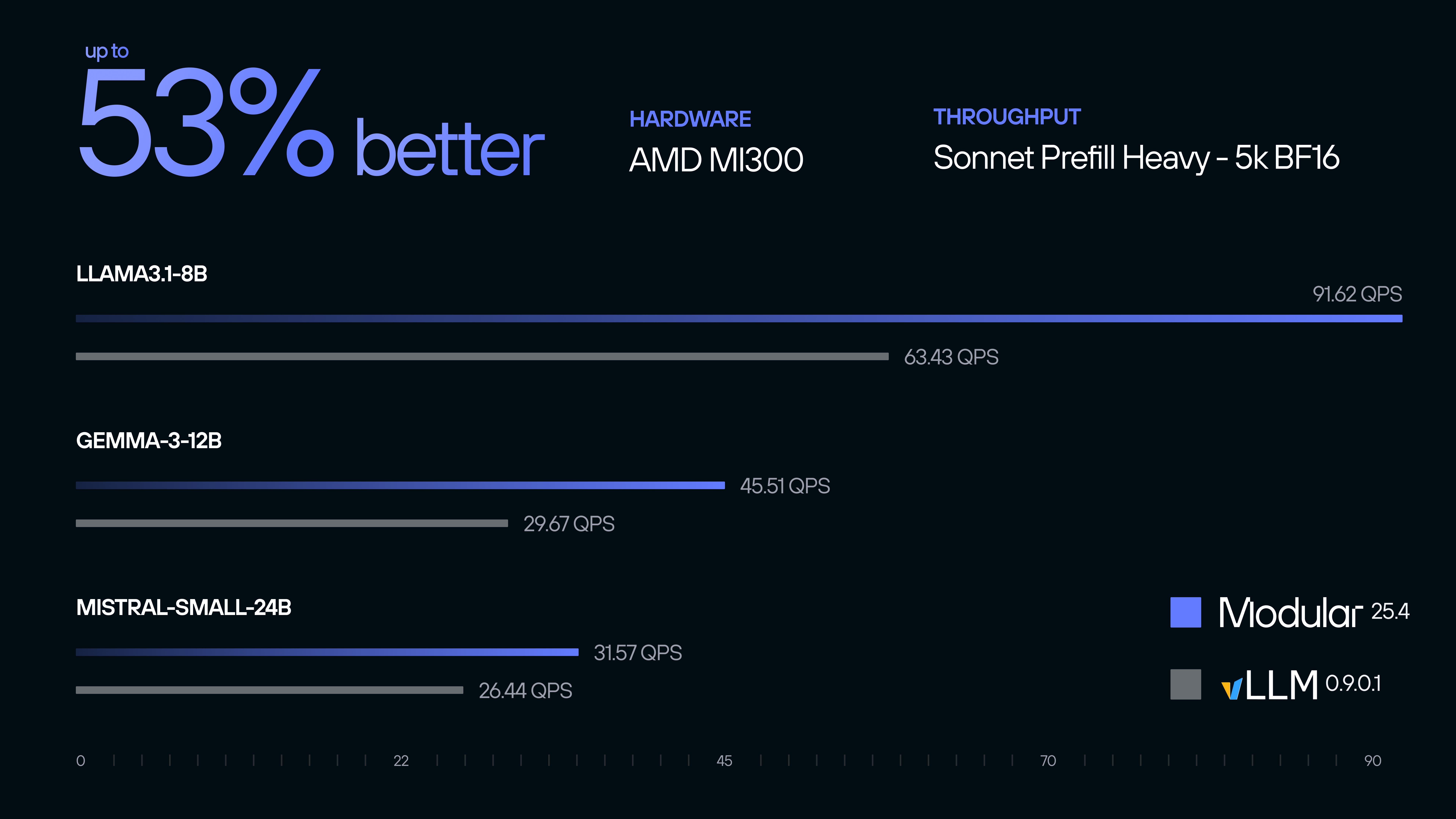
- Up to 53% better throughput on prefill-heavy BF16 workloads across Llama-3.1-8B, Gemma-3-12B, Mistral-Small-24B, and other state-of-the-art language models when compared with vLLM on AMD MI300X.
- Up to 32% better throughput for decode-heavy BF16 workloads when compared with vLLM on AMD MI300X.
- Throughput parity or better on ShareGPT workloads running on MI325X when compared to vLLM on NVIDIA H200.
AMD MI300X and MI325X GPUs often provide superior price-performance ratios for many AI workloads, giving you the flexibility to optimize total cost of ownership based on real-world economics rather than being locked into a single vendor's pricing structure. You can find a deeper analysis of these performance benchmarks in our recent AMD partnership announcement.
Beyond the headline AMD GPU support, we're also introducing:
- Initial support for AMD consumer GPUs, including basic tuning for a full range of RDNA3 and RNDA4 GPUs.
- Expanded consumer hardware compatibility with support for NVIDIA RTX 20xx through 50xx GPUs.
- A GPU support matrix that includes a wide range of the most powerful enterprise GPUs from AMD and NVIDIA with a single code-base.
While AI model support is still in development for some architectures, GPU programming capabilities are fully functional—and open source—across this expanded hardware ecosystem. You can learn to program this entire line of GPUs today using Mojo with our ever-expanding collection of Mojo GPU Puzzles.
🤖 Expanded model support
Modular 25.4 significantly expands our model ecosystem, including:
- GGUF quantized Llamas with support for q4_0, q4_k, and q6_k quantization using a paged KVCache strategy.
- Qwen3 family of models, with advanced reasoning and multilingual capabilities.
- OLMo2 family of models, designed for research and common tasks.
- Gemma3 multimodal models, offering optimized performance and improved safety.
Head over to Code with Modular where you can find these releases, along with more than 500 additional generative AI models.
📚 Enhanced documentation and developer experience
We've completely redesigned our documentation ecosystem with a unified navigation system across docs and code. Finding the resources you need is now easier than ever.
New documentation includes:
- Comprehensive guide for using AI coding assistants with Modular.
- Step-by-step tutorial for building MLP blocks as graph modules.
- Complete tutorial for writing custom PyTorch ops.
- A guide for profiling kernel performance.
🐍 Python–Mojo bindings
Mojo's simplicity and ease of use has always drawn from Python for inspiration, and Mojo 25.4 brings the languages even closer together with a new developer preview of Python–Mojo bindings. You can now call Mojo functions directly from Python code without the need to manage complex build systems or dependency chains. Develop in Python, and seamlessly replace your performance hot-spots with blazing-fast Mojo equivalents. It’s like having a turbo button for your Python apps! Learn more in the Modular forum, and try out the code examples on GitHub.
👩💻 Now open for contributions!
We've made history by open sourcing over 450k lines of production-grade Mojo kernel and serving code, and now we're inviting the developer community to help shape the future of AI infrastructure. The MAX AI kernel library is officially open for contributions! Whether you're missing a key operator for your groundbreaking model, need to extend support for a new hardware architecture, or want to optimize performance at the kernel level, there’s a place for your contributions. Join the Modular developer community in pushing the boundaries of GPU programming and help us build the foundation for the next generation of AI breakthroughs.
Get started now, and join us in person!
Modular 25.4 represents our commitment to giving you more choice, better performance, and seamless integration with your existing workflows. Whether you're:
- Optimizing total cost of ownership by choosing the most cost-effective hardware for your specific workloads.
- Building resilient infrastructure that isn't dependent on a single GPU vendor's supply chain.
- Future-proofing your AI investments against hardware vendor lock-in.
- Working with the latest language models like Qwen3 or OLMo2.
This release has something powerful to offer!
Ready to experience Modular 25.4? Get started right away with our quickstart guide, and dive into our latest tutorials to learn how to start setting up production workloads.
To celebrate this launch, we have a couple of special events lined up. First, we’re hosting Modular Hack Weekend on June 27-29, kicking off with a GPU Programming Workshop on June 27th. Join us in-person or via livestream on Friday for the workshop and lightning talks, and participate in the weekend-long hackathon virtually!

Second, we just launched our comic, GPU Whisperers, a new series that perfectly captures the beautiful chaos of living through the GenAI revolution. Got an AI horror story that you want to immortalize? Submit your own AI problems and we’ll make art from your pain.

A full list of changes is available in the MAX and Mojo changelogs. As always, we welcome your feedback and contributions to help make the Modular platform even better. Join the discussion on our community forum, and come build with us!


