

This is a guest blog post by Aydyn Tairov. Aydyn is the creator of the llama2.🔥, a popular Mojo community project with over 1.2k stars on GitHub. In this blog post Aydyn shares his journey from discovering Mojo to building llama2.🔥, the challenges he faced along the way and how he addressed them.
Mojo SDK was released in September 2023. As someone who relies on the simplicity of Python and also cares about high performance delivered by languages like C, I was excited to try out Mojo. I felt the same joy and thrill I had experienced when I first discovered programming and ran “Hello World” in QBasic and Turbo Pascal.
I wanted to learn the Mojo language, and I like learning by building. I wanted to build something more advanced using examples like matrix multiplication (matmul) that were shared during the launch as building blocks. I realized Llama2 was just open-sourced and it uses a lot of matrix multiplication for inference under the hood. I chose that as my first Mojo project.
In this post, I'll share my personal experience implementing Llama 2 inference in pure Mojo. I discuss the challenges I faced, how I addressed them, and the results.
Implementing Llama 2 in Mojo
If you’re not familiar with llama2, don't worry, you’ll still find this blog post helpful. I'll be focusing more on the steps for implementing it in Mojo, and how I optimized basic operations rather than dive deep into the model architecture.

Llama is based on the Transformers model architecture, which has been around since 2016. The model scales well on hardware that supports extensive parallelism I had already ported the llama2.c code (implemented by Andrej Karpathy) to pure Python for fun a few weeks earlier, implementing llama2.🔥 seemed like the perfect challenge to take on.
The Challenge
After I learned the basics of Mojo, I embarked on my journey to port llama2 in Mojo. There were three main steps I needed to tackle to get the solution working: 1/ reading data from files into memory, 2/ carefully setting up pointers and populating data structures, and 3/ accurately implementing the forward pass logic that generates the next tokens. A fourth aspect I kept in mind was leveraging SIMD types to maximize speed.
I encountered my first roadblock when trying to read files. Mojo now has file I/O support but at the time I was implementing it there was no I/O support. This made me realize that Mojo and its standard library is still very young and may not support all functions I’m familiar with in Python. All my attempts to open files through Python failed, or the text looked like broken UTF-8 format instead of the binary I required for the weights.
fn main() raises:
let _os = Python.import_module("os")
let f = _os.open('./tokenizer.bin', _os.O_RDONLY)
let x = _os.read(f, 10) # **<--- 10="" read="" bytes**="" ="" print(len(x.to_string()))="" print(x.to_string())="" <="" code="">Output:
43 **<--- str="" len="" 43**="" b'\\x1b\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x05\\x00'="" <="" code="">I was considering shelving this project until file I/O implemented. But the Mojo community stepped in to help out! On the discord channel, I found that it’s possible to make external libc calls from Mojo. Community members shared example code snippets for working with files. This was enough to successfully get the rest of the calculations and weight manipulations running solely in memory.
Implementation details
That weekend, empowered by these discoveries, I dove into implementing the solution on the Mojo SDK using some of the snippets I had experimented with in the Mojo Playground.
My existing llama2.py implementation proved invaluable, as I used it for reference and verifying tricky steps. This let me validate the model configs, tokenizer, and weights were being read properly. I simply printed the first few array values in Python, and then compared the outputs in Mojo.
To properly load the weights into memory, I built a Matrix structure based on Mojo's matrix multiplication benchmarks, tweaking it to reference specific memory positions. This mimicked mmap the weights file, with structures and pointers targeting the allocated chunks. I started with separate Matrix and Matrix3 structures for the layers but later refactored to a unified Matrix with overloaded getters/setters supporting 3 indices, which eliminated the need for Matrix3.
Debugging
As I built out the transformer forward pass, my initial implementation resulted in multiple issues. Luckily, running inference exposed flaws quickly — garbled weights yielded completely random output tokens. This sped up bug detection tremendously 😃

Clearly, something is wrong with the output. To isolate the bugs, I fell back on my Python version — injecting print statements and validating against its output. Print-driven debugging never gets old.
let fci = freq_cis_imag_row.offset(i // 2).simd_load[1](0)
if i == 0 and math.abs((-0.014037667773663998) - (q0 * fcr - q1 * fci)) < 1e-5:
print("found change here h,i,q0,q1,fcr,fci", h, i, q0,q1,fcr,fci)
q.offset(i).simd_store[1](0, q0 * fcr - q1 * fci)
In the example above, I was hunting down a tricky bug caused by flawed weight manipulations somewhere. But where? By comparing Python and Mojo outputs, I noticed one value differed: -0.01403... in Mojo. Tracing this back through the code revealed where that value got assigned, leading me to fix the issue.
This is an interesting case actually. I hope in future versions of Mojo, the Tensor objects could tremendously simplify debugging of such issues. Tensors can retain details about how they were modified, enabling easier tracing back through the "modification tree". Hypothetically, had the assigning value been applied on a “magic” Tensor object, I may have debugged this bug faster.
Benchmarking results
While thorough benchmarking wasn’t my goal, I couldn’t resist a basic performance test. I compared single-threaded implementations in Python, C, and Mojo. For now, I have a Mojo version that implements naive matmul. In this evaluation llama2.mojo demonstrated 60x speedup against Python, while the C version was slightly faster on smaller model sizes, on bigger models with 110 million tokens — Mojo demonstrated similar performance as C

As I had worked on the Python implementation just a few weeks ago, I remembered profiling the Python code and where the performance bottlenecks were. As expected the profiler indicated that most of the time was being spent in one matrix multiplication method.
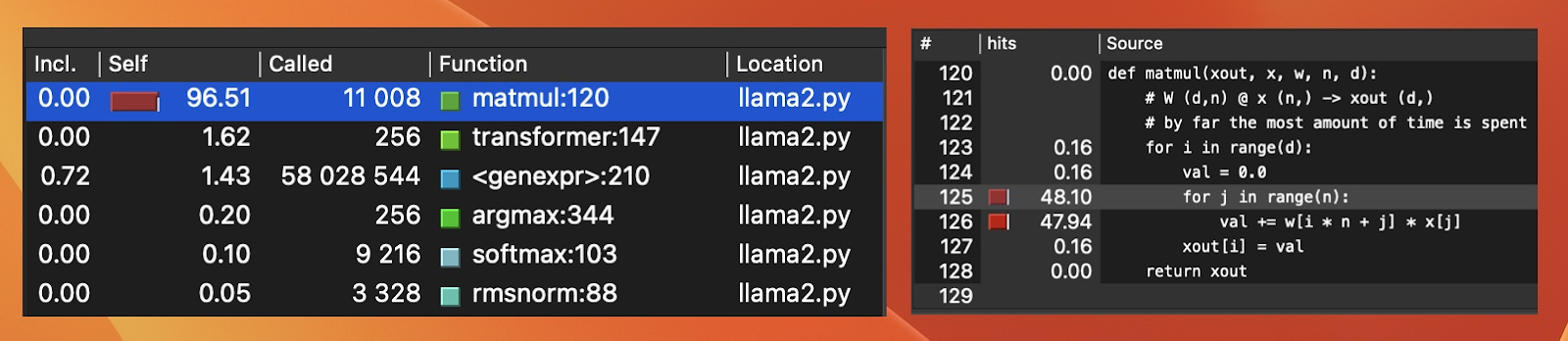
Subsequently, I decided to improve matmul in Mojo by implementing vectorized SIMD operations on internal for-loop. My initial impression was that the straightforward loops at hand weren't fit for vectorization, given that the additions focused on a single row without incorporating a second (as in Matmul examples). Here is how it looks:
fn matmul(inout xout: Matrix, x: Matrix, w: Matrix) -> None:
# W (d,n) @ x (n,) -> xout (d,)
# By far the most amount of time is spent inside this little function
for i in range(w.rows):
var val: Float32 = 0.0
for j in range(w.cols):
val += w[i,j] * x[j]
xout[i] = val
This could technically be addressed by reorganizing the weights layout in memory, which is essentially a matrix transposition. Given its resource-intensive nature, I preferred to avoid it.
Vectorization
After examining the internal loop one more time, I found that by using a temporary buffer, I could process operations in a row by adding 8 values at once. Finally, I'd calculate the sum of these 8 values using sum
matmul_vectorized(C: Matrix, A: Matrix, B: Matrix):
var T = BufferPtrFloat32.alloc(nelts)
var Tbuf = Buffer[nelts, DType.float32](T)
for i in range(0, B.rows):
memset_zero(T, nelts)
@parameter
fn dot[nelts: Int](j: Int):
T.simd_store[nelts](
0, T.simd_load[nelts](0) + A.load[nelts](j) * B.load[nelts](i, j)
)
vectorize[nelts, dot](B.cols)
C[i] = sum[nelts, DType.float32](Tbuf)
My vectorized implementation was working! The inference output was fine and it was much faster than naive matmul. I decided to benchmark solutions again.
The results were impressive now, llama2.mojo outpaced even the runfast mode compiled llama2.c

As a non-expert, my hunch for why this crude comparison was valid: llama2.c has been public for months, gaining popularity and optimization efforts. I contributed a few PRs to it as well, and I’m familiar with performance-related discussions that occurred shortly after the repository was published. The makefile in llama2.c repo includes a runfast option, which maximizes compiler optimizations. My further research revealed runfast turns on aggressive vectorization on internal loops, including matmul. Meaning, this must be a fair “out-of-the-box” comparison.
.png)
I shared these results on the project page and soon I started to get feedback from the Python community, to compare my Mojo implementation with a NumPy-based implementation. When I first published llama2.py a few months ago, I similarly received significant feedback and numerous suggestions from both the Python and ML communities. I'm a huge fan of Python and use it daily in my work, however, it's essential to note that llama2.c and its multiple forks currently serve more as academic resources. And comparing vanilla implementations seems more appropriate to me. Furthermore, the Modular blog features comparisons and benchmarks between Mojo and Python, including NumPy, where Mojo outperforms.
The Llama effect
After sharing my code on Github in the early light of a UK morning. I put it out on X/Twitter and the Mojo Discord. I never could expect what’s coming next.
Within hours, Modular team picked up on my message. I received uplifting feedback from Chris Lattner. Also my tweet was reposted by Modular and then by Andrej Karpathy, sparking massive viral attention. So far, llama2.mojo collected more than 1,100 stars on Github. It pulled in over 1 million views and thousands of reposts. It was featured on numerous web platforms, dubbing me a “Mojician”. Recently, we received pull requests introducing support for the TinyLlama model with 1.1 billion parameters. This enhancement allows for more sophisticated output generation with extended context lengths.
I'm thrilled to continue my Mojo journey and see what else I can accomplish with this game-changing technology.
And that is how I became a Mojician🔥
Resource:
- llama2.🔥 on GitHub: https://github.com/tairov/llama2.mojo
- My LinkedIn: https://www.linkedin.com/in/aydyn-tairov/
- Twitter: https://twitter.com/tairov
Until next time! 🔥


