.png)
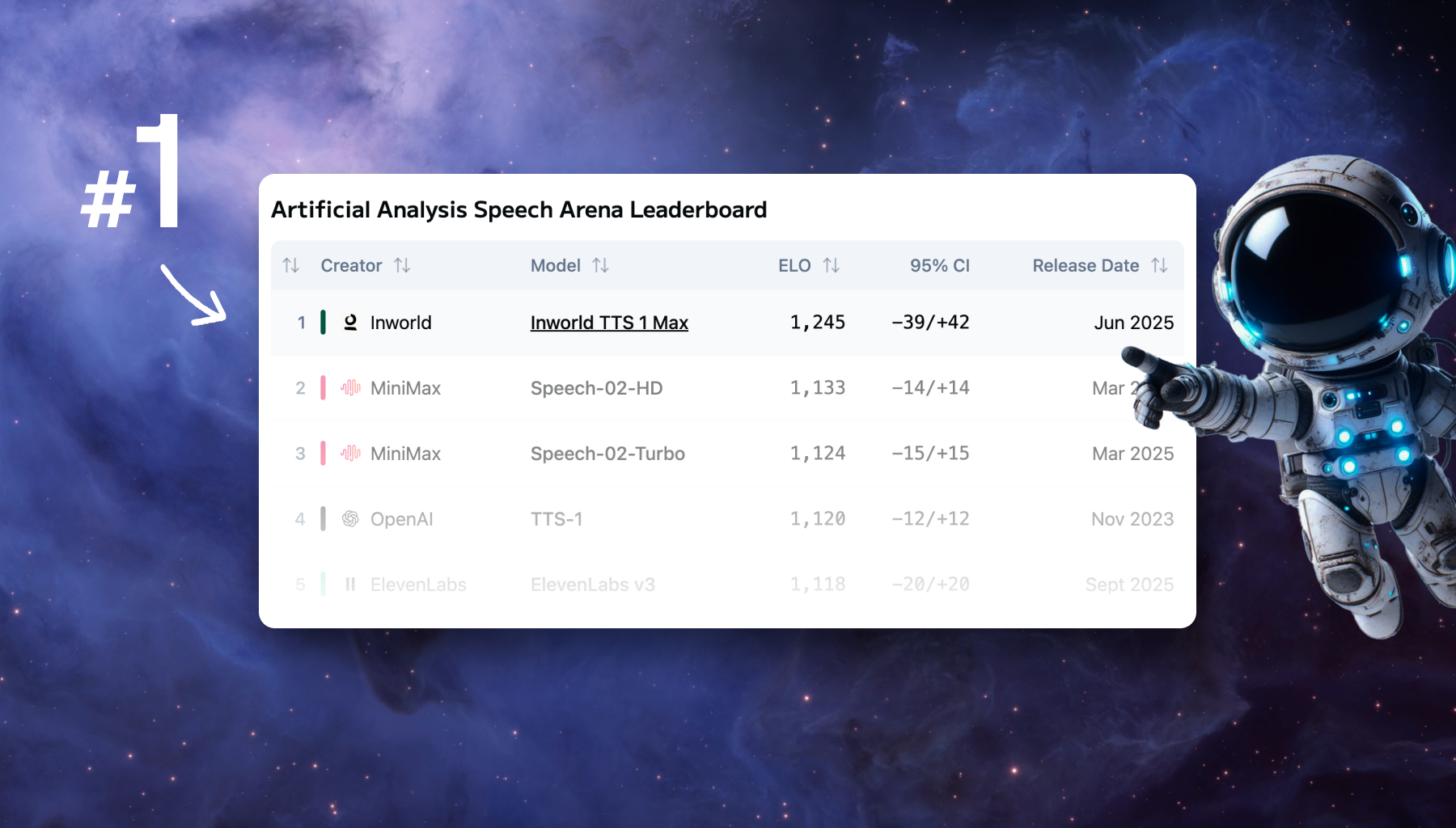
After months of productive collaboration with Inworld, it’s great to see our engineering efforts getting recognized! Today the "Inworld TTS 1 Max" model (powered by the Modular Platform) is in #1 position on the Artificial Analysis speech leaderboard! Whoo-hoo!
Artificial Analysis is the independent, authoritative benchmarking platform that comprehensively tests over 100 LLMs across intelligence, speed, and cost metrics. The platform measures real-world end-to-end performance across providers, tracking both proprietary and open-weight models, making it an essential resource for understanding true cost-performance tradeoffs in production environments.
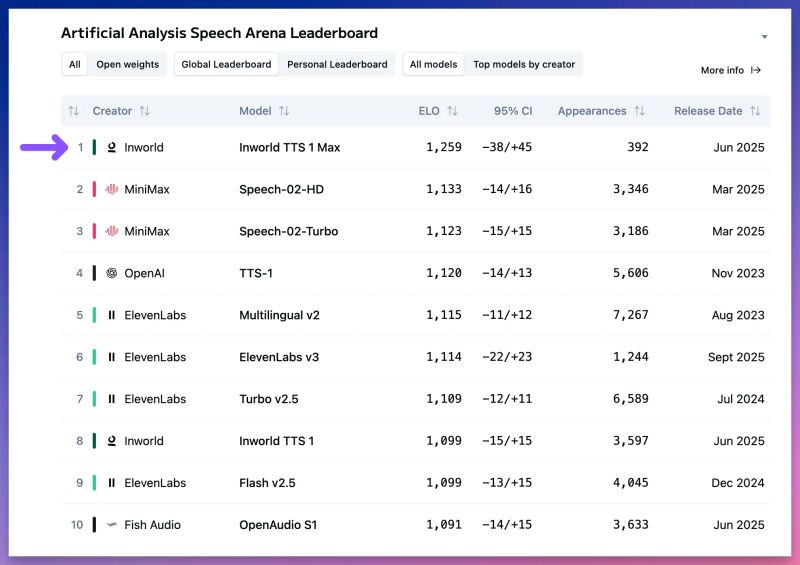
How the rankings happen
The Artificial Analysis Speech Arena ranks leading Text to Speech (TTS) models based on human preferences. In the arena, users compare two pieces of generated speech side by side and select their preferred output without knowing which models created them. The speech arena includes prompts across four real-world categories of prompts: Customer Service, Knowledge Sharing, Digital Assistants, and Entertainment.
Model details
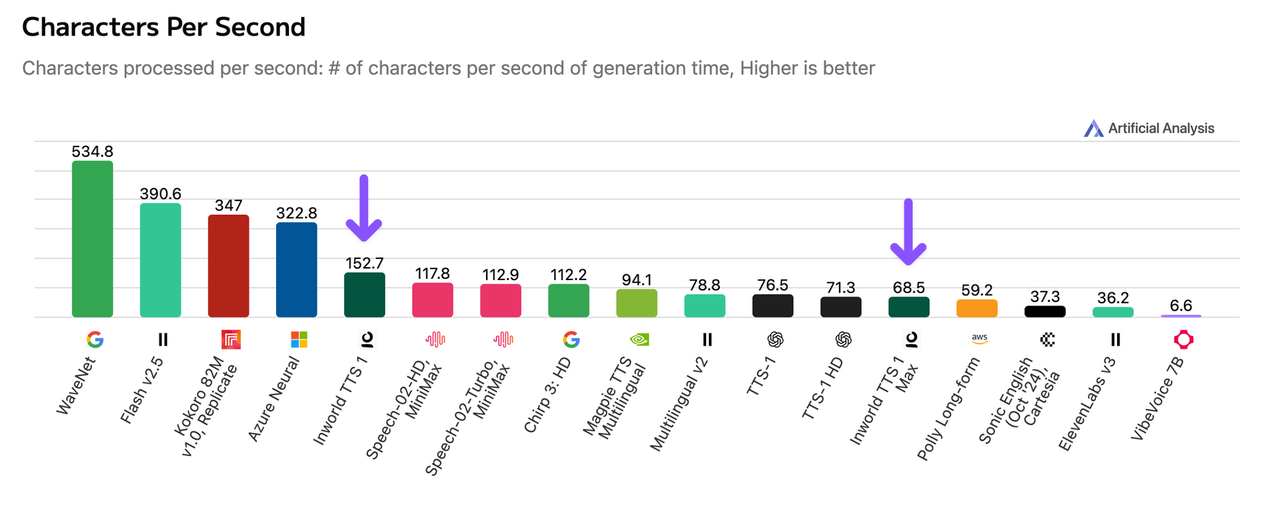
Inworld TTS 1 Max and Inworld TTS 1 (both powered by Modular) support 12 languages including English, Spanish, French, Korean, and Chinese, and voice cloning from 2-15 seconds of audio. Inworld TTS 1 processes ~153 characters per second of generation time on average, with the larger model, Inworld TTS 1 Max processing ~69 characters on average. Both models also support voice tags, allowing users to add emotion, delivery style, and non-verbal sounds, such as “whispering”, “cough”, and “surprised”.
Both TTS-1 and TTS-1-Max are transformer-based, autoregressive models employing LLaMA-3.2-1B and LLaMA-3.1-8B respectively as their SpeechLM backbones.
We're so proud of this partnership, where both companies’ engineering teams worked together to integrate Modular’s MAX Framework and Inworld’s text-to-speech model. Read more of the behind-the-scenes of this partnership and it's business outcomes here. And congrats to our performance team here at Modular who worked so hard to make this possible!
"Our collaboration with Modular is a glimpse into the future of accessible AI infrastructure. Our API now returns the first 2 seconds of synthesized audio on average ~70% faster compared to vanilla vLLM based implementation, at just 200ms for 2 second chunks. This allowed us to serve more QPS with lower latency and eventually offer the API at a ~60% lower price than would have been possible without using Modular’s stack."
- Igor Poletaev (Chief Science Officer - Inworld)
Discover what Modular can do for you


