We made state-of-the-art speech synthesis scalable, and achieved a truly remarkable improvement both for the latency and throughput.
70%
Faster Time to first audio
60%
Lower Cost
200ms
Time to First audio
01
Faster Time to first audio
02
Lower Cost
03
Time to First audio
"Our collaboration with Modular is a glimpse into the future of accessible AI infrastructure. Our API now returns the first 2 seconds of synthesized audio on average ~70% faster compared to vanilla vLLM based implementation, at just 200ms for 2 second chunks. This allowed us to serve more QPS with lower latency and eventually offer the API at a ~60% lower price than would have been possible without using Modular’s stack."

Igor Poletaev
Chief Science Officer - Inworld
Problem
Inworld helps teams build AI products for consumer applications, with services that organically evolve throughout the product experience and scale to meet user demands.
As a team of former DeepMind and Google engineers, they’re already pushing the limits of what they thought possible with existing AI infrastructure, and they came to Modular because they needed an even faster, more capable speech synthesis service. The computational intensity of generating realistic, low-latency speech creates significant technical challenges. For example specialized APIs were essential to enable scalable and economically viable voice AI applications.
Solving this required more than just optimizing their text-to-speech (TTS) model; it demanded a fundamental redesign of the entire inference stack. This is where the collaboration with Modular began.
Solution
Our partnership with Inworld represents a co-engineered approach, where both companies’ engineering teams worked together to integrate Modular’s MAX Framework and Inworld’s proprietary text-to-speech model. In less than 8 weeks, we went from start-of-engagement to the worlds most advanced state-of-the-art speech pipeline on NVIDIA Blackwell GPU Architecture.
There were many technical hurdles to overcome to make the architecture scalable and achieve the fastest results possible. Using Modular's MAX and Mojo together was essential. MAX’s streaming-aware scheduler - designed to minimize time-to-first-token (TTFT) - coupled with its highly optimized kernel library, delivered ~1.6X faster performance for the Speech-Language Model (SpeechLM) component. Mojo offers the ability to define high-efficiency custom kernels, allowing Inworld to create things like a tailored silence-detection kernel that runs directly on the GPU.
The SpeechLM architecture itself was a breakthrough - achieved by adapting and scaling a cutting-edge, open-source-inspired tech stack. The model architecture is a Speech-Language Model (SpeechLM) built upon an in-house neural audio codec and an LLM backbone.
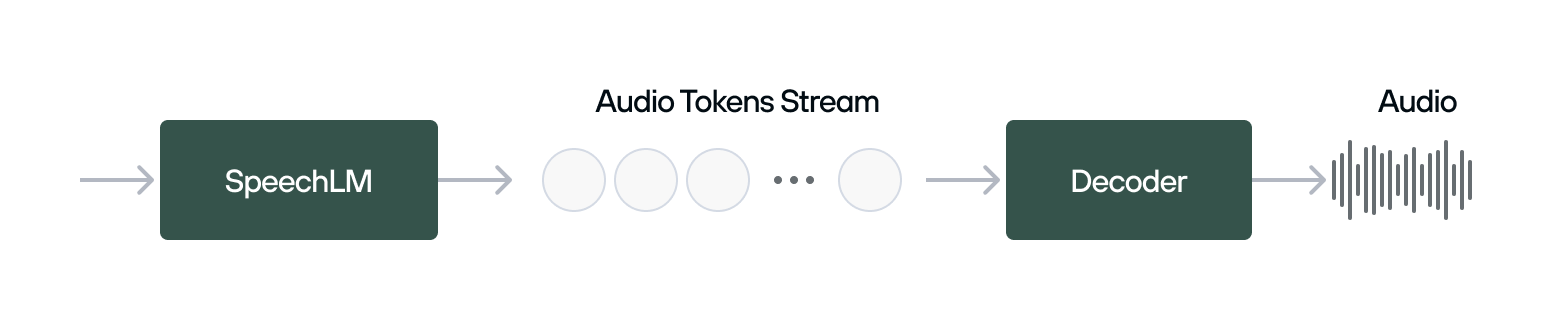
Now, anyone who builds with Inworld, gets the direct benefits of Modular:
Deliver truly instant interactions. Thanks to MAX's streaming-aware scheduler, your application gets the first chunk of audio in as little as 200ms, eliminating awkward pauses and keeping users immersed.
Scale your application without fear of cost. By optimizing the entire stack for high throughput, we cut the price by ~60%. You can now serve more users and deploy rich voice experiences at a cost that is ~22x lower than alternatives.
Ensure seamless performance under load. Our architecture is built for high throughput, ensuring your application can serve any QPS you need. The user experience remains seamless and responsive, even during traffic spikes.
Results
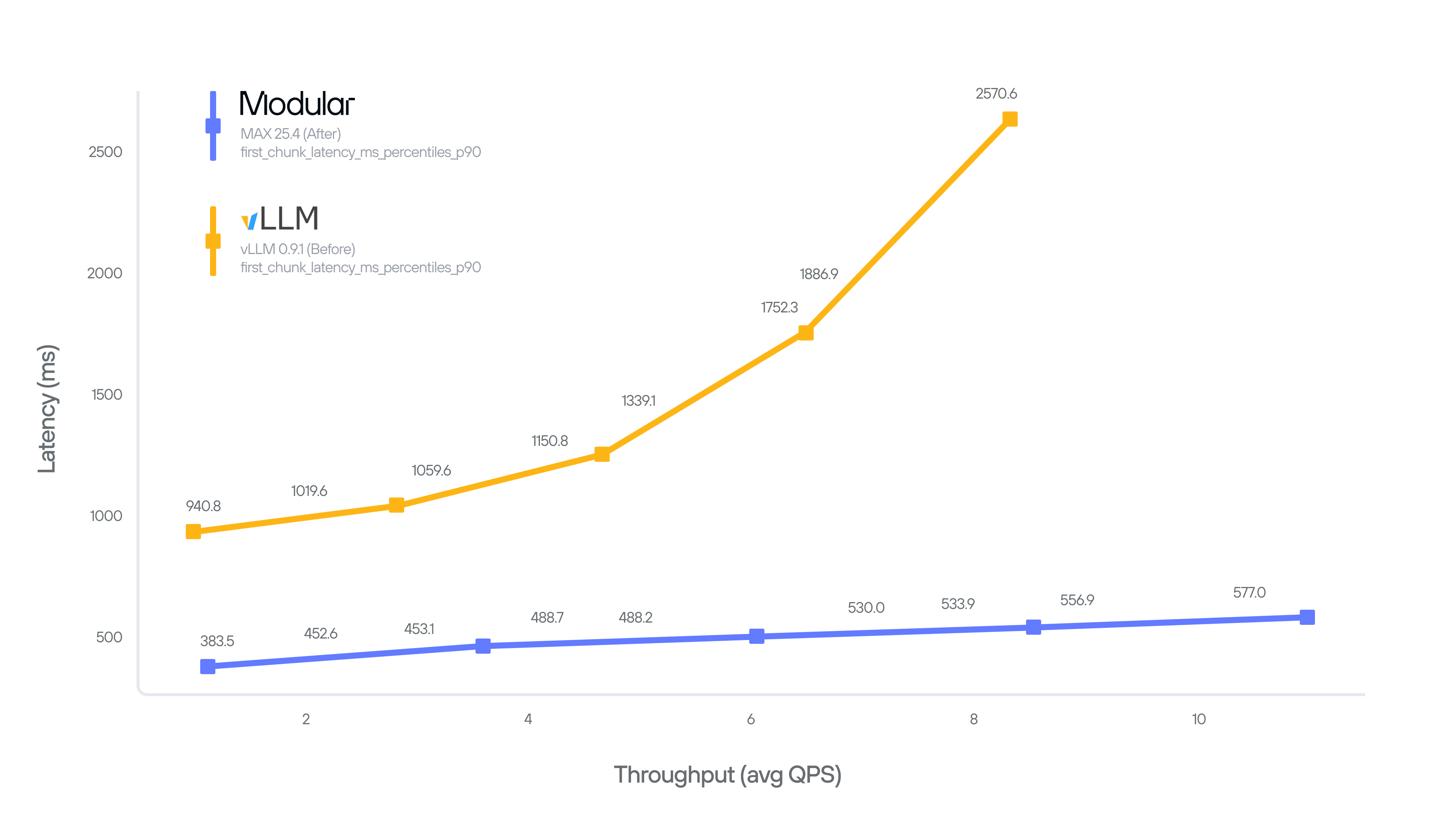
Deploying Inworld's model with the Modular Platform has achieved a truly remarkable improvement both for the latency and throughput. In the streaming mode, the API now returns the first 2 seconds of synthesized audio on average ~70% faster if compared to vanilla vLLM-based implementation. This allowed us to serve more QPS with lower latency and eventually offer the API at a ~60% lower price than would have been possible without Modular's stack.
About Inworld
Inworld develops AI products for builders of consumer applications, enabling scaled applications that grow into user needs and organically evolve through experience. They are fundamentally redefining AI experiences with a return to the user.
Read more of the technical details of the engagement on Inworld's blog.
Request a demo of this use case
If you're deploying text-to-speech inference, request a demo today. Excited to chat!
Case Studies





Scales for enterprises


Sign up today
Signup to our Cloud Platform today to get started easily.
Sign Up
Browse open models
Browse our model catalog, or deploy your own custom model
Browse models