
When selling GPUs as a commodity meets the fastest inference engine - cost savings can skyrocket.
20+
AI Models
80%
Cheaper Batch Inference
1
Unified Batch API
"Modular’s team is world class. Their stack slashed our inference costs by 80%, letting our customer dramatically scale up. They’re fast, reliable, and real engineers who take things seriously. We’re excited to partner with them to bring down prices for everyone, to let AI bring about wide prosperity."

Evan Conrad
CEO - San Francisco Compute
Problem
San Francisco Compute (SF Compute) operates a GPU marketplace that enables AI companies to access large-scale GPU clusters by the hour, for training and inference workloads without forcing expensive long-term contracts.
As a platform serving everyone from AI startups to research labs, they're experiencing growing demands from customers who not only needed raw compute power, but also want competitively priced AI inference. This led to a lightbulb moment - what if SF Compute could offer the world's best AI infrastructure, on their compute marketplace, at the most competitive price in the market?
Solving this required more than just adding more GPUs or optimizing scheduling; it demanded a complete reimagining of how AI inference could be accelerated at the hardware level - scaling optimized batch workloads into a GPU marketplace that dynamically allocates compute by the hour.
Solution
SF Compute and Modular partnered together, to build the world's cheapest, large volume batch API across leading industry AI models - we call it the SF Compute Large Scale Inference API, powered by Modular. It's a high-throughput, asynchronous batch inference interface that supports over 20+ state-of-the-art models across language, vision, and multimodal domains, ranging from efficient 7B parameter models to 600B+ frontier systems including DeepSeek-R1, Llama3.3-70B, QwQ, Qwen, InternVL and many more. By combining Modular’s high-efficiency inference stack with SF Compute’s real-time spot market, the API delivers inference at up to 80% lower cost than the current market baseline.
By combining SF Compute’s unified cloud marketplace with Modular’s hardware abstraction platform, we’ve built true fungibility across compute vendors. This required solving several uniquely challenging technical hurdles:
- Hardware unification: Modular’s Platform provides unified model cluster, serving and kernel development APIs, delivering industry leading performance without sacrificing portability across heterogeneous hardware platforms.
- Cloud unification: SF Compute’s platform abstracts physical infrastructure behind a programmable spot market and dynamic scheduler, enabling seamless allocation across heterogeneous compute backends.
- Intelligent placement & routing: Together, they automatically allocate workloads using a dynamic workload router that adapts to current infrastructure load, bandwidth availability, model performance profiles, and real-time market pricing. For developers, that means faster inference, no tuning, and no hardware headaches.
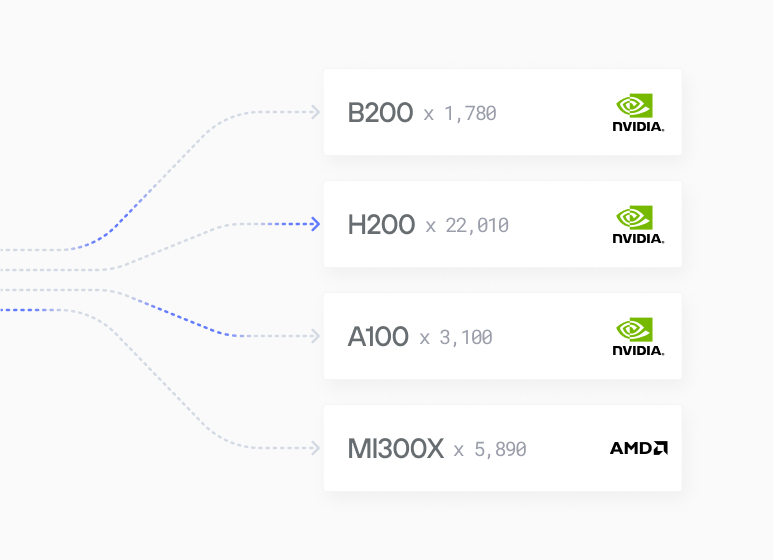
The result: H100s, H200s, MI300/325Xs (coming soon), and next-gen accelerators compete in a single market on pure price-performance. For developers, hardware complexity disappears - models are routed to the best-fit resources, transparently. This isn’t just cost reduction – it’s a fundamental redefinition of how AI gets built and deployed.
Results
The Modular Platform complements this with compiler-native execution, speculative decoding, and the world’s most performant hardware agnostic AI kernels - routinely achieving 90%+ GPU utilization. With our combined powers, this stack delivers up to 80% lower cost per token compared to existing providers 🚀.
This isn’t just competitive pricing - it’s a structural shift in how inference is monetized. While incumbents rely on fixed, over-provisioned infrastructure to preserve margins, we optimize for volume, efficiency, and developer value - collapsing the cost stack and returning the gains to users.
Below is a list of all supported models available for batch inference. Ready to deploy your model for up to 80% less? Start using the Batch Inference API. Get Early Access Today!
Want a model added? Talk to SF Compute — they will respond in hours, not weeks.
About San Francisco Compute
SF Compute operates a revolutionary GPU marketplace that provides on-demand access to large-scale GPU clusters, enabling AI companies to rent exactly the compute capacity they need - whether it's 1,024 GPUs for a week or 8 GPUs for 2 hours. They are fundamentally transforming how AI infrastructure is consumed with a liquid market for compute as a commodity.
Read more about their flexible infrastructure approach on SF Compute's Inference page.
Case Studies






Scales for enterprises


Get started guide
Install MAX with a few commands and deploy a GenAI model locally.
Read Guide
Browse open models
500+ models, many optimized for lightning-fast performance
Browse models