Modular partnered with AWS to bring MAX to AWS Marketplace, offering SOTA performance for GenAI workloads across GPUs types.
15+
CPU+GPU Architectures
500+
Models
33+
Geographic Regions
01
CPU+GPU Architectures
02
Models
03
Geographic Regions
"At AWS we are focused on powering the future of AI by providing the largest enterprises and fastest-growing startups with services that lower their costs and enable them to move faster. The MAX Platform supercharges this mission for our millions of AWS customers, helping them bring the newest GenAI innovations and traditional AI use cases to market faster."

Bratin Saha
VP of Machine Learning & AI services
The Opportunity
The rapid adoption of generative AI has created significant challenges for organizations looking to deploy large language models (LLMs) in production:
Hardware Complexity and Vendor Lock-in: Traditional AI serving solutions require specific hardware configurations and proprietary software stacks (like CUDA), creating vendor lock-in and limiting deployment flexibility. Organizations found themselves constrained to specific GPU types and unable to easily migrate between different hardware options.
Performance vs. Accessibility Trade-off: While many open-source models are available, achieving production-grade performance typically requires extensive optimization work, custom kernels, and deep expertise in GPU programming. This created a barrier for organizations without specialized AI infrastructure teams.
Deployment and Scaling Challenges: Deploying AI models across different AWS services (EC2, EKS, AWS Batch) required significant engineering effort to handle compatibility issues, optimize for different GPU types, and maintain consistent performance across environments.
Integration Complexity: Organizations with existing applications built around OpenAI's API faced challenges when trying to deploy their own models, often requiring significant code changes and API adaptations.
The Partnership
Modular partnered with AWS to bring their MAX (Modular Accelerated eXecution) platform to AWS Marketplace, offering a comprehensive solution to these challenges:
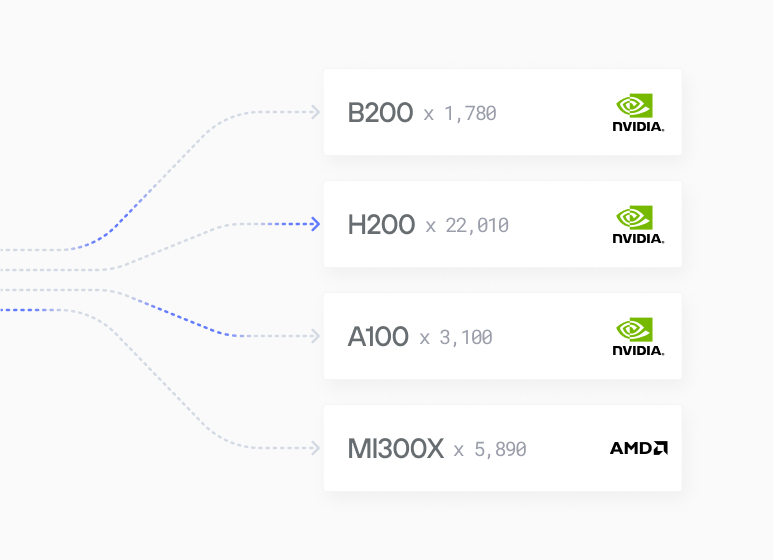
Unified, Hardware-Agnostic Platform: MAX provides a single Docker container (max-nvidia-full) that runs seamlessly across diverse NVIDIA GPUs (B200, H200, H100, A100, A10, L40, and L4) without requiring CUDA or hardware-specific optimizations. This "write once, deploy everywhere" approach eliminates vendor lock-in.
Pre-Optimized Model Library: The platform includes 500+ pre-optimized popular models from Hugging Face, including Llama 3.3, Deepseek, Qwen2.5, and Mistral. Each model comes with individual optimizations for maximum performance, eliminating the need for manual optimization work.
API Compatibility: MAX serves models through standard AI-compatible endpoints, allowing organizations to use it as a drop-in replacement for OpenAI API calls. This enables seamless integration with existing applications and tools without code changes.
Flexible Deployment Options: The containerized solution deploys easily across various AWS compute services including:
- Amazon ECS (Elastic Container Service)
- Amazon EKS (Elastic Kubernetes Service)
- Amazon ECS Anywhere
- Amazon EKS Anywhere
- EC2 instances
- AWS Batch
Advanced Optimization Features: MAX includes sophisticated serving optimizations such as:
- Prefix caching for improved latency
- Speculative decoding for faster generation
- Intelligent batching and memory management
- Inflight batching without requiring chunked prefill
- Paged KVCache strategy for efficient memory usage
The Outcome
The partnership between Modular and AWS has delivered significant benefits to organizations deploying GenAI workloads:
Dramatically Reduced Time to Deployment: Organizations can now deploy production-ready AI endpoints in minutes rather than weeks. The pre-configured Docker container eliminates the complexity of manual setup and optimization.
Industry-Leading Performance: MAX delivers high-performance serving with low latency and high throughput across all supported GPU types. Organizations report achieving performance comparable to or exceeding custom-optimized solutions without the engineering overhead.
Cost Optimization Through Flexibility: The hardware-agnostic approach allows organizations to:
- Choose the most cost-effective GPU options for their workloads
- Easily migrate between GPU types based on availability and pricing
- Scale efficiently across different AWS services without re-engineering
Seamless Migration Path: Organizations using OpenAI's API have successfully migrated to self-hosted models using MAX with minimal code changes, gaining control over their AI infrastructure while maintaining application compatibility.
Enterprise-Ready Support: Through AWS Marketplace, organizations gain access to:
- Standard support for deployment and configuration
- Enterprise premium support for large-scale implementations
- Professional services for custom optimization and integration
- AWS infrastructure support for underlying compute resources
Accelerated Innovation: By abstracting away infrastructure complexity, engineering teams can focus on building AI applications rather than managing deployment pipelines. The ability to customize models and kernels using Mojo provides a path for advanced users to push performance boundaries when needed.
The availability of MAX on AWS Marketplace represents a significant step forward in democratizing high-performance AI infrastructure, enabling organizations of all sizes to deploy state-of-the-art GenAI models with enterprise-grade performance and reliability.
About AWS
Amazon Web Services (AWS) is the world's most comprehensive and broadly adopted cloud platform, offering over 200 fully featured services from data centers globally. As the leader in cloud computing, AWS serves millions of customers—including the fastest-growing startups, largest enterprises, and leading government agencies—helping them lower costs, become more agile, and innovate faster.
You can read the announcement between Modular and AWS here.
Case Studies





Scales for enterprises


Sign up today
Signup to our Cloud Platform today to get started easily.
Sign Up
Browse open models
Browse our model catalog, or deploy your own custom model
Browse models