Modular partners with AMD to bring the AI ecosystem more choice with state-of-the-art performance on AMD Instinct GPUs.
5+
GPU Architectures
500+
Models
50%+
Performance Wins vs VLLM
01
GPU Architectures
02
Models
03
Performance Wins vs VLLM
"We're truly in a golden age of AI, and at AMD we're proud to deliver world-class compute for the next generation of large-scale inference and training workloads… We also know that great hardware alone is not enough. We've invested deeply in open software with ROCm, empowering developers and researchers with the tools they need to build, optimize, and scale AI systems on AMD. This is why we are excited to partner with Modular… and we’re thrilled that we can empower developers and researchers to build the future of AI."

Vamsi Boppana
SVP of AI, AMD
The Opportunity
The AI infrastructure landscape has long lacked choice - most AI frameworks and models have been optimized exclusively for CUDA-based systems. This creates significant challenges for organizations seeking competitive alternatives and freedom to easily move their services across infrastructure, particularly when there have been enormous constraints on GPU supplies.
While AMD offers powerful datacenter GPUs like the MI300 series with impressive specifications, achieving competitive AI performance often requires extensive manual optimization. Many organizations have struggled to achieve comparable performance to CUDA-optimized solutions, which makes it difficult to lower their total cost of ownership (TCO). Furthermore, many enterprises have multi-year commitments to NVIDIA compute: while they want to adopt AMD compute, they do not want to have to straddle two incompatible software stacks because it impacts their product velocity.
The Partnership
Modular partnered with AMD to bring the full power of the Modular Platform to AMD's GPU portfolio, delivering a comprehensive solution that offers choice to everyone:
General Availability Across AMD Datacenter GPUs: The partnership marks the general availability of the Modular Platform across AMD's entire datacenter GPU portfolio, including the MI300, MI325, and flagship MI355. This provides organizations with immediate access to competitive GPU alternatives.
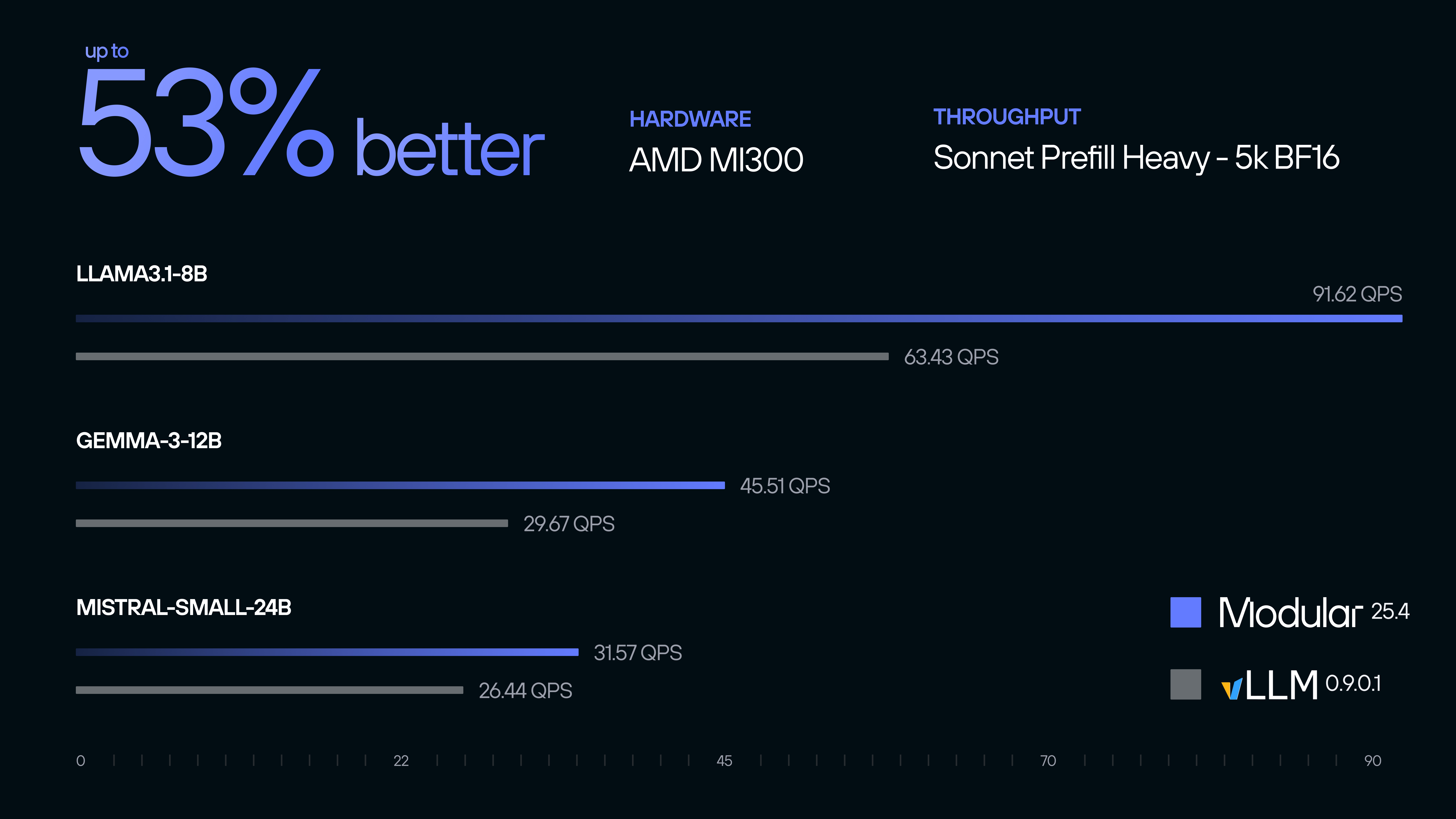
Superior Performance: The MAX inference server delivers unprecedented performance optimization for AMD hardware. In rigorous benchmarking, MAX demonstrates
- ✅ Up to 53% better throughput on prefill-heavy BF16 workloads over vLLM (0.9.1)
- ✅ Up to 32% better throughput on decode-heavy BF16 workloads over vLLM (0.9.1)
- ✅ Performance parity or better compared to vLLM on NVIDIA H200 when running on AMD MI325
Single Container, Multi-Vendor Support: MAX provides a single container that scales seamlessly across both NVIDIA and AMD GPUs. This unified approach eliminates the need for vendor-specific deployments, enabling enterprises to deploy against existing NVIDIA commits and scale into AMD capacity with a unified software stack.
Mojo-Powered Portability: The solution leverages Mojo, a Python-family language designed for heterogeneous computing. Mojo's makes it easier than ever for Python programmers to learn GPU programming, and do so in a way that is portable across AMD and NVIDIA GPUs - bringing a portable-by-default experience to AI developers.
Deep Integration: MAX integrates deeply with AMD hardware, providing enterprise-grade support while maintaining the openness and flexibility that developers need.
The Outcome
The partnership between Modular and AMD has delivered transformative outcomes for the AI infrastructure landscape:
Enabling choice: For the first time, organizations have a production-ready alternative that delivers competitive or superior performance on non-CUDA hardware.
Real Cost Optimization: Organizations can now leverage AMD GPUs' and choose between vendors based on price, availability, and performance creates genuine market competition and cost savings.
Multi-Vendor Kubernetes Deployments: Enterprises gain the freedom to deploy across mixed GPU fleets thanks to Mammoth - Modular's Kubernetes-native cloud infrastructure that allows you to deploy, scale and manage your GenAI applications with state of the art performance across NVIDIA and AMD GPUs, optimizing for cost, availability, and workload requirements without code changes.
Developer Liberation: Developers can focus on building AI applications rather than managing vendor-specific optimizations.
Enterprise-Grade Performance: Organizations report achieving performance that matches or exceeds specialized solutions. MAX models on AMD MI325 exceed throughput parity for ShareGPT compared to vLLM on NVIDIA H200.
Accelerated AMD Ecosystem Growth: The partnership validates AMD's AI hardware investments and accelerates ecosystem development.
The partnership represents a great moment in AI infrastructure, combining Modular's highly performant, and portable AI infrastructure, with AMD's incredible hardware.
About AMD
Advanced Micro Devices (AMD) is a global semiconductor leader that has pioneered high-performance and adaptive computing for over 50 years. As one of the world's largest semiconductor companies, AMD designs and builds the essential technologies that power modern data centers, artificial intelligence, PCs, gaming consoles, and embedded systems.
You can read the original partnership blog here.
Case Studies





Scales for enterprises


Sign up today
Signup to our Cloud Platform today to get started easily.
Sign Up
Browse open models
Browse our model catalog, or deploy your own custom model
Browse models