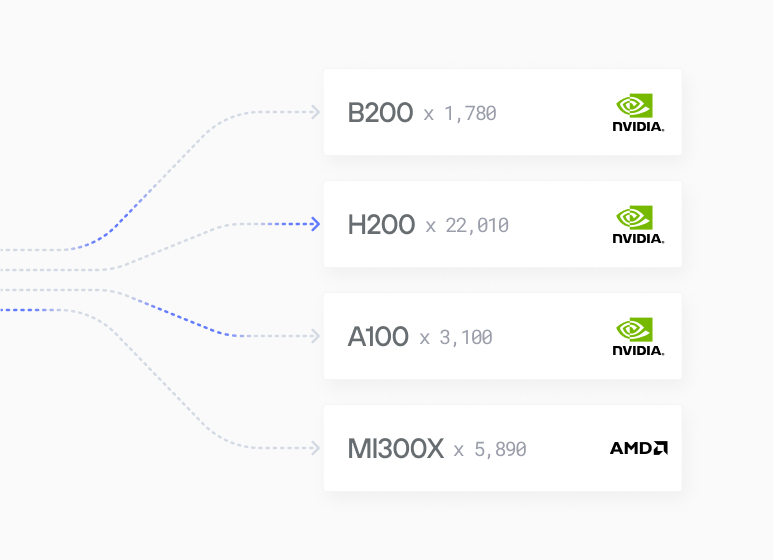
Modular’s Platform provides state-of-the-art support for NVIDIA Blackwell, Hopper, Ampere, Ada Lovelace and NVIDIA Grace Superchips.
10+
GPU Architectures
500+
Models
70%+
Performance Wins vs VLLM
01
GPU Architectures
02
Models
03
Performance Wins vs VLLM
"Developers everywhere are helping their companies adopt and implement generative AI applications that are customized with the knowledge and needs of their business. Adding full-stack NVIDIA accelerated computing support to the MAX platform brings the world’s leading AI infrastructure to Modular’s broad developer ecosystem, supercharging and scaling the work that is fundamental to companies’ business transformation."

Dave Salvator
Director, AI and Cloud
The Opportunity
The AI development landscape faces a fragmented collection of open source AI projects causing advanced developers struggle with complexity - particularly when they want to deliver full-stack performance optimizations. There are trade-offs in existing solutions that force developers to choose between model compatibility and production-grade performance on GPUs. The effort often requires manual optimization, custom CUDA kernels, and deep GPU programming expertise. The industry lacks a unified approach to heterogeneous computing that could seamlessly leverage both CPUs and GPUs, which slows progress and innovation.
The Partnership
NVIDIA, as the world leader in accelerated compute, believes in helping solve these challenges and is supporting our efforts at Modular to improve the world for GPU developers everywhere. Together, we’re bringing comprehensive NVIDIA GPU support to the Modular Platform, creating a unified solution for heterogeneous AI computing:
State-of-the-Art Hardware Support: The Modular Platform provides state-of-the-art support for NVIDIA B200, H200, H100 GPUs along with A100, and L40S GPUs, and the incredible NVIDIA Grace Superchips. This broad hardware support ensures compatibility with NVIDIA's latest accelerated computing infrastructure.
Unified Development Experience: Developers now have one toolchain that scales to all their AI use cases – GenAI and traditional AI alike – unlocking novel CPU+GPU programming models. This unified approach simplifies development and deployment across diverse workloads.
Mojo GPU Programming: Mojo code work seamlessly on a wide range of NVIDIA GPUs and on NVIDIA Grace CPUs. Mojo's high-level abstractions simplify both CPU and GPU programming using a single language and standard library, while still providing low-level control when needed.
Custom Model Acceleration: The Modular Platform also provides a Python-based graph API that allows you to build custom, state-of-the-art models that are immediately accelerated on NVIDIA GPUs.
The Outcome
The partnership between Modular and NVIDIA has delivered transformative benefits for AI developers and enterprises:
Simplified GPU Adoption: Organizations can now deploy AI models on NVIDIA GPUs without specialized CUDA expertise. The Modular Platform handles the complexity of GPU programming, making advanced acceleration accessible to a broader developer audience.
Unparalleled Performance: By combining Modular's optimization capabilities with NVIDIA's hardware acceleration, users achieve industry-leading performance without manual optimization work.
True Write-Once, Deploy-Anywhere: Developers can write code once and deploy it seamlessly across CPUs and GPUs. This flexibility allows organizations to choose the most cost-effective hardware for each workload without code modifications.
Novel Programming Models: The deep integration unlocks new heterogeneous computing capabilities, allowing developers to create innovative applications that intelligently distribute work between CPUs and GPUs for optimal performance.
Reduced Time to Market: Organizations report significantly faster development cycles, as they no longer need to maintain separate codebases for different hardware targets or spend months optimizing for specific accelerators.
The collaboration represents a major step forward in democratizing GPU-accelerated AI, making it possible for organizations of all sizes to leverage NVIDIA's powerful hardware through Modular's unified, developer-friendly platform.
About NVIDIA
NVIDIA is the pioneer and leader in accelerated computing, transforming the world's largest industries through AI and digital twins. The company invented the GPU in 1999, which sparked the growth of the PC gaming market, redefined computer graphics, and ignited the modern AI revolution.
You can read the partnership announcement here.
Case Studies





Scales for enterprises


Sign up today
Signup to our Cloud Platform today to get started easily.
Sign Up
Browse open models
Browse our model catalog, or deploy your own custom model
Browse models