

Today we’re thrilled to announce that MAX Developer Edition is now available in preview for developers worldwide! 🥳🎉. In this developer blog post, we'll take an in-depth look at MAX, its key features and capabilities, and how to use it to deploy your first MAX optimized model. Using code examples we’ll illustrate its benefits, cover key concepts, and share additional resources to continue your MAX journey.
Before we get started, head over to the MAX documentation page, and follow the instructions to install MAX Developer Edition preview. If you’re looking for a deeper discussion on why we built MAX, what problems it addresses, read our announcement blog post. If you are a Mojo🔥developer and want to learn more about the future of Mojo and MAX together, we have another blog post for you: MAX is here! What does that mean for Mojo🔥?
Roll up your developer sleeves and let’s jump 🦘right into MAX!
MAX Developer Edition (DE) preview
MAX is an integrated, composable suite of products that simplify your AI infrastructure and gives you everything you need to deploy low-latency, high-throughput inference pipelines into production. MAX meets AI developers where they are. It doesn't require a complete overhaul of your AI pipeline or serving infrastructure; it seamlessly integrates with your existing code, enabling you to benefit immediately and take advantage of new features gradually. There are a few different ways to get started with MAX:
- Try it with your existing models: MAX offers Python and C APIs to replace your current PyTorch, TensorFlow, or ONNX inference calls with MAX Engine. With 3 lines of code you can optimize and execute your models up to 5x faster across a variety of CPU platforms (Intel, AMD, Graviton). Additionally, use MAX Serving as a drop-in replacement for your NVIDIA Triton Inference Server.
- Extend and optimize your AI pipelines: MAX is fully extensible with Mojo🔥 - enabling AI developers to innovate faster and unlock new avenues of performance through custom logic. Mojo’s high performance enables you to accelerate your custom preprocessing, post-processing and data logic with a familiar Pythonic code.
- Supercharge your advanced AI workloads: MAX offers a new Graph API enabling advanced users to author complete graphs. MAX Graphs are hardware agnostic which means it is easy to get high-performance inference due to whole graph-level optimization on a wide range of hardware, including ones we’re yet to see.
We’ll be releasing Enterprise Edition in the near future, sign up to be notified.
Using the MAX Developer Edition
The first release of MAX: MAX Developer Edition 24.1, comes with everything you need to build and deploy high-performance AI pipelines. Mojo is now bundled with the MAX SDK and we’ve simplified the versioning of Mojo to match the MAX version, which follows a YY.MAJOR.MINOR version scheme. Because this is our first release in 2024, that marks this version 24.1. We dive deeper into the rationale behind the decision in a dedicated blog post: MAX is here! What does that mean for Mojo🔥?
MAX Developer Edition 24.1 includes:
- New MAX Engine: A state-of-the-art graph compiler and runtime library that compiles and executes models from TensorFlow, PyTorch, ONNX, and MAX Graphs to deliver high performance, low-latency inference speed on Intel, AMD, ARM CPUs. Reduced precision inference and GPU support are coming soon.
- New MAX Serving: A serving solution for MAX Engine that provides full interoperability with existing AI serving systems (such as Triton) and that seamlessly deploys within existing container infrastructure (such as Kubernetes). You can use pre-built Docker container images or build your own with custom inference pipelines
- Latest release of Mojo: A massive update to the world's first programming language purpose-built for AI. Mojo seamlessly integrates with MAX Engine enabling AI developers to author high-performance inference pipelines with custom pre/post-processing steps, and model architectures using MAX Graphs API. Mojo brings the MAX platform together to deliver unparalleled performance and programmability for any hardware.
Here is how they all fit together. We’ll dive deeper into each component in the next section.
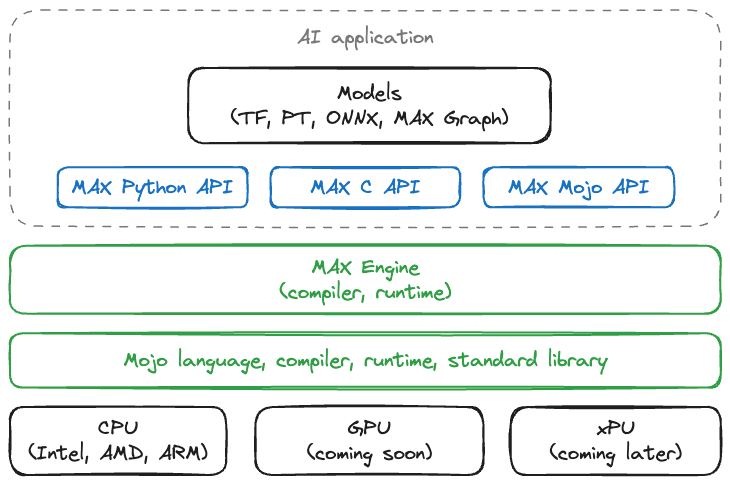
This initial release of the MAX SDK supports Ubuntu 20.04/22.04 LTS on Intel and AMD x86-64 CPUs, and AWS Graviton3 CPU ARM CPUs. We will expand to additional operating systems, hardware, and tool features in upcoming releases. To install MAX SDK head over to the install instructions in the MAX documentation.
MAX Engine
MAX Engine consists of the MAX compiler and runtime library, and Python, C and Mojo APIs to interact with it. It also comes with the max CLI convenience tool that makes it easy to benchmark models and visualize graphs.
To help you get started with MAX, we’ve added a number of getting started examples on GitHub, which you can get access by cloning the MAX examples repository:
To run a simple benchmark run:
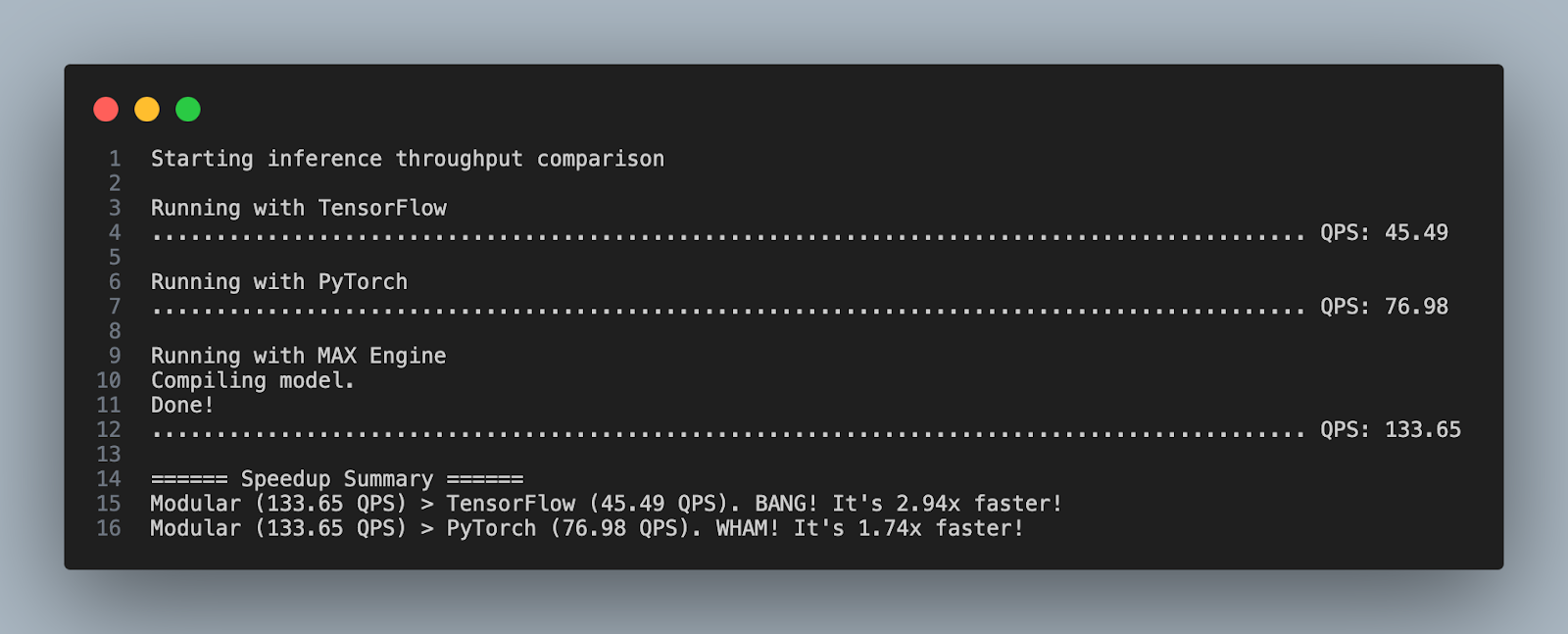
Running MAX Engine inference on roberta model on an Amazon EC2 c6i.4xlarge instance is 2.94x faster than TensorFlow and 1.74x faster than PyTorch, right out of the box!
To run more examples you can use the convenience console.py script in the examples directory script
To run a simple benchmark run:

To learn how the examples are written or modify it to adapt it for your workflows, head over to the relative paths for each script shown in the console table. You can also use the max CLI tool to run benchmarks on your models and visualize models using the netron app.
MAX Engine APIs
MAX Engine supports APIs for Python, C and Mojo enabling you to integrate MAX Engine compiler and inference runtime into a variety of applications. The APIs are very simple and straightforward to use. For example, MAX Engine Python API is only 3 lines of code to optimize the model:
And 1 line of code to execute it:
Let’s plug these 4 lines of code into an end-to-end example which downloads a ResNet50 model using Keras, saves it and runs it using MAX Engine, and prints the results. We’ll classify an image of a turtle that’s already in the MAX examples repository that we cloned earlier. You can find same script on GitHub.
Output:
As you can see, using the MAX Engine API is very straightforward and blends in with your existing workflows. You can similarly use Mojo API for even more flexibility and higher-performance when integrating with authoring pre-/post processing and data loading steps in Mojo. Take a look at the stable diffusion example implemented end-to-end using the MAX Engine and Mojo where the text encode, image decoder and image diffuser models are executed with MAX Engine along with a high-performance tokenizer written in Mojo. You can take this further and optimize end-to-end graphs in MAX Engine by using the MAX Graph API as we’ll see in the next section.
MAX Graph APIs
MAX Graph APIs enable you to define end-to-end models, pre-processing and post-processing steps as part of a graph using predefined operators. With no other dependencies, the entire graph will be executed directly by the MAX Engine for improved runtime performance. MAX Graphs are completely portable and don’t need to be rewritten for different hardware.
MAX Graphs are lazily-executed and graph operations can’t be called eagerly, they have to be compiled using MAX Engine to be executed. MAX examples repository has an example of llama2.🔥 implementation using MAX Graph APIs. Let’s take a look at what the Graph API looks like for a very basic graph:
In the code above, we first initialize the graph called basic_add with two int32 Tensor (TypeTuple(MOTensor(DType.int32), MOTensor(DType.int32))) and one return arguments of Type Tensor (MOTensor(DType.int32)). The graph contains a single operator called mo.add which we define using the g.op() function. It also takes in the two input Tensors to add and return the result. Visit the Graph API documentation page to learn more.
MAX Serving
MAX Serving is a deployment solution for MAX Engine that works as a drop-in replacement for your existing server-side inferencing runtime. It doesn't require any changes to your client programs. It implements KServe APIs so you can continue sending inference requests to the cloud with the same APIs you already use.
We’ve created a Docker container that includes MAX Serving (Triton and MAX Engine), which you can either download and run, or build yourself from a Dockerfile. Let’s take a look at how you can easily test your models in a serving environment.
Note: Currently, MAX Serving is available only for local development, as part of the MAX Developer Edition. It is not currently licensed for production deployment, but that's coming soon in the Enterprise Edition.
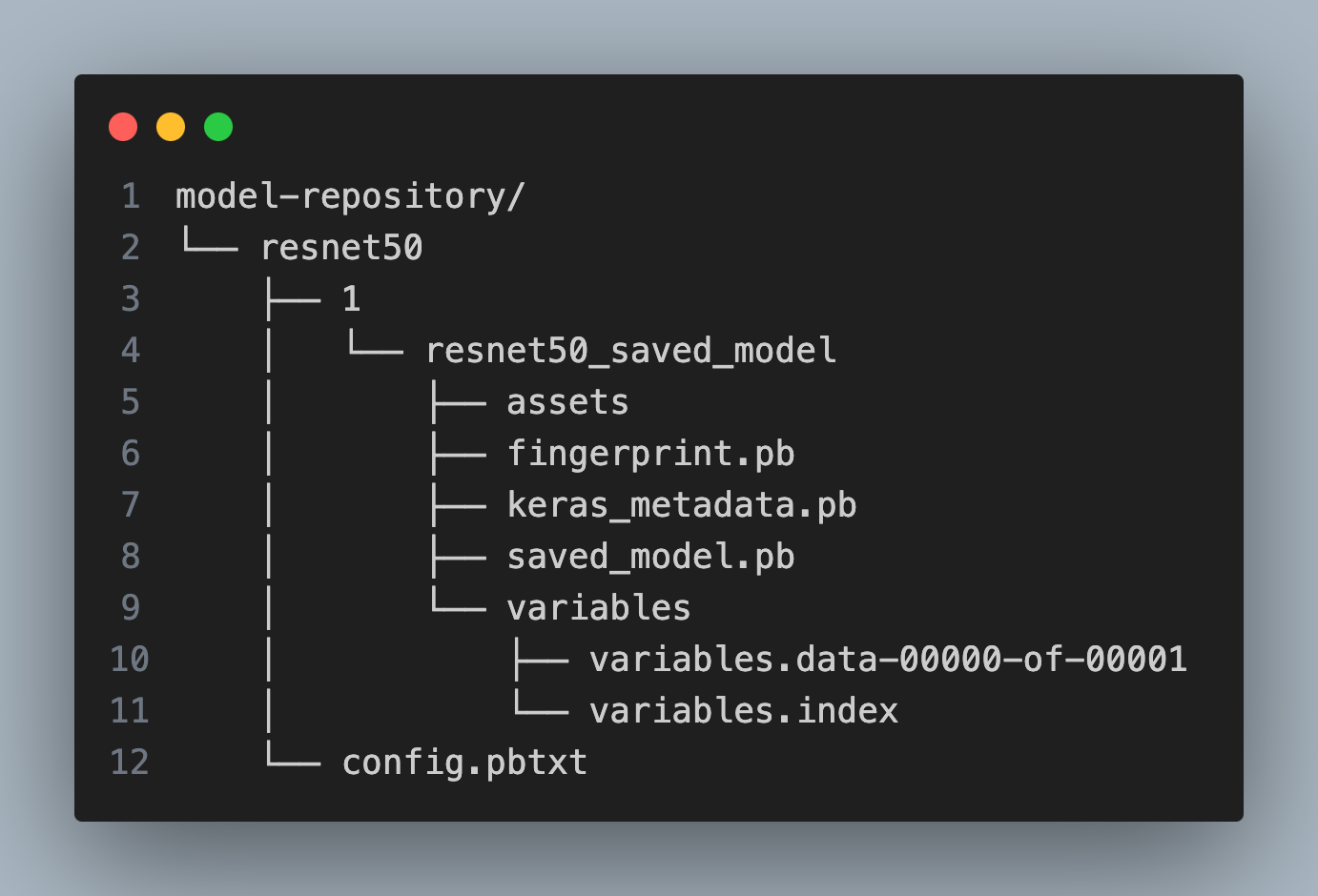
Building on top of our earlier example, let’s prepare our resnet50 model for deployment. Create model-repository directory and copy over the saved model directory to model-repository > resnet50 > 1 > resnet50_saved_model. The directory structure should look like this:
Using the pre-build Docker container image provided you can easily deploy your model with MAX Serving using the following script which includes the model-repository directory name and the specific model we want to deploy. You can find the script below on GitHub.
Once the Docker container is running, you can send inference requests from an HTTP/gRPC client via tritonclient,

Now run the following script to submit inference requests and get results back. You can find this script on GitHub.
Output:
You can see that the results match our example in the MAX Engine section. In this case, the request went over the network to the serving framework, through the MAX Engine runtime, and round-trip back to the client. MAX Serving container in the Developer Edition is a great way to test your end-to-end serving workflows.
What’s new in Mojo SDK v24.1?
MAX 🤝 Mojo
With the release of MAX Developer Edition, Mojo is now included as part of the MAX SDK. In preparing the MAX release, we recognized the pivotal role Mojo plays in MAX in authoring high-performance inference pipelines. Consequently, we opted to bundle Mojo within the MAX package for a few reasons.
- Improved User Experience (UX): A single package for MAX and Mojo, eliminating version mismatches or complexities.
- Seamless Integration: Mojo is intricately woven into MAX Engine APIs and maintaining identical versions of MAX and Mojo ensures seamless integration and functionality.
- Streamlined Version Management: By consolidating MAX and Mojo into a unified package, we avoid the need for users to manage multiple versions independently. Both follow a YY.MAJOR.MINOR version scheme. This also simplifies our software delivery process.
This doesn’t change the way you use Mojo today or moving forward. Read more about our reasoning behind this change in our blog post: MAX is here! What does that mean for Mojo🔥?
Today’s release of Mojo SDK v24.1 includes a slew of exciting features in the core language and standard library. We’ll do a dedicated blog post diving deep into a list of new features, changes and bug fixes, in the meantime check out the changelog. Below we’ll call out a few exciting additions to the Mojo developer experience.
Mojo debugging support is here!
The official extension on the Visual Studio Marketplace already supports a number of developer productivity features such as syntax highlighting, diagnostics, fixits, definitions, references, code completion and more. Starting today, debugging support is now officially part of that list!

You can now get interactive debugging experience in Visual Studio Code and via the LLDB command line interface. Mojo’s debugger is able to seamlessly debug hybrid Mojo/C/C++ code in the same debug session, empowering developers even further when working with highly specialized code. Learn more about Mojo Debugging in the documentation.
New Mojo Playground Experience
We launched Mojo Playground, a hosted set of Mojo-supported Jupyter notebooks, on May 2nd 2023 when we first announced Mojo to the world. Since then, we’ve released a downloadable Mojo SDK for Mac and Linux, used by thousands of developers worldwide. We’re excited to announce that the playground is now more tightly integrated into the documentation experience. Head over to MAX documentation > Mojo > Playground to experience the evolution of Mojo playground.

Note: We will be turning down the Mojo Playground (based on Jupyter) on March 20th, 2024. If you have any notebooks you would like to save, please download them with the File→Download option we provided in the playground.
MAX ♥️ Modverse Community
Since our launch of Mojo🔥programming language last year in May 2023, our developer community has grown to more than 170k members worldwide. We’re thrilled to see all the exciting projects by Mogicians🪄worldwide. And can’t wait to see what amazing things the Modverse community will build with MAX DE.
Since releasing Mojo SDK to developers in September 2023, it has been downloaded 55K times, and the Modverse community on Discord has grown to over 21 thousand members from more than 150 countries.
We’re ever grateful for the amazing Mojo champions Aydyn, Lukas, Kent, Mitchell, and Maxim for dedicating their time, and the select group of community members for beta testing MAX DE and helping us iron out those rough edges.
We want to express sincere thanks to every member of our community for your support, feedback, enthusiasm, and commitment. 🙏
Onward and upward: MAX throttle 🚀
MAX Engine and Mojo unlock possibilities never seen before in AI and we are thrilled to see what you’ll build with MAX! Download MAX Developer Edition today! The entire team at Modular is hard at work continuing to build MAX and add features and platform support you’re looking for. We want to be transparent with our priorities and you can see our upcoming priorities and roadmap here
Mac and Windows users, we ♥️ you, stay tuned!
For enterprise developers, a commercially-licensed Enterprise Edition is in the works. The Enterprise Edition will allow you to seamlessly test and deploy the same MAX components you've downloaded in the Developer Edition into a production environment. If this is you, reach out to us!
Finally, join us on our upcoming Modular Community Livestream: MAX DE Edition on Thursday, March 7th at 11 AM PT! Attend to learn more about MAX DE and get your questions answered directly from Modular engineers.
We’re just getting started! Here are other ways to learn more and get involved:
- Get started with downloading MAX
- Download and run MAX examples on GitHub
- Head over to the MAX docs to learn more about MAX Engine APIs and Mojo programming manual
- Join our Discord community
- Contribute to discussions on the Mojo and MAX GitHub
- Report feedback, including issues on our MAX and Mojo GitHub tracker


