.png)

Modular was founded on the vision to enable AI to be used by anyone, anywhere. We have always believed that to achieve this vision, we must first fix the fragmented and disjoint infrastructure upon which AI is built today. As we said 2 years ago, we imagine a different future for AI software, one that rings truer now than ever before:
Our success means global developers will be empowered by access to AI software that is truly usable, portable, and scalable. A world where developers without unlimited budgets or access to top talent can be just as efficient as the world’s largest technology giants, where the efficiency and total cost of ownership of AI hardware are optimized, where organizations can easily plug in custom ASICs for their use cases, where deploying to the edge is as easy as deploying to a server, where organizations can use any AI framework that best suits their needs, and where AI programs seamlessly scale across hardware so that deploying the latest AI research into production “just works”.
And today, we’re so excited to take a huge step towards that brighter future by announcing that the Modular Accelerated Xecution (MAX) Platform is now globally available, starting first as a preview on Linux systems. MAX is a unified set of tools and libraries that unlock performance, programmability and portability for your AI inference pipelines. Each component of MAX is designed to simplify the process of deploying models to any hardware, delivering the best possible cost-performance ratio for your workloads.
What’s included with MAX?
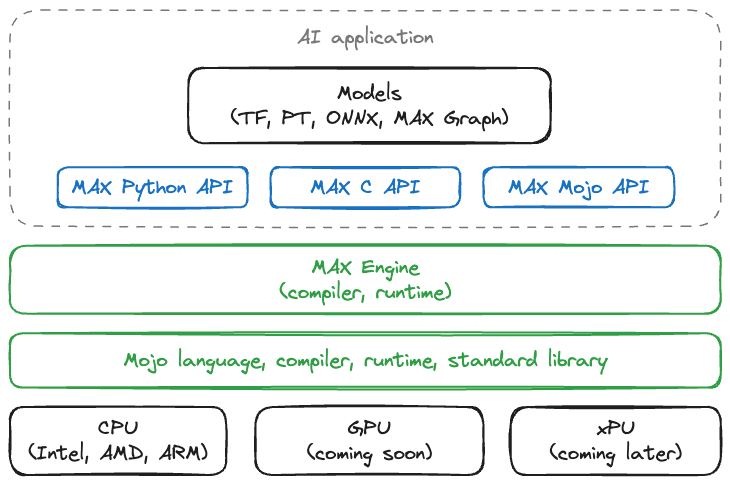
MAX is engineered to cater to the demanding needs of AI deployment, giving you everything you need to deploy low-latency, high-throughput, real-time inference pipelines into production. This first release of MAX ships with three key components:
- MAX Engine: A state-of-the-art AI compiler and runtime system supporting PyTorch, TensorFlow, and ONNX models like Mistral, Stable Diffusion, Llama2, WavLM, DLMR, ClipVit and many more. It delivers unmatched inference speed across diverse hardware platforms, and we’re just getting started.
- MAX Serving: An efficient serving wrapper for the MAX Engine, ensuring seamless interoperability with current AI serving systems like NVIDIA Triton, and smooth deployment to container ecosystems such as Kubernetes.
- Mojo🔥: The world’s first programming language built from the ground up for AI development, with cutting-edge compiler technology that delivers unparalleled performance and programmability on any hardware.
MAX gives developers superpowers, providing them with an array of tools and libraries for building high-performance AI applications that can be efficiently deployed across multiple hardware platforms.
How do I use MAX?
MAX is built to meet AI developers where they are today. It provides an instant boost in performance for your current models and seamlessly integrates with your existing toolchain and serving infrastructure, capturing the immediate value and performance improvements of MAX with minimal code changes. Then, when you're ready, you can extend MAX to support other parts of your AI pipeline and achieve even more performance, programmability, and portability.
Quick performance & portability wins
MAX compiles and runs your existing AI models across a wide range of hardware, delivering immediate performance gains. Getting started is as simple as using our Python or C API to replace your current PyTorch, TensorFlow, or ONNX inference calls with MAX Engine inference calls.
By changing only a few lines of code, your models execute up to 5x faster, supercharging latency so you can productionize larger models while improving efficiency to significantly reduce compute costs compared to stock PyTorch, TensorFlow, or ONNX Runtime. And the MAX Engine provides full portability across a wide range of CPU architectures (Intel, AMD, ARM), with GPU support coming soon. This means you can seamlessly move to the best hardware for your use case without rewriting your model.
Additionally, you can wrap the MAX Engine with MAX Serving as a backend to NVIDIA Triton Inference Server for a production-grade deployment stack. Triton provides gRPC and HTTP endpoints, efficiently handling incoming input requests.
Extend & optimize your pipeline
Beyond executing existing models with MAX Engine, you can further optimize your performance with MAX’s unique extensibility and programmability capabilities. MAX Engine is built using Mojo, and it is also fully extensible by you in Mojo. Today, the MAX Graph API enables you to build whole inference models in Mojo, consolidating the complexity that popular “point solution” inference frameworks like llama.cpp provide - delivering better flexibility and better performance. Coming soon you will even be able to write custom ops that can be natively fused by the MAX Engine compiler into your existing model graph.
Beyond model optimization with MAX Engine, you can further accelerate the rest of your AI pipeline by migrating your data pre/post-processing code and application code to Mojo, using native Mojo with the MAX Engine Mojo API. Our north star is to provide you with a massive amount of leverage, so you can get innovations in AI into your products faster.
How does MAX work?
The foundation of MAX is Mojo, a common programming model for all AI hardware that aims to unify the entire AI stack, from graph kernels up to application layer, and provide a portable alternative to Python, C, and CUDA.
MAX Engine uses Mojo transparently to accelerate your AI models across a variety of AI hardware via a state-of-the-art compiler and runtime stack. Users can load and optimize existing models from PyTorch, TensorFlow, and ONNX with MAX Engine’s Python and C bindings, or build their own inference graphs using the Mojo Graph API. Additionally, we’ve made it easy to use MAX Serving to quickly integrate and support your existing inference serving pipelines.
Because the internals of MAX are built in Mojo, you can always write native Mojo to further optimize the rest of your AI pipelines, including massively accelerating your pre- and post-processing logic and finally removing Python out of your production AI serving systems.
A better developer experience
In addition to the preview release of the MAX Platform, we are also excited to announce the release of many enhancements to the MAX developer experience. These include:
- MAX Examples Repo: The MAX GitHub repository provides plenty of rich examples of how to use MAX in practice. This includes inference examples for PyTorch and TensorFlow models with the MAX Engine Python and C APIs as well as a llama2.🔥 model developed with the Graph API.
- New Documentation Site: Rebuilt from the ground up, our new documentation site features blazing fast search, better categorization and structure, richer code examples, and enhanced developer usability everywhere. Not to mention new tutorials for all the new MAX features!
- New “Playground” experience for Mojo: Our new Mojo coding playground is perfect for early learnings and quick experimentation. You can start executing Mojo code within seconds and easily share it with your friends via Gist.
- New Developer Dashboard: We’ve revamped and updated our Developer Dashboard, enabling you to access updates, the performance dashboard, and our MAX Enterprise features soon.
- … and much more: There have been product improvements and fixes across almost every surface, and we’ll continue rapidly iterating to deliver world class AI infrastructure for developers everywhere.
There’s more to come!
All of this is available today in the MAX Developer Edition preview. We’re excited to launch this release, have MAX go global, and see what you build with it. While this is just our first preview release of MAX, we have many plans for subsequent releases in the near future: Mac support, enterprise features, and GPU support is all on the way. Please see our roadmap for more information.
To learn more about MAX, and get involved with the Modular community:
- Download the MAX Developer Edition preview for Linux.
- Read our Getting started with MAX Developer Edition blog post
- Read our blog post on future of Mojo and MAX: MAX is here! What does that mean for Mojo🔥?
- Connect with users and devs in our Discord community.
- Contribute to discussions on the MAX and Mojo GitHub
- Report feedback, including issues on our MAX and Mojo GitHub tracker.
We know this is just the beginning, and we’re excited to get out this release, listen and take in your feedback as we quickly iterate to improve MAX for the world. We’re on a mission to help push AI forward for the world, and enable AI to be used by anyone, anywhere - join us!
Onwards!
The Modular Team


