Blog


.png)

Democratizing AI Compute Series
Go behind the scenes of the AI industry with Chris Lattner
Latest

Modular 25.7: Faster Inference, Safer GPU Programming, and a More Unified Developer Experience
Today, we’re excited to release Modular Platform 25.7, an update that deepens our vision of a unified, high-performance compute layer for AI. With a fully open MAX Python API, an experimental next-generation modeling API, expanded hardware support for NVIDIA Grace superchips, and a safer, more capable Mojo GPU programming experience, this release moves us closer to an ecosystem where developers spend less time fighting infrastructure and more time advancing what AI can do.

PyTorch and LLVM in 2025 — Keeping up With AI Innovation
Along with several teammates, I had the privilege of attending two recent developer events in the AI software stack: PyTorch Conference 2025 (October 22-23) in San Francisco and LLVM Developers' Meeting (October 28-29) in Santa Clara. In this post, I’ll share some observations that stood out among all the conference sessions and conversations I had with developers.

Achieving State-of-the-Art Performance on AMD MI355 — in Just 14 Days
In late August, AMD and TensorWave reached out to collaborate on a presentation for AMD’s Media Tech Day—they asked if we could demo MAX on AMD Instinct™ MI355 on September 16th. There was just one problem: no one at Modular had access to an MI355.


Modular 25.6: Unifying the latest GPUs from NVIDIA, AMD, and Apple
We’re excited to announce Modular Platform 25.6 – a major milestone in our mission to build AI’s unified compute layer. With 25.6, we’re delivering the clearest proof yet of our mission: a unified compute layer that spans from laptops to the world’s most powerful datacenter GPUs. The platform now delivers:

Matrix Multiplication on Blackwell: Part 4 - Breaking SOTA
In this blog post, we’ll continue our journey to build a state-of-the-art (SOTA) matmul kernel on NVIDIA Blackwell by exploring the cluster launch control (CLC) optimization. At the end of the post we’ll improve our performance by another 15% and achieve 1772 TFLOPs, exceeding that of the current SOTA.
.png)
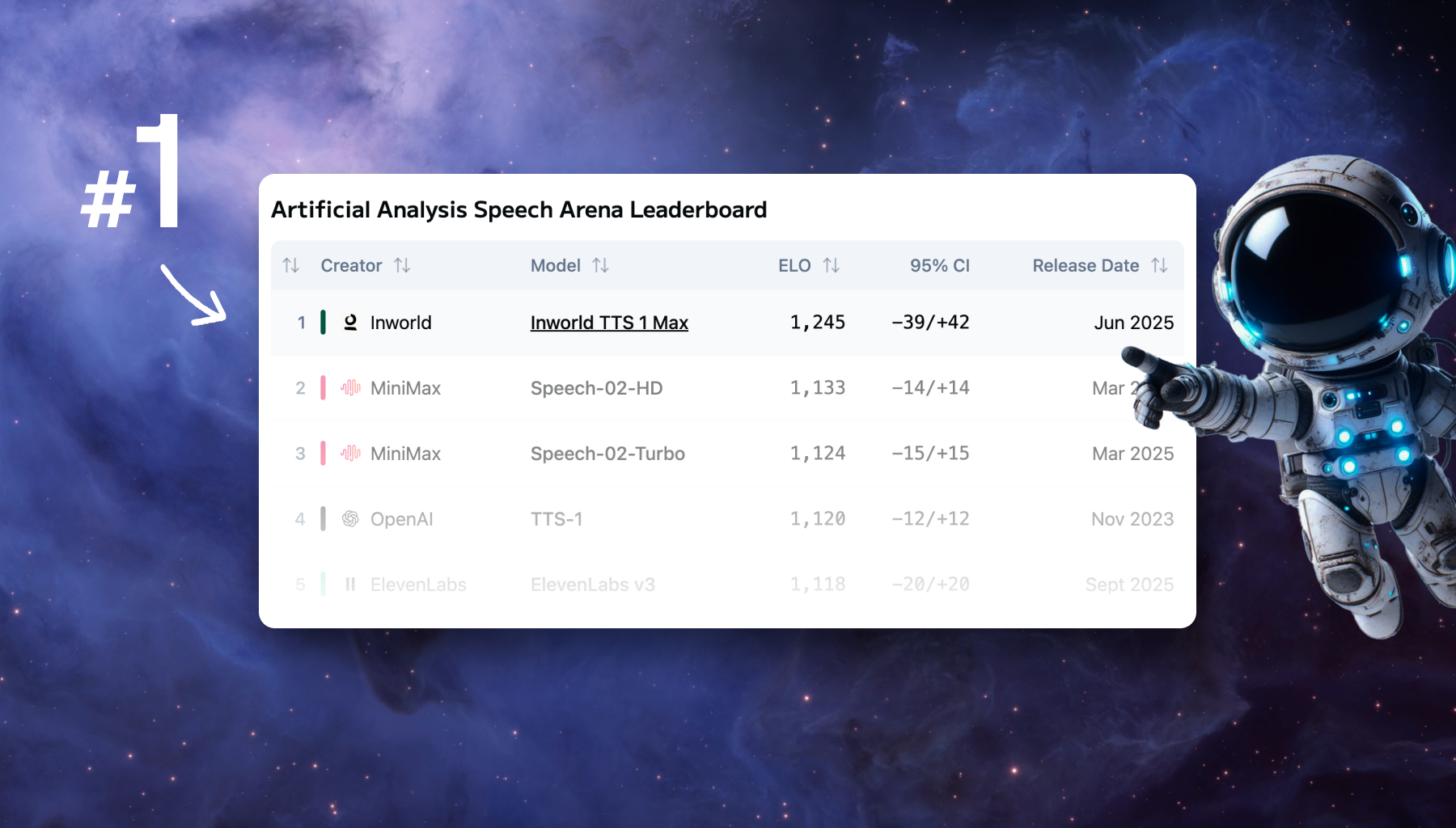
Modverse #51: Modular x Inworld x Oracle, Modular Meetup Recap and Community Projects
The Modular community has been buzzing this month, from our Los Altos Meetup talks and fresh engineering docs to big wins with Inworld and Oracle. Catch the highlights, new tutorials, and open-source contributions in this edition of Modverse.


Matrix Multiplication on Blackwell: Part 2 - Using Hardware Features to Optimize Matmul
In this post we are going to continue our journey and improve our performance by more than 50x our initial kernel benchmark. Along the way we are going to explain more GPU programming concepts and leverage novel Blackwell features.
No items found within this category
We couldn’t find anything. Try changing or resetting your filters.

Get started guide
Install MAX with a few commands and deploy a GenAI model locally.
Read Guide
Browse open models
500+ models, many optimized for lightning-fast performance
Browse models