
.png)

GPU programming doesn't have to be this hard
GPU programming has always demanded precision, but the cost of that precision keeps rising. A production matmul kernel written in C++ spans 3,000–5,000 lines of tightly coupled code where a misplaced barrier silently corrupts results. That complexity gatekeeps hardware that should be available to far more developers, and it's a direct product of how GPUs have evolved: with each architecture generation, more of the orchestration burden has shifted onto the programmer.
DSLs like Triton improve accessibility, but at a real cost. When you need peak utilization for inference at scale, you eventually have to drop below the abstraction layer, at which point you've surrendered the productivity benefit the DSL offered in the first place. For a deeper look at this tradeoff, see our post on Python eDSLs.
Frameworks like CUTLASS and CuTe take the opposite approach: expose everything. The result is 500K+ lines of C++ template machinery, a Python DSL layer with restricted control flow (no break, no return from loops), error messages that require archaeology through multiple abstraction layers, and NVIDIA lock-in. You get peak performance, but the framework becomes the complexity problem.
Mojo was designed to break this tradeoff. The language gives you direct access to the full hardware stack (we covered this in depth in our four-part series on Blackwell performance) while also enabling compile-time metaprogramming powerful enough to support high-level abstractions with no runtime cost.
Structured Mojo Kernels are the practical result. They are a set of APIs built around separation of concerns: modular components with clean interfaces that make GPU kernels more productive to write and easier to maintain, without giving anything back on performance. The rest of this post shows you exactly how they work.
The solution: structured kernel architecture
Structured Mojo Kernels organize kernel logic into three core components, unified by a shared configuration layer and a shared data management layer.
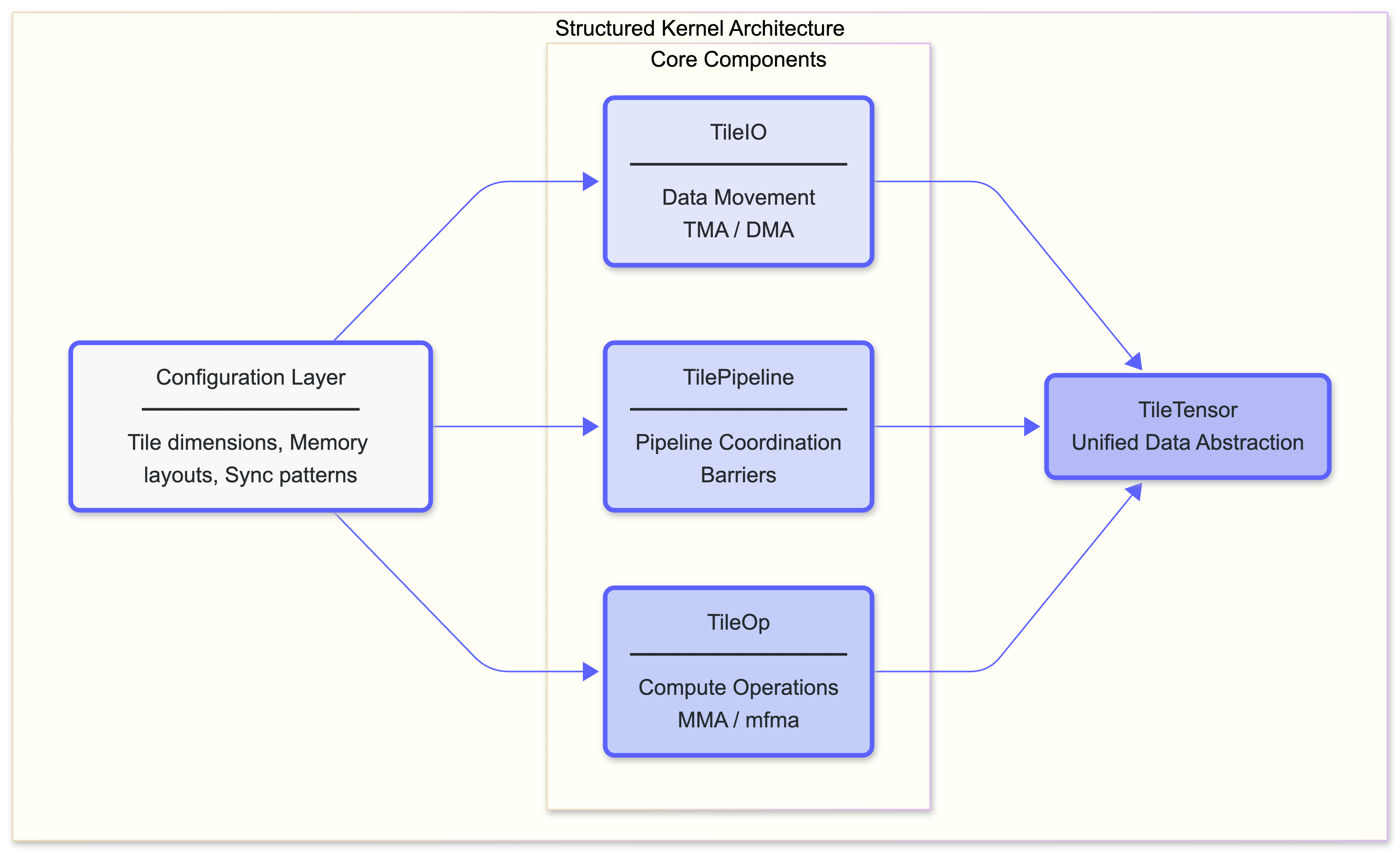
Each component has a single responsibility and well-defined interfaces:
| Component | Responsibility | Encapsulates |
|---|---|---|
| TileIO | Moves data between memory levels. Acts as a producer to TilePipeline. | TMA/DMA, layout transforms, swizzling |
| TilePipeline | Coordinates pipeline stages, and manages shared memory. | Barriers, producer-consumer sync |
| TileOp | Executes compute operations. Acts as a consumer to TilePipeline. | MMA instructions, register management |
Note that these are pattern names, not library APIs. The concrete implementations (InputTilePipeline, OutputTilePipeline, and their counterparts) live in the open-source kernels library and follow these patterns.
Separation of concerns keeps each component tractable:
- TileIO doesn't know about compute operations.
- TilePipeline doesn't know about memory layouts.
- TileOp doesn't know about global memory.
If this sounds like basic software engineering, that's the point. The reason it matters here is that conventional GPU kernel development doesn't work this way. A CUTLASS kernel interleaves pipeline coordination, compute logic, and data movement throughout thousands of lines. The same is true for hand-written CUDA or HIP kernels. Structured Mojo Kernels bring the same separation of concerns that every other domain of software treats as a baseline requirement.
The power of separation
In conventional kernel development, adding block-scaled quantization means writing a separate 1,500-line kernel. Those lines are mostly adapted from the existing kernel, with changes scattered throughout. There’s no natural seam to cut along because pipeline coordination, compute logic, and data movement are all interleaved.
With structured components, those changes are almost all localized in a single place: the “payload” structure representing the data passed between the components.
The pipeline coordination (TilePipeline), compute logic (TileOp), and data movement patterns (TileIO) didn’t need to change because they're properly decoupled.
The same principle scales to entirely different kernel types. We recently built an SM100 convolution kernel by swapping a single component (replacing the standard TMA tile loader with an im2col-aware variant) and reusing the entire matmul infrastructure: pipelines, MMA warp context, epilogue, scheduler, and output writer. In CUTLASS, the equivalent conv kernel is a separate 870-line file largely duplicated from the matmul kernel. With structured components, the conv-specific code is ~130 lines.
What this replaces
To see why structure matters, here’s what pipeline setup looks like in a real CUTLASS SM100 kernel. The kernel must initialize 6 separate pipeline objects, each with explicit role assignment, arrival counts, transaction bytes, and barrier configuration:
In structured Mojo kernels, role assignment and arrival counts are encoded in compile-time parameters, eliminating them from the kernel body entirely. The same pipeline setup that required 100+ lines of explicit configuration in CUTLASS becomes:
The type system carries the configuration. No role assignment, no arrival counts in the kernel body, no state variables to track.
Context managers replace manual protocol
The biggest source of bugs in GPU kernels is pipeline synchronization. In the CUTLASS MMA warp, the programmer manually allocates TMEM, acquires and commits pipeline stages, and handles a multi-step deallocation sequence:
Every producer_acquire must pair with a producer_commit. The cleanup sequence (lock release, tail signal, peer sync, free) must happen in exact order. Miss any step and you get a silent hang.
In structured Mojo kernels, context managers make incorrect synchronization unrepresentable:
The with mma_ctx: block handles the entire TMEM lifecycle. The nested with blocks handle output pipeline producer staging, input pipeline consumer stepping, and per-tile barrier acquire/release. There are no manual acquire/commit pairs to get wrong; the compiler enforces correct ordering.
Why this needs Mojo
Mojo's compile-time metaprogramming and RAII patterns ensure these abstractions leave no runtime trace; the generated assembly is identical to hand-written code.
This combination is what makes “structured” possible without “slow.” CUTLASS achieves similar goals with C++ templates but at the cost of enormous framework complexity and impenetrable error messages. Triton achieves productivity but can’t express the low-level control needed for peak performance. Mojo is currently the only language that combines full compile-time metaprogramming, guaranteed resource management, and first-class GPU support, enabling these abstractions with zero runtime cost.
How it compares
| CUTLASS / CuTe DSL | Structured Mojo Kernels | |
|---|---|---|
| Peak performance | Yes | Yes (~1770 TFLOPS on SM100) |
| Framework size | ~500K+ lines | ~7K lines |
| Platform support | NVIDIA only | NVIDIA + AMD |
| Pipeline safety | Manual (forget .commit() → hang) | Compile-time (context managers) |
| Error messages | C++ template archaeology | Line number + fix suggestion |
| Control flow | Restricted in DSL | Full (break, return, etc.) |
And here’s actual data from our updating our SM100 matmul kernel to use structured components:
| Metric | Conventional approach | Structured Mojo Kernels | Change |
|---|---|---|---|
| Total lines | 14,683 | 7,634 | -48% |
| Main kernel | 3,721 | 1,843 | -50% |
| Performance | ~1770 TFLOPS | ~1770 TFLOPS | Equal |
We cut the code nearly in half while maintaining identical performance. The compiled output is indistinguishable from a hand-written kernel so there is no abstraction overhead.
The payoff compounds when you build new kernels. Our SM100 conv2d required only ~130 lines of conv-specific code (an im2col tile loader and shared memory layout) while reusing the entire matmul infrastructure: pipelines, MMA warp context, epilogue, scheduler, and output writer. The CUTLASS equivalent is a separate 870-line kernel largely duplicated from their matmul kernel. That's the difference between separation of concerns and copy-paste.
When you do need to go lower, when a specific kernel demands something the structured components don't express, Mojo lets you. Nothing in this architecture prevents you from writing directly to the hardware. The difference is that you'll rarely need to, and when you do, you'll be modifying a codebase that's half the size and considerably easier to reason about.
What's next
This post introduced the architecture and the motivation. The next three posts get into the specifics:
- Part 2: The Three Pillars. TileIO, TilePipeline, and TileOp explained with real code: how each component works, why the interfaces are designed the way they are, and how they compose into a complete kernel.
- Part 3: Composition in Practice. Extending the architecture for conv2d, block-scaled matmul, and other demanding kernel variants.
- Part 4: Portability and the Road Ahead. How the same structured patterns map onto NVIDIA Blackwell and AMD MI300X, and what changes when the underlying hardware does.
TL;DR
- Production GPU kernels are hard to write and harder to maintain. Modern hardware demands explicit software orchestration of pipelines, barriers, and memory. Existing frameworks respond with enormous complexity.
- Structured Mojo Kernels separate concerns. TileIO, TilePipeline, and TileOp each own one responsibility with clean interfaces between them. Changes stay localized. New kernel variants compose from existing components.
- Context managers eliminate synchronization bugs. The
withblocks that manage pipeline transitions make incorrect ordering unrepresentable in source code. - Zero-cost abstractions are real. Mojo’s compile-time metaprogramming and RAII patterns make the structure disappear at runtime. 48% less code, identical performance.
- Lightweight, portable, and open. ~7K lines of library code, runs on NVIDIA and AMD, available in the Modular repository.


