Our cloud.
Our compute.
Blazing fast inference.
Customize performance down to the kernel, while deploying seamlessly across accelerators without code rewrites.
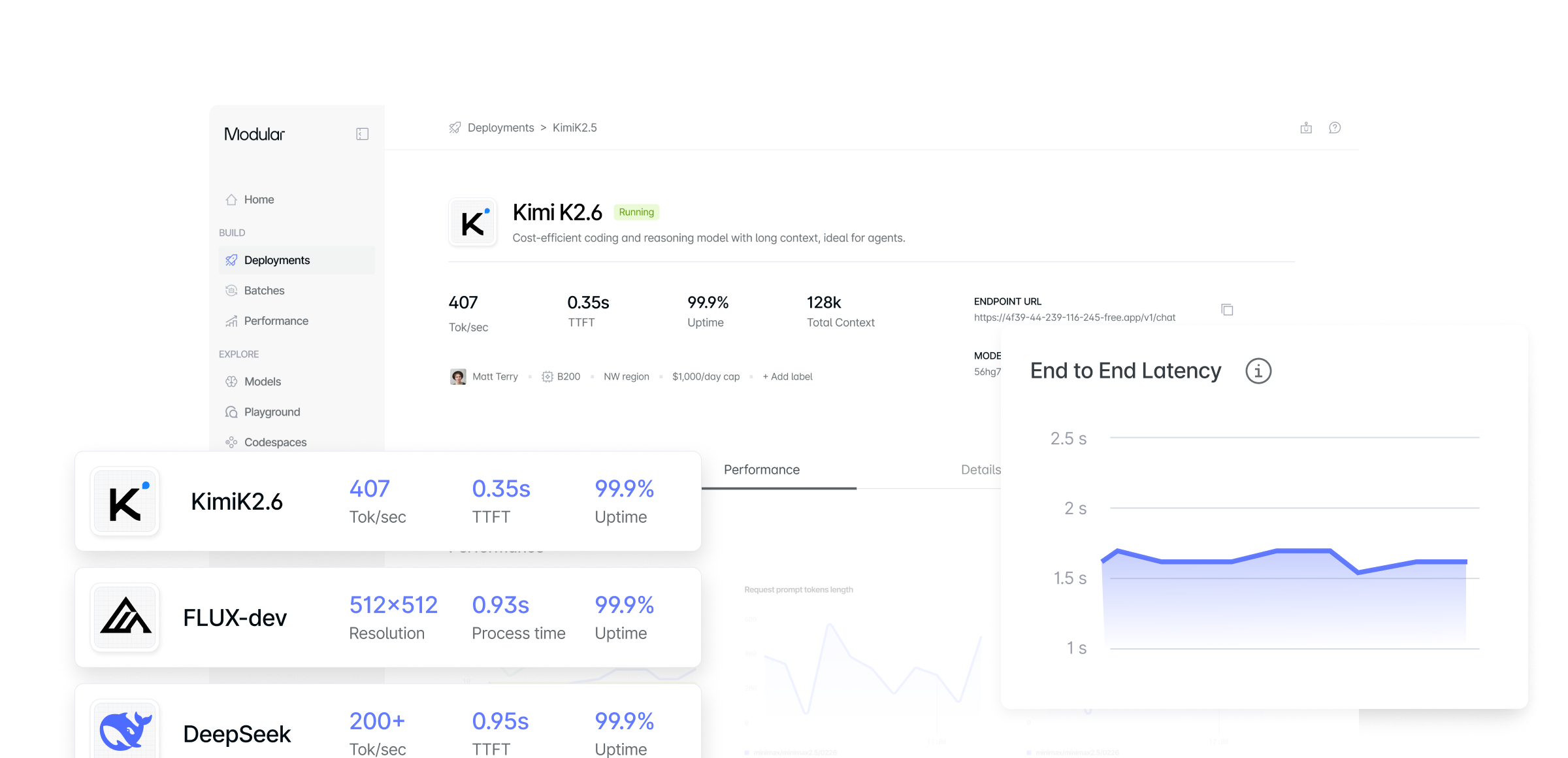

Full stack control
From kernel to cloud on a single unified infrastructure stack. We’ve rebuilt AI from the ground up.

Full customization
Support for customer weights, models, and performance profiles.

Deep Observability
Low-level telemetry reveals bottlenecks and optimization opportunities.

Portability across accelerators
Seamlessly run on GPU hardware that gives you the best latency, throughput and price.
Modular acquired Bento
Modular is now even more powerfully and fully integrated with the amazing power of Bento’s production-hardened infrastructure. So now we’re offering the best of both, fully integrated. Modular’s full stack just got stronger!
Why Modular outperforms
Why choose Our Cloud?
No cluster provisioning, no kernel tuning, no GPU procurement. Push your model, pick your hardware, and serve production traffic through a single API. Modular Cloud handles orchestration, scaling, and optimization so your team stays focused on the product.
EX: STARTUPS, NEW AI PRODUCTS, RAPID PROTOTYPING
Per-minute pricing. AMD GPU support. Forward-deployed engineers who tune your batch size, kernel config, and GPU selection for your specific workload. The result is a cost structure proprietary API providers can't touch.
EX: HIGH-VOLUME INFERENCE, COST-SENSITIVE AI
Deploy fine-tuned or proprietary models on managed infrastructure with custom Mojo kernel support. Same capability as self-hosted, but without the operational overhead. Compiler optimization and GPU portability baked in.
EX: CUSTOM MODEL SERVING AT SCALE
OpenAI-compatible endpoints mean your existing code works on day one. Swap GPT for Llama, Qwen, or your own fine-tune - same API contract, better economics. Forward-deployed engineers help you tune the replacement.
EX: GPT TO LLAMA/QWEN MIGRATION

Managed simplicity + Self-hosted control. Pick both.
Modular eliminates the tradeoff, providing the simplicity of managed inference with engineering-level control.
Dedicated endpoints with predictable performance
Forward-deployed engineers optimizing your workloads
Compiler-level optimizations that fuse the entire inference graph
Custom kernel programmability in Mojo & Python
GPU portability across NVIDIA and AMD without rewriting code
No black boxes. No vendor lock-in. No operational burden.
Modular vs. the competition
 Hardware Portability
Hardware PortabilityGPU portability. NVIDIA + AMD in the same deployment, meaning more options and lower TCO.
- Embedded Performance Engineering
Forward-deployed engineers who write custom Mojo kernels, on top of BentoCloud’s proven scalable operations.
- Unified GPU Pricing
Simple pricing for $ / token for shared endpoints, and $ / minute for dedicated ones.
- Vertically Integrated Stack
SOTA dynamic cloud orchestration. Compiler-aware auto-scaling. MAX understands model memory, batching state, KV-cache. Mojo provides portable SOTA kernels.
- 10x Lighter Runtime
<700MB runtime. 10x faster cold starts. Simpler operations.
- Alternatives
 Vendor Lock-In
Vendor Lock-InNVIDIA-only. Zero GPU vendor choice across every managed cloud competitor.
- Generic Platform Optimizations
No per-customer engineering. No dedicated engineers on your account. Generic optimizations applied everywhere.
- Blackbox infrastructure & pricing
No visibility into quantization, batching, or what's been done to your model. You're paying for a black box.
- Runtime Wrappers
CUDA research (ATLAS, Megakernel). vLLM/TensorRT wrappers. Runtime optimization, not compilation.
- Multi-GB Runtime
7GB+ runtimes. Slow cold starts. Heavy container overhead.
Compare deployment options
Self-Hosted | Our Cloud | Your Cloud | |
|---|---|---|---|
Support | Active community and fast responses in Discord, Discourse, Github | Dedicated support, engineering team, standard and custom SLAs/SLOs | Dedicated support, engineering team, standard and custom SLAs/SLOs |
Models | Hundreds of models in our model repo, view top performers | Top performers available for dedicated endpoint, custom model deployment | Top performers available for dedicated endpoint, custom model deployment |
AI Skills | Use our open AI skills to easily write models, or optimize code | Our engineers can help train your team & migrate your workloads | Our engineers can help train your team & migrate your workloads |
Platform access | Deploy MAX and Mojo yourself anywhere you want. Build with open source | Access Modular Platform with a console for deploying, scaling and managing your AI endpoints. | Access Modular Platform with a console for deploying, scaling and managing your AI endpoints. |
Scalability | Scale on your own with the MAX container | Auto-scaling, scale to zero, burst capacity | Auto-scaling, proven at Fortune 500 scale. |
Deployment location | Self-deployed, anywhere | Our cloud | Your cloud or hybrid |
Compute hardware | NVIDIA, AMD, and Apple Silicon & more. Scaling restrictions apply. | NVIDIA & AMD GPUs in our cloud. More hardware coming soon. | NVIDIA & AMD GPUs, Intel, AMD & ARM CPUs - deployed in your cloud. |
Custom kernels | Your engineers write custom kernels for your workloads. | Modular engineers tune kernels for your workloads | Modular engineers write custom kernels for your workloads |
Forward Deployed Engineers | Available with support plan | Included | Included; working in your environment |
Security & Compliance | SOC 2 Type 2 certified | SOC 2 Type 2 certified | SOC 2 Type 2 certified |
Billing & Pricing | Free | Per token (shared) Per minute (dedicated) | Per minute deployed. Use your AWS/GCP/Azure credits and commits |
Enterprise Contract |
Get started with Modular
Schedule a demo of Modular and explore a custom end-to-end deployment built around your models, hardware, and performance goals.
Distributed, large-scale online inference endpoints
Highest-performance to maximize ROI and latency
Deploy in Modular cloud or your cloud
View all features with a custom demo

Book a demo
Talk with our sales lead Jay!
30min demo. Evaluate with your workloads. Ask us anything.
Book a demo for a personalized walkthrough of Modular in your environment. Learn how teams use it to simplify systems and tune performance at scale.
Custom 30 min walkthrough of our platform
Cover specific model or deployment needs
Flexible pricing to fit your specific needs
Book a demo
Talk with our sales lead Jay!
Start using MAX

( FREE )
Run any open source model in 5 minutes, then benchmark it. Scale it to millions yourself (for free!).
Install Mojo and get up and running in minutes. A simple install, familiar tooling, and clear docs make it easy to start writing code immediately.