




HTTP routing has been a solved problem for many years. Round-robin, consistent hashing, least-connections. Pick one, put it in front of a pool of identical servers, and the traffic spreads pretty evenly.
But then came Large Language Models.
The backends here aren't interchangeable web servers. They're GPU pods holding large, local KV caches in high-bandwidth, RAM or SSD memory. That state is expensive to rebuild, not uniformly available across the cluster, and often determines whether a request returns quickly or spends seconds recomputing previous work. Some pods might specialize in prefill, others in decode. Conversations typically stretch across requests. A single inference call sometimes needs two backends in sequence. The old assumptions about "interchangeable backends" and "independent requests" don't support these requirements.
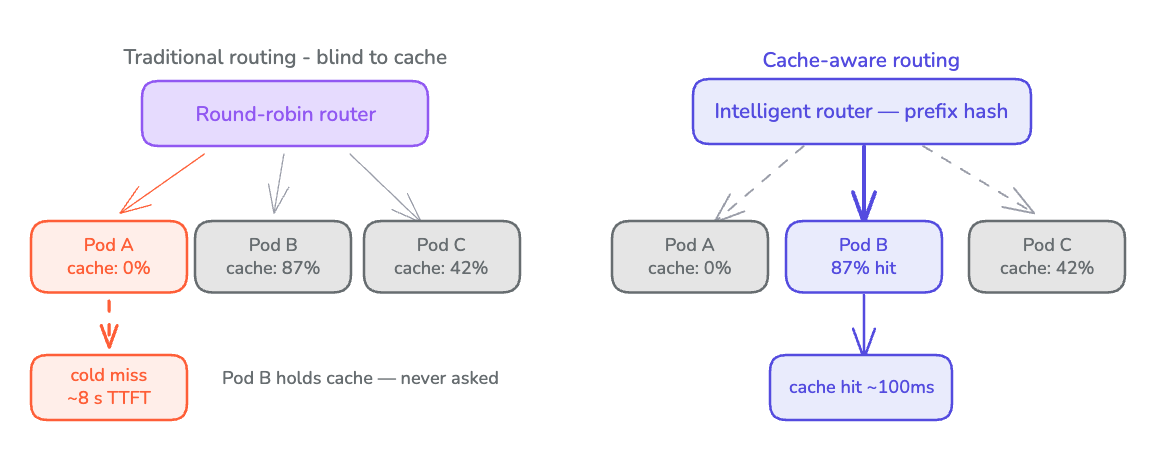
Traditional routing is blind to all of this. It treats every backend as interchangeable, every request as independent, every pod as equally good. GPU pods are none of those things. They’re stateful, specialized and heterogeneous. Inference routing has to account for that.
This is the first post in a three-part series about what routing has to become to handle inference workloads. Modular Cloud’s orchestration layer is built around this routing problem, and this series explains how it solves it.
Years of stateless routing
HTTP-era load balancing is built on a small menu of algorithms, each tuned to a specific deployment shape. They have different policies, but they share the same precondition: stateless backends.
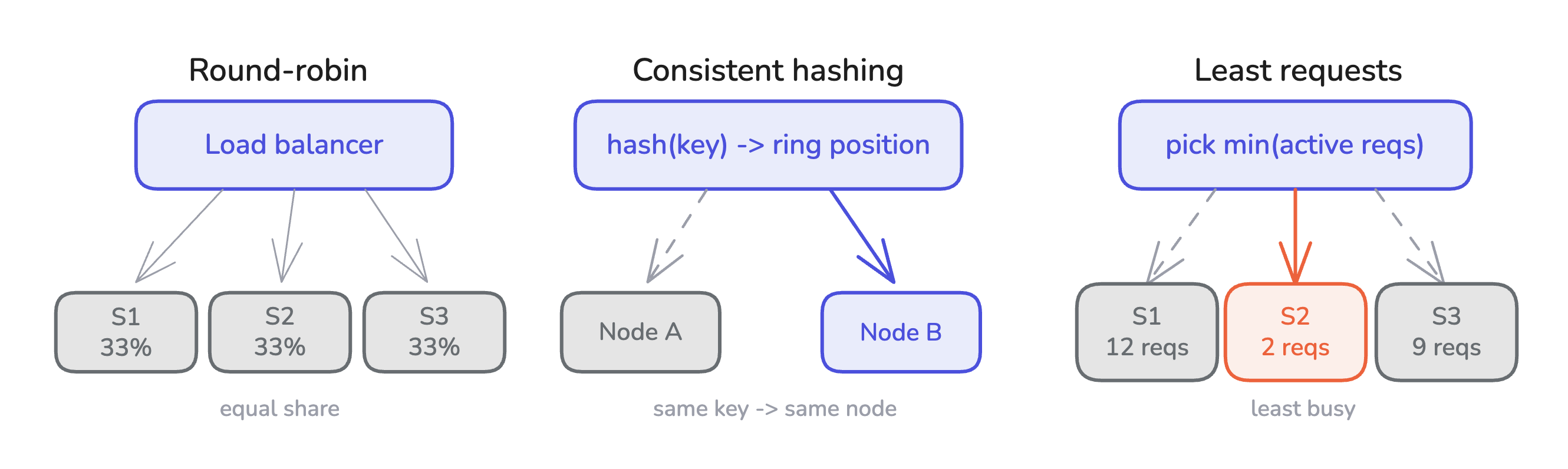
Round-robin distributes requests uniformly across a pool of identical backends. It assumes every backend serves every request at the same cost. This might look like eight replicas of the same web service behind a load balancer, each getting 12.5% of the traffic. It’s simple, fair, stateless.
Consistent hashing routes each request to a backend determined by hashing some property of the request (a key, url, session identifier), and picking the backend whose position on the hash ring is closest. It’s the routing strategy of choice when you want the same key to land on the same backend, for client-side caching or session affinity. The backend’s “stickiness” is a function of the request key, not of anything the backend is holding in memory.
Least-requests sends each new request to whichever backend has the fewest active requests, on the assumption that fewer active requests means more spare capacity. It works when every request takes roughly the same amount of work.
These policies share the same three assumptions:
- Any backend can serve any request. The assignment is a policy choice not a correctness one.
- Requests are independent. What happened on request N doesn’t change what you should do on request N+1.
- Backends are interchangeable. The load balancer can swap one for another without the client noticing.
Those assumptions hold for stateless web services. LLM inference breaks all three.
Where LLMs break the model
LLM workloads violate the stateless assumptions in four specific ways. Each one introduces a dimension that traditional routing has no mechanism to handle.
KV Cache State
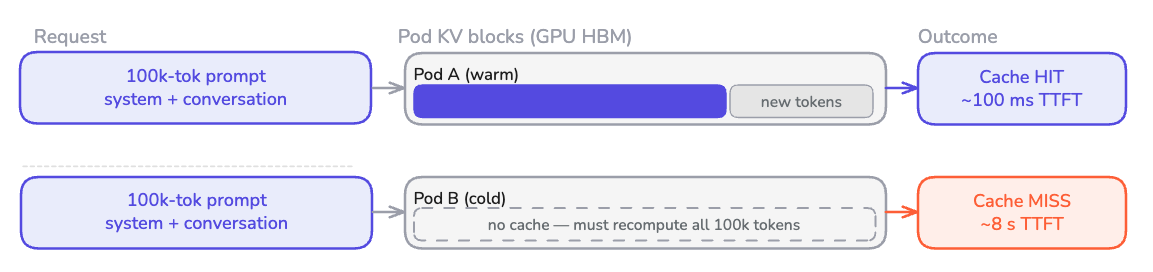
When a pod serves an inference request, the forward pass builds a KV cache: the model's intermediate state for every token position, held in GPU memory. Modern engines retain that cache after the response completes, so later requests sharing a prefix can skip the equivalent compute.
This changes the routing problem drastically. A 100K token prompt landing on a pod with the first 75K tokens already cached can prefill in milliseconds. The same prompt hitting a cold pod takes seconds. Round-robin, blind to cache state, would produce unpredictable time to first token (TTFT) for identical requests.
Cache state is the primary driver of prefill latency variance at scale. A router that selects pods based on cache residency eliminates prefill compute proportional to the shared prefix length for every hit. This frees up GPU cycles the cluster would otherwise spend recomputing work it has already done.
Hardware Specialization
LLM Inference has two phases, and they stress hardware differently.
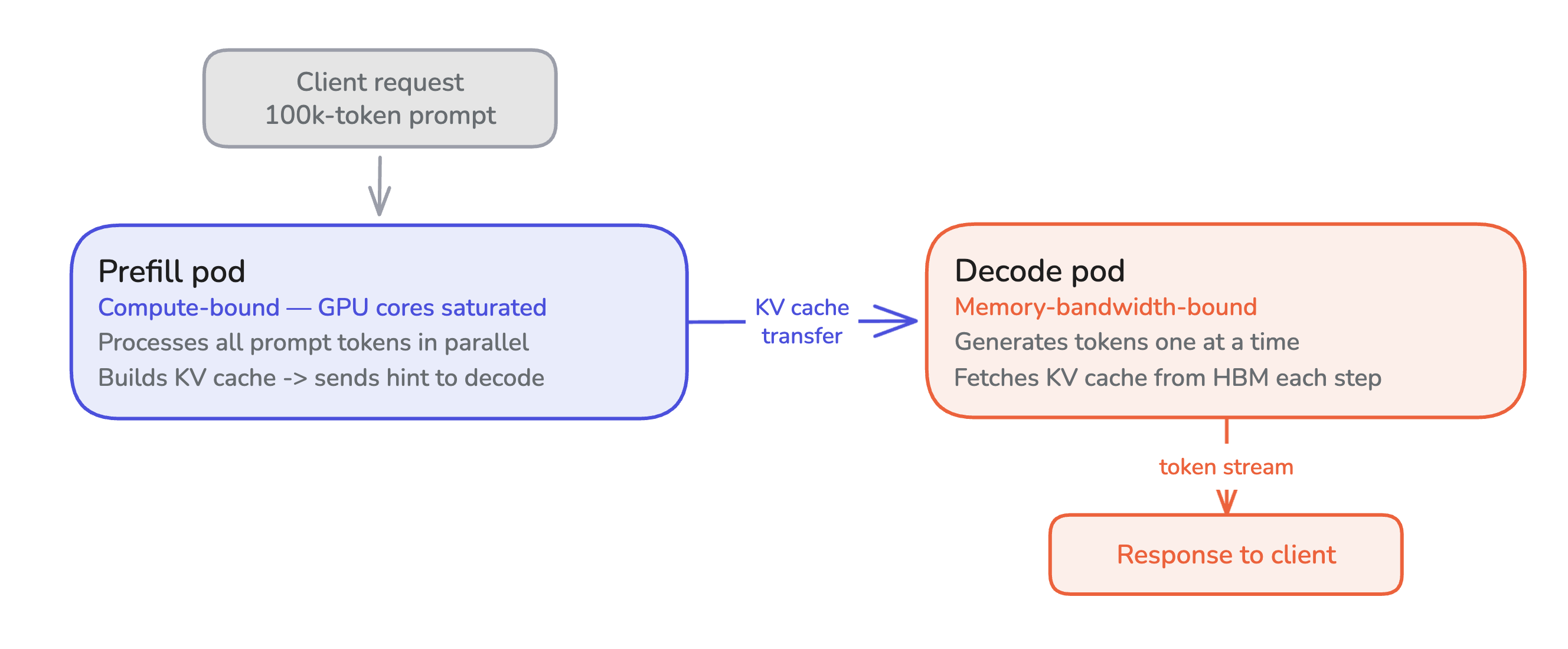
Prefill processes the entire prompt in parallel. It’s compute-bound. This means GPU cores are saturated doing dense matrix multiplications across thousands of tokens at once.
Decode generates tokens one at a time autoregressively, each token depending on every token before it. It’s memory-bandwidth-bound. This means most of the GPU’s time is spent fetching model weights and KV cache from high bandwidth memory (HBM), and most of the compute sits idle.
Running both phases on the same pod means the hardware is never tuned for either. Prefill needs dense compute; decode needs memory bandwidth. A pod optimized for one underutilizes what the other requires. Disaggregated deployments use pods tuned for each phase separately. A single client request divides work across both.
Modern engines use chunked prefill to interleave the two phases on the same pod, blurring the boundary. But the underlying compute-vs-bandwidth distinction still holds, and when you disaggregate at the deployment level, your router has to know which pod can do what.
Conversation continuity
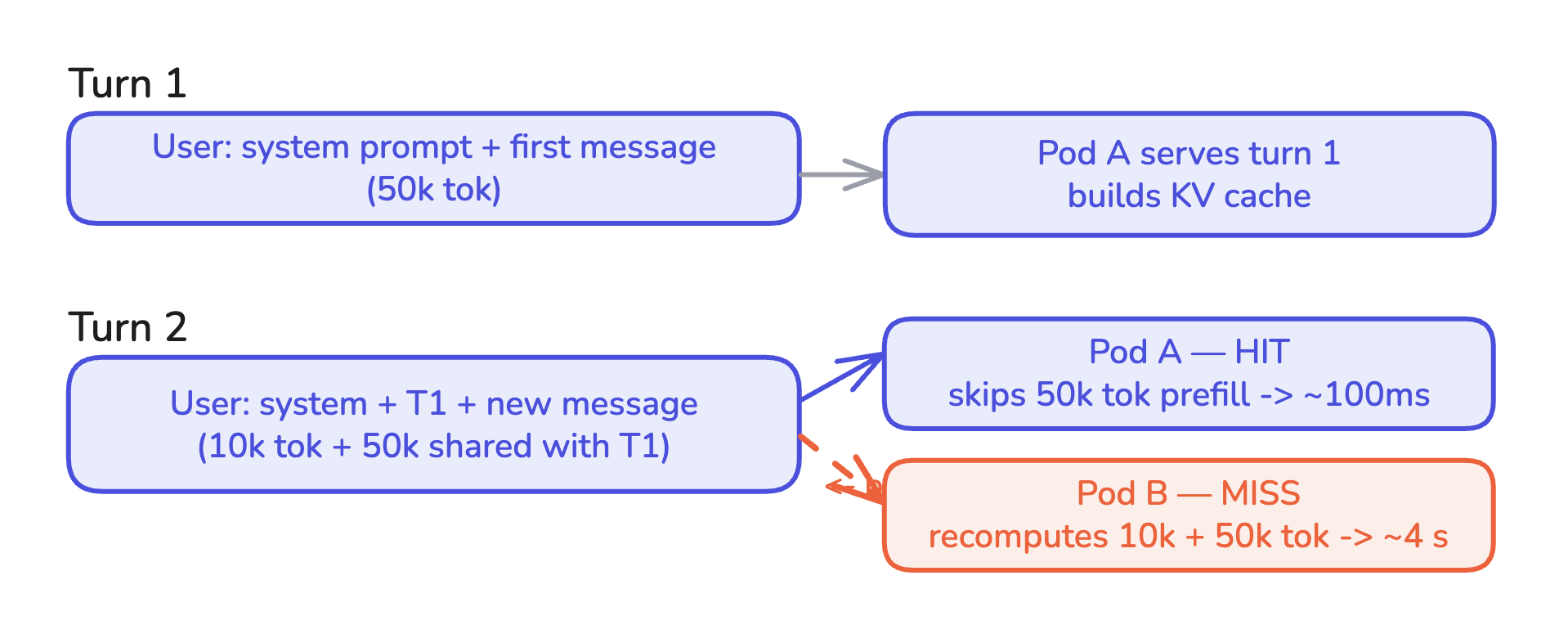
Most LLM traffic is multi-turn. A user sends a message. The assistant replies. The user sends another message, and that message implicitly contains the entire conversation history as context.
Turn N+1 shares a prefix with turn N: the system prompt, all prior turns, all prior assistant replies. If the KV cache from turn N is still resident on some pod, turn N+1 is effectively free to prefill for the shared portion. If the cache has been evicted, or if turn N+1 lands on a different pod, the shared prefix is recomputed from scratch.
Session affinity in HTTP used to mean “route this user’s requests to the same backend so the application can use in-memory state.” In LLM inference it means the same thing but the in-memory state is the KV cache. Getting it right is the difference between sub-second responses and multi-second responses on every turn after the first.
Multi-step execution
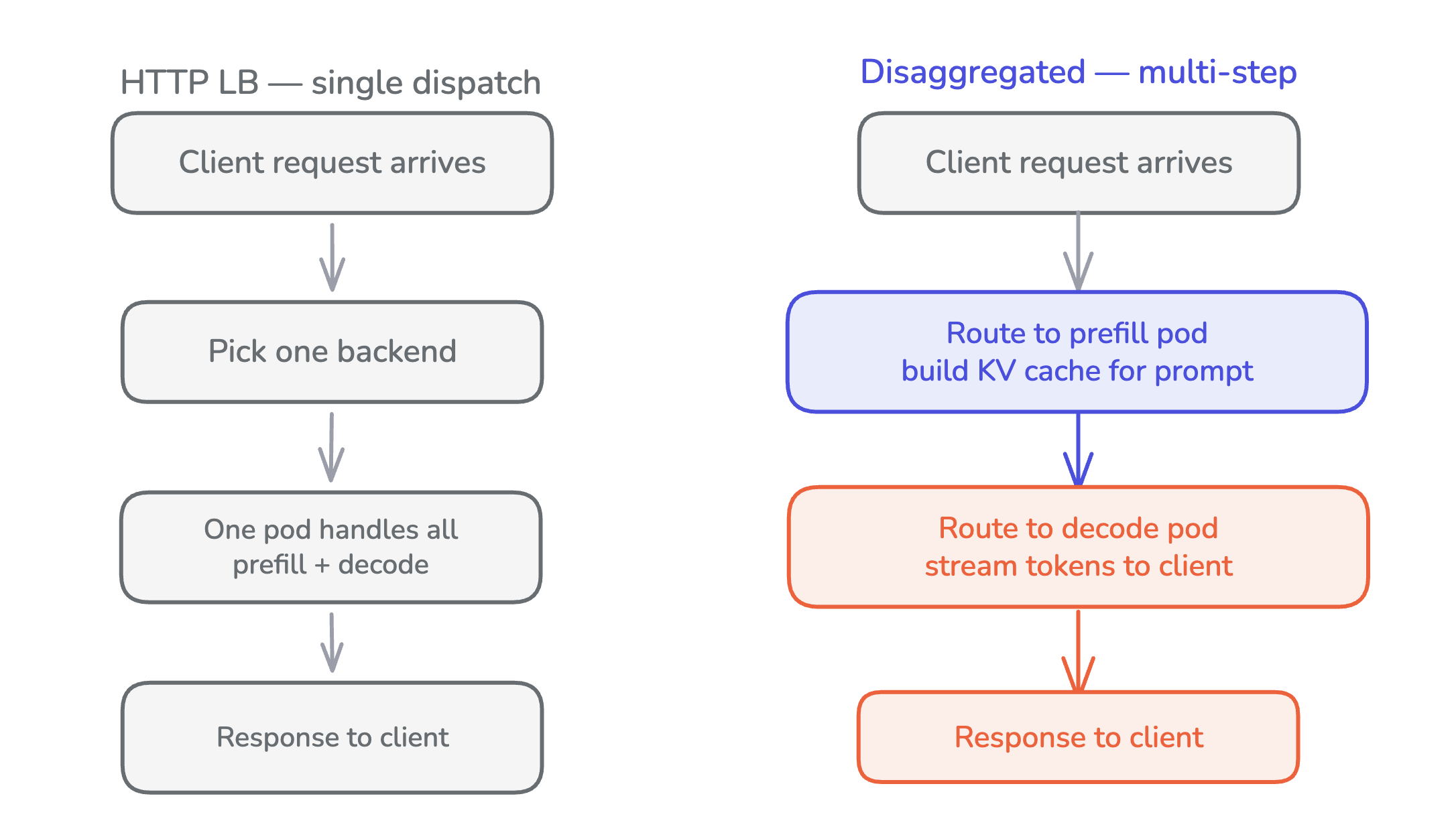
A single client-facing request may require more than one backend.
In a disaggregated deployment, the prefill pod builds the KV cache and the decode pod generates tokens. Neither can serve the request alone. The router picks a prefill pod, then a decode pod, then orchestrates the sequence: send the prompt to prefill, wait for completion, send the same prompt plus a cache hint to decode, stream tokens back to the client.
HTTP load balancers don’t do this. They pick one backend per request. Adding multi-step coordination to a single-dispatch router is a different shape of routing entirely.
The three layers
Each of the four dimensions above imposes requirements on a routing system. Those requirements fall into three distinct architectural concerns, each handled by a separate layer.
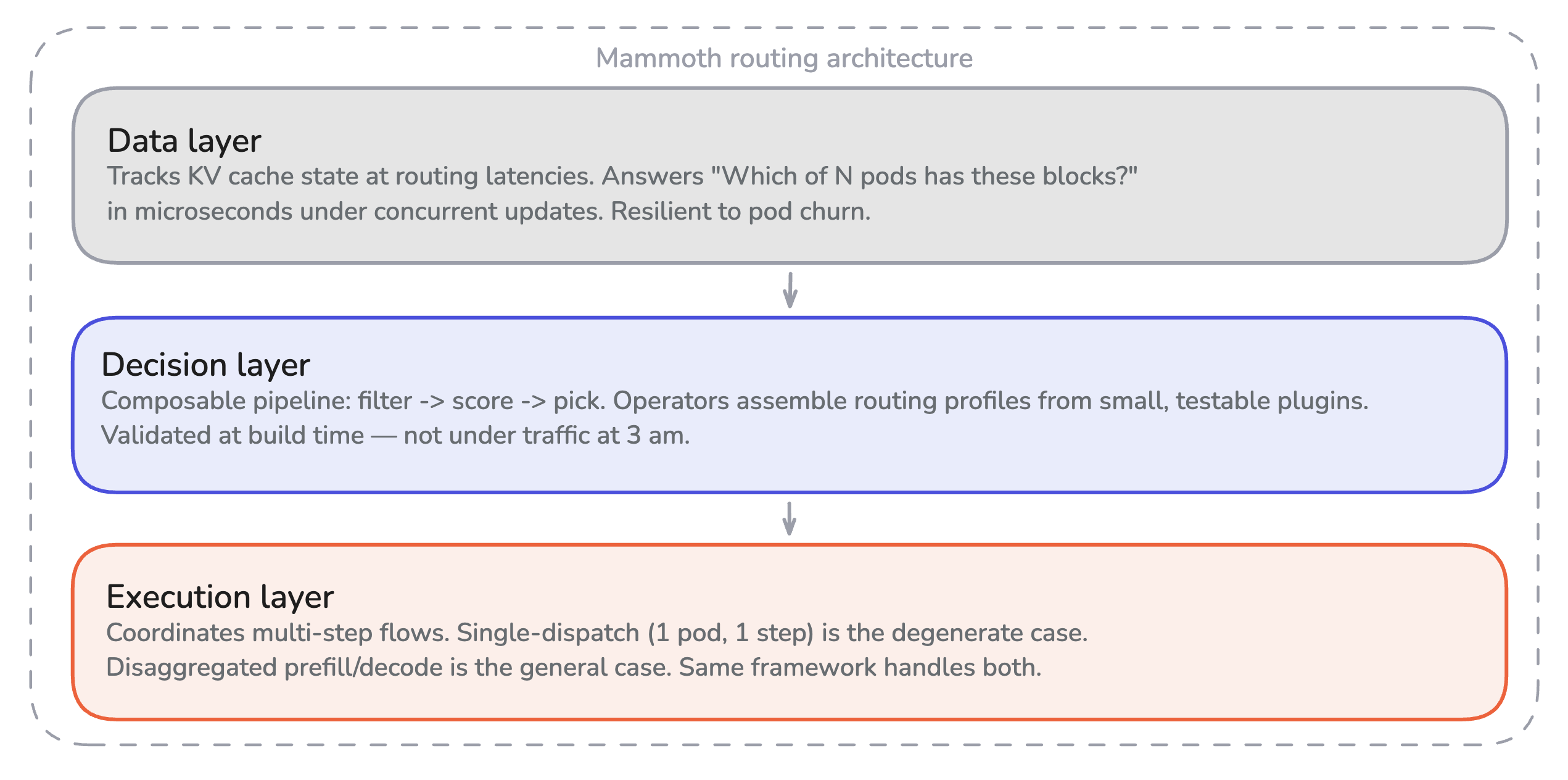
Data Layer
This layer tracks LLM-specific state at the latencies routing decisions require. The question “which of N pods has these blocks cached?” has to be answerable in microseconds, under concurrent updates, resilient to pod churn. A hashmap with a mutex isn’t sufficient.
Decision Layer
This layer expresses routing logic as compositions of small, testable, reusable components. Operators pick a filter, a few scorers, a picker, and assemble a profile. The framework validates the composition at build time, not under traffic at 3am.
Execution Layer
This layer coordinates multi-step request flows on top of the decision layer. Single-dispatch routing is a degenerate case of multi-step: one pod, one step. Disaggregated prefill/decode is the general case: two pods, two steps, with the second decision informed by the first. The same framework handles both without requiring a new HTTP handler per variant.
Parts 2 and 3 of this series build these layers.
Modular Cloud’s routing layer
This series describes the routing layer inside Modular Cloud's distributed inference framework, and how it handles each of these four problems in production inference workloads.
Prefix-aware routing (tokenization, block-level hashing, cache-aware scoring with load-aware tiebreaking, circuit breakers on upstream latency) ships as a profile configuration, not a new algorithm. When the team needs a new routing behavior, the work is composing plugins into a new profile rather than writing a new routing strategy from scratch. Each new deployment pattern reuses what's already there.
Conclusions
LLMs introduced four dimensions that traditional load balancers have no mechanism to handle: KV cache state that makes backend selection a performance-critical decision, hardware specialization that splits a single request across pod types, conversation continuity that ties sessions to cache residency, and multi-step execution that requires coordinating a sequence of backends rather than picking one.
This problem has been tackled from multiple angles. NVIDIA Dynamo, llm-d, vLLM production-stack, AIBrix, KServe, and Envoy AI Gateway have each advanced inference routing in different directions: disaggregated prefill/decode, prefix-aware scheduling, KV-aware load balancing, production-grade serving primitives. Modular Cloud builds on that foundation. To support the range of deployment patterns it targets, Modular Cloud makes composable plugins and multi-step execution both first-class primitives, so a new deployment pattern becomes a profile you assemble rather than a strategy you fork.
That’s the gap Modular Cloud’s routing layer is designed to close: three architectural layers with composition as the extension model rather than forking or wrapping. The rest of this series shows how it’s built.
What’s next
Part 2: The data layer. The data structure that makes cache-aware routing possible: sharded bitmaps, Fibonacci-scrambled distribution, and binary search over cumulative block hashes that turns a P x N scan into O(K x log N).
Part 3: The decision and execution layers. Turning cache state into routing decisions and then into execution. A five-stage composable pipeline, typed state between plugins, and the Selector/Workflow/Executor split that scales the same framework from round-robin to disaggregated prefill/decode.


