

Part 1: Why TileTensor?
Writing a high-performance GPU kernel means thinking carefully about memory (see our series on Matrix Multiplication on Blackwell). Not just what data to load, but how that data is laid out and how it maps to physical addresses. Getting this right manually is tedious and error-prone. TileTensor is Mojo's answer: a tensor type that lets kernel authors express complex memory layouts precisely, safely, and efficiently.
This post covers what TileTensor does, why it exists, and how to use it. Part 2 covers the Mojo language features that made the design possible.
Background: layouts, strides, and swizzles
To understand why TileTensor is useful, you need to understand what a layout is and why it matters.
A layout describes both the logical shape of a tensor and how its elements map to physical memory addresses. It has two components: a shape (such as (1024, 8)) and a stride (such as (8, 1)). The stride tells you how many elements to step in memory for each step along a given logical dimension. A stride of 1 in the final dimension makes this row-major. These pairs are written together as ((1024, 8):(8, 1)).
Layouts can also be nested (as shown in the Mojo Manual). A layout like ((1024, (4, 2)):(8, (2, 1))) describes a tiled memory arrangement where a 1024-row, 8-column logical space maps to a specific interleaved physical pattern. In this example, we have interleaved the ‘inner’ 8 values in a row to arrangement [0, 2, 4, 6, 1, 3, 5, 7]. This flexibility is what makes layout algebra useful for GPU programming: you can express row-major, column-major, and tiled arrangements in a single framework.
But shape and stride alone are not the full picture. GPU shared memory is organized into banks, and when multiple threads in a warp access the same bank simultaneously, they serialize(this is called bank conflict). The solution is swizzling: rearranging memory layout to distribute accesses across different memory banks. Swizzle patterns are part of a layout's definition, and they're one of the main reasons you want a dedicated abstraction for this rather than maintaining index arithmetic by hand. A swizzle cannot be expressed as an affine transform: no combination of shape and stride values produces the non-linear bit permutation that swizzling requires. This is why layout algebra needs a separate swizzle component rather than folding everything into strides. TileTensor makes layout a first-class, compile-time object so indexing, vectorization, and correctness constraints are generated and checked, not handwritten.
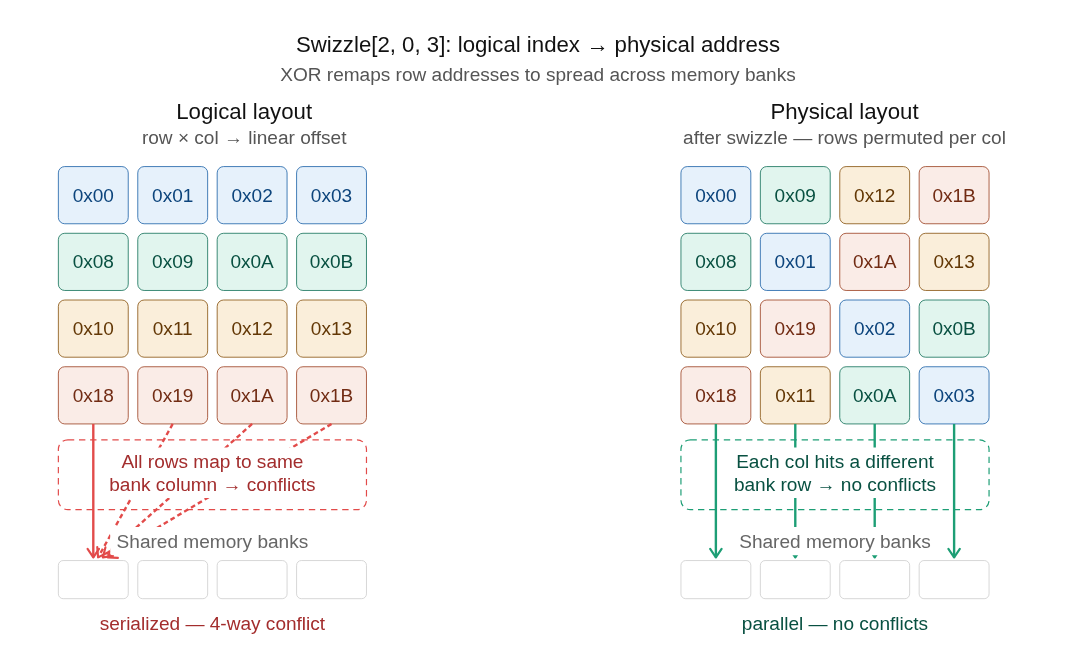
For a full walkthrough of layout algebra, see Modular's layout algebra documentation.
The indexing problem
Before getting to TileTensor, here's what the problem looks like without it.
Suppose you want to load a 2D tile of a matrix, where the tile is stored in shared memory in a specific interleaved layout to avoid bank conflicts. This example uses a toy XOR swizzle to illustrate the class of bugs; real kernels use hardware- and layout-specific swizzles and vectorized accesses. Without a layout abstraction, here is how you would launch a kernel with a block size of (32,8):
This is easy to get wrong. The swizzle formula is specific to the tile shape and the hardware bank width. Change the tile shape or target a different GPU and you have to recompute it. There's no type system help.
In CUDA C++ you can use the CuTe library to simplify the program:
This is more expressive than manual indexing, but TensorA and SmemLayout are unconstrained template parameters. Nothing in the type system prevents passing the wrong layout, a mismatched element size, or a non-swizzled layout where a swizzled one is required. Errors show up at run-time as incorrect results or as silent correctness bugs that only appear at specific tile sizes.
Here's the same operation in Mojo with TileTensor:
The three versions compute the same tile load. In the CUDA version, the swizzle formula is handwritten and specific to a 32x8 tile on hardware with 8-bank shared memory. Change the tile dimensions or move to a GPU with different bank geometry and the formula has to be recomputed manually. The CuTe version removes the explicit index arithmetic, but SrcTensor and DstTensor are unconstrained template parameters: nothing prevents passing a non-swizzled layout where a swizzled one is required. In the Mojo version, the swizzle is part of the layout passed to distribute , so the compiler generates the address computation from that description and enforces at compile time that the access pattern is valid.
Constructing a TileTensor
Here's what construction looks like for both static and dynamic shapes, on host and device:
The equivalent in CuTe:
The construction syntax is similar. The difference shows up when you use the tensor.
Shared memory allocation follows the same pattern. In Mojo:
In CuTe:
Memory tiling
One of the core use cases for TileTensor is expressing tiled data movement between global memory and shared memory. Modern GPU hardware provides dedicated instructions for this: NVIDIA's Tensor Memory Accelerator (TMA) and AMD's Data Movement Engine (DME) both operate at the tile level. TileTensor's layout system maps directly onto these instructions, letting you express tile-level transfers without manually computing addresses or managing alignment constraints. For a broader look at tile-based computation patterns in Mojo, see the structured kernels series.
Type safety at the call site
The type-safety difference is most visible when writing kernel functions. Here's a vector add in Mojo:
The type signature guarantees that a, b, and c share the same dtype and are all scalar. The equivalent in CuTe:
TensorA, TensorB, and TensorC are unconstrained. Nothing prevents passing operands of different types, mismatched shapes, or tensors with incompatible layouts. To express these constraints using CuTe types involves 7 template parameters and the types become much more complex.
Compiler integration and diagnostics
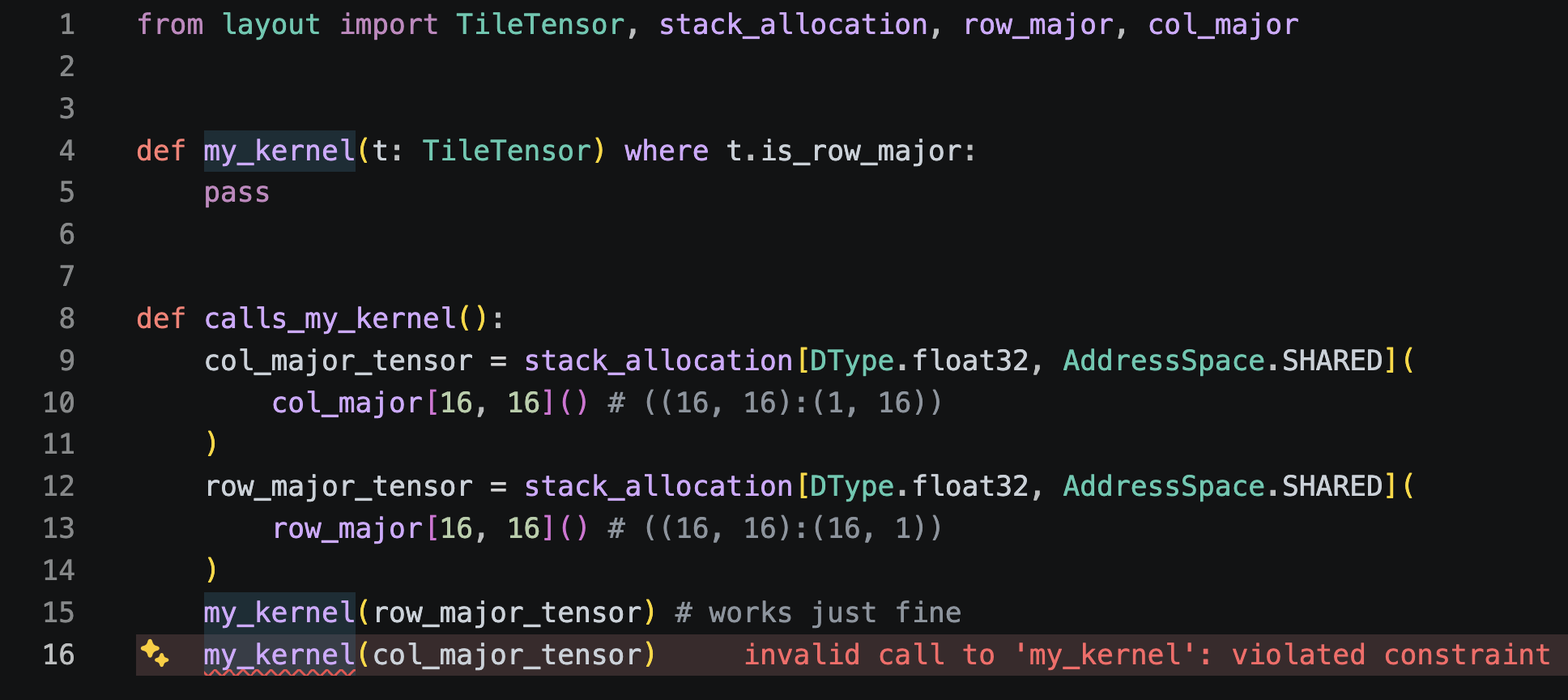
TileTensor works with Mojo's where clause, so shape constraints participate in overload resolution and produce clear error messages when violated:
Passing a tensor with a different static shape produces an error pointing at the violated constraint, making errors easier to identify.
This extends to element-level constraints for Scalars or SIMD vectors:
The element type returned by t[0, 0] is determined by element_size at compile time. No casting is required.
Mojo’s constraint system works nicely with TileTensor, and allows us to express safety requirements that can be evaluated in the LSP.
In the example above TileTensor.is_row_major checks that the layout has a static final dimension of 1 . The parser then evaluates that the final dimension on col_major_tensor's layout is 16, which fails that constraint.
What's next
TileTensor is now the default tensor type across Modular's kernel library. The AMD MHA kernel migration above is one example. The same pattern applies across attention, normalization, and matrix kernels. Static layouts eliminate entire categories of run-time overhead, and the type system catches layout mismatches before they reach hardware.
The next post breaks down the Mojo language features that made TileTensor possible and the benefits of its small run-time footprint.


