
.png)

Parts 1–3 of this series showed that separating IO, pipeline, and compute concerns into composable components simplifies development without sacrificing performance. This post demonstrates how Structured Mojo Kernels benefits persist when the target hardware changes.
GPU portability has a mixed track record. “Write once, run everywhere” usually means “write once, run slowly everywhere.” CUTLASS does not attempt portability beyond NVIDIA hardware and is usually limited within a generation of the hardware. Triton provides portability but performance degrades on non-NVIDIA targets. The conventional wisdom is that you have to choose between being portable or being fast.
Structured Mojo Kernels offer a third option: start portable and progressively specialize.
AMD MI355X: a genuinely different machine
The AMD MI355X (CDNA4) shares almost nothing with NVIDIA Blackwell at the hardware level. The following table summarizes the differences in capabilities as well as terminology:
| Feature | NVIDIA B200 | AMD MI355X |
|---|---|---|
| Thread group size | 32 (warp) | 64 (wave) |
| Register allocation | Dynamic | Static (shared equally) |
| Dedicated tensor memory | Yes (TMEM, 256KB) | No (registers only) |
| Hardware barriers | mbarrier (arrive/wait, byte counting) | None (use atomics or s_barrier) |
| Async memory engine | TMA (descriptor-based, hardware im2col) | load_to_lds only |
| Shared memory per SM/CU | 228KB | 160KB |
| Matrix instruction | tcgen05.mma | mfma |
These differences are substantial, since they impact how you organize threads, how you synchronize, how you manage memory, and how you hide latency. Targeting the lowest common denominator leaves a lot of performance on the table.
Why warp specialization does not map to AMD
On NVIDIA, register allocation is dynamic. Producer warps that only issue TMA loads need few registers; consumer warps that run MMA get more registers. The register file is partitioned accordingly, so neither warp wastes capacity.
On AMD, all waves share registers equally. If you dedicate half your waves to loading (low register pressure) and half to compute (high register pressure), you waste half your register file. The hardware divides equally regardless of need.
This means the NVIDIA pattern of dedicated producer and consumer warps is not directly efficient on AMD. A different coordination strategy is required.
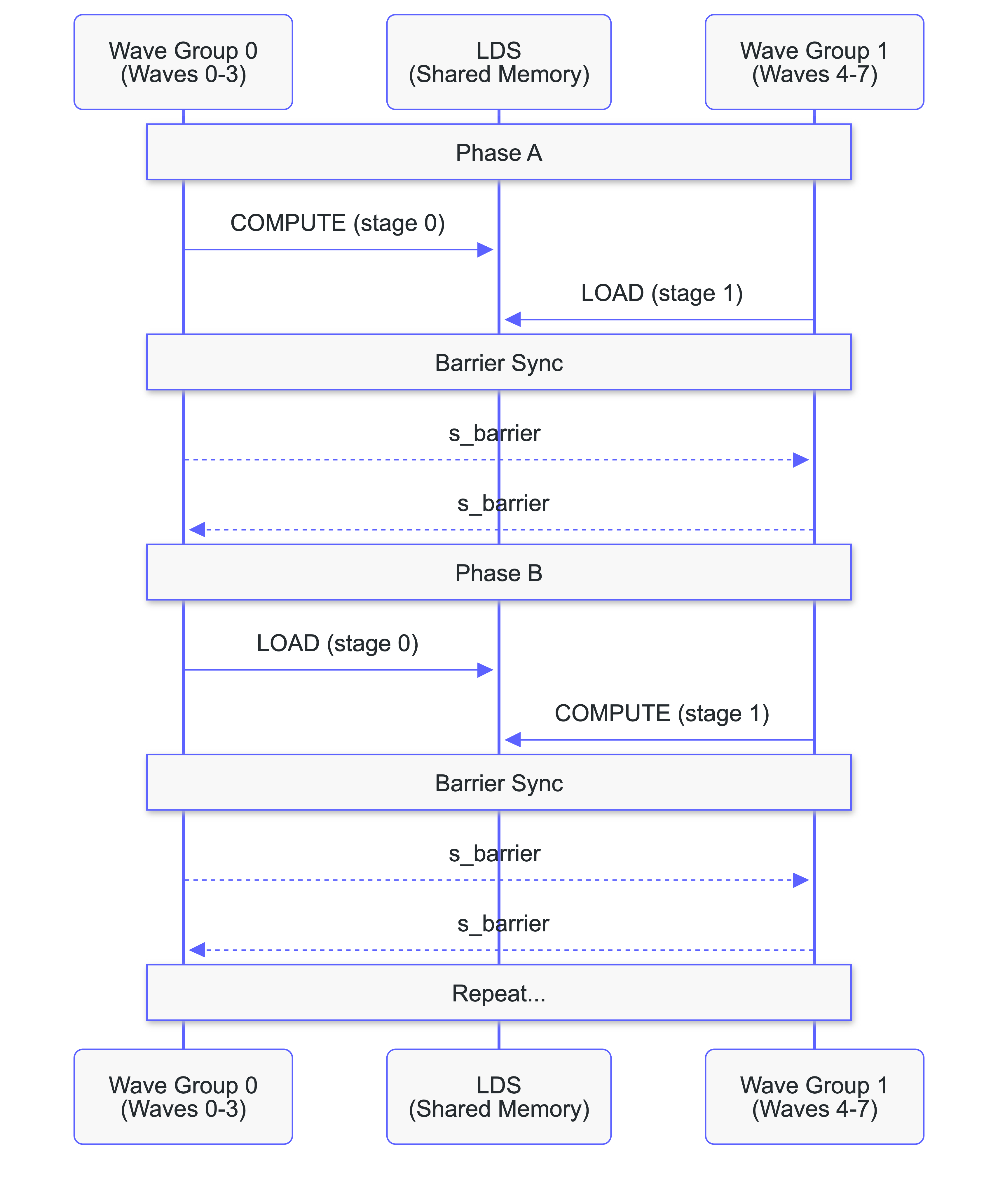
The ping-pong pipeline pattern
Our AMD kernel uses an alternating pattern where all 8 waves contribute to both loading and computing. Two wave groups (waves 0–3 and waves 4–7) alternate roles each phase:
- Phase A: Group 0 computes from stage 0 while Group 1 loads into stage 1.
- Phase B: Group 1 computes from stage 1 while Group 0 loads into stage 0.
Double-buffered shared memory ensures one group always has data ready while the other prefetches. The s_barrier operation ensures this synchronization across wave groups. This results in full utilization of the GPU.
What is shared, what adapts
Despite the hardware differences, both platforms share foundations:
Shared across platforms:
- TileTensor and layout algebra: The same compile-time layout types describe tile shapes, strides, and swizzle patterns on both platforms. A
TileTensor[BF16, Layout[...]]in shared memory works identically whether the underlying storage is NVIDIA SMEM or AMD LDS. - Tile-based decomposition: Both platforms tile the matmul the same way (the Goto & Van Der Geijn schedule is hardware-independent). The M, N, K tile dimensions, the loop structure, and the output tile layout are shared.
- Compile-time configuration:
comptime BM = 128,comptime BN = 256,comptime num_stages = 5. Parameterization works the same in both cases.
Adaptations per platform:
- Coordination strategy:
- NVIDIA: warp-specialized producer/consumer with hardware
mbarrier. - AMD: ping-pong with barrier-based double buffering.
- NVIDIA: warp-specialized producer/consumer with hardware
- Synchronization primitives:
- NVIDIA:
mbarrierarrive/wait. - AMD:
s_barrier+ atomic counters.
- NVIDIA:
- Accumulator management:
- TMEM with explicit allocate/deallocate on NVIDIA.
- Register-based accumulators on AMD, compiler-managed.
- Data movement:
- TMA (asynchronous, descriptor-based) on NVIDIA.
- Cooperative
load_to_ldson AMD.
The boundary between shared and platform-specific is the whole point of the Structured Mojo Kernels architecture. Platform-specific code lives inside TileIO, TilePipeline, and TileOp implementations. The kernel logic that composes them does not change.
The portable warp-specialized kernel
The ping-pong kernel is one valid strategy for AMD. But structured components make something more ambitious possible: a single kernel structure that runs on both AMD and NVIDIA, with platform-specific components swapped in for performance.
The plan starts with a warp-specialized kernel (the same coordination pattern used on Blackwell) running on both AMD MI355X and NVIDIA A100/H100. It will be suboptimal at first; the goal is to validate the common structure. Then we specialize components progressively:
| Component | Common baseline | NVIDIA specialization | AMD specialization |
|---|---|---|---|
| TileIO | Software-managed loads | TMA (async, descriptor-based) | Cooperative load_to_lds |
| TileOp | Generic MMA wrapper | tcgen05.mma (Blackwell) / wgmma (Hopper) | mfma |
| TilePipeline | Software barriers | Hardware mbarrier | Atomic counters |
| Scheduling | Software tile distribution | CLC (hardware scheduling) | Software fallback |
Each specialization makes the kernel faster on that platform without touching the others. This is composition applied to portability: you do not rewrite the kernel, you specialize the components.
The kernel's control flow (the loop structure, the warp roles, the pipeline staging) stays the same. What changes is the implementation behind each component interface. A TileIO.load() call dispatches to TMA on Blackwell and to cooperative loads on AMD, but the kernel does not know or care which.
The portable kernel is the direct consequence of the component boundaries built throughout this series. Conv2d proved that swapping TileIO works. Block-scaled matmul proved that parameterizing TilePipeline works. The portable kernel applies both techniques simultaneously across platforms.
How Mojo enables kernel composition
There is a deeper reason why this architecture works, and it comes down to how Mojo differs from C++ at the language level.
CUTLASS achieves code reuse through template specialization. You define a base template with hundreds of type parameters, then partially specialize it for each hardware target, each data type, each tile shape. The result is a codebase of 500K+ lines where adding a new platform means adding a new specialization hierarchy, and reading any single kernel means tracing through multiple layers of template resolution.
GPU programming evolved under tight constraints: small shared memory, tight register budgets, no virtual functions, no heap allocation. C++ templates were the only reuse mechanism that survived those constraints. But modern GPUs have hundreds of kilobytes of shared memory, dedicated tensor memory, hardware scheduling units, and asynchronous DMA engines. The software complexity of a production kernel now rivals a database engine, a domain where no one would choose templates as the primary architecture tool. The tools have not kept up with the hardware.
Structured Mojo Kernels achieve reuse through composition. You build small components with clean interfaces, then combine them. A different loader? Swap the TileIO. A different data format? Parameterize the TilePayload. A different platform? Provide new component implementations that satisfy the same interfaces.
C++ templates are a separate sub-language. Template metaprogramming is powerful but syntactically alien. The error messages, the SFINAE (Substitution Failure Is Not An Error) tricks, the recursive template patterns all exist because the template language was never designed as a general-purpose programming language. Reuse requires enormous framework machinery as a result.
Mojo's metaprogramming language is Mojo. A comptime expression evaluates at compile time using the same syntax, the same types, and the same control flow as runtime code. Parameterized structs work like regular structs. Traits work like interfaces. There is no separate template language to learn, no framework machinery to navigate.
The natural way to write reusable code in Mojo is the same way you write any code: small structs with clear interfaces, composed together. The "structured" in Structured Mojo Kernels is not a framework. It is basic software engineering applied to a domain where previous tools made basic software engineering impractical.
Structured Mojo Kernels are another step in Modular’s mission to create a unified AI inference platform for high-performance, portable compute. That requires a maintainable kernel layer that can be quickly extended and sustainably maintained across diverse hardware. Because this code is open source, the same architectural advantages are available to any developer who wants to write and maintain kernels for multiple hardware targets.
Series conclusion
This series set out to answer a question the GPU programming community has been working on for years: can you have clean, maintainable code without sacrificing peak performance?
Here is what we found.
The numbers
| Metric | CUTLASS | Mojo | Change |
|---|---|---|---|
| Conv2d-specific code | ~870 lines | ~130 lines | -85% |
| Block-scaled addition | ~1,500 lines | ~200 lines | -87% |
| Performance | Baseline | Equal | Zero-cost |
Structured Mojo Kernels achieved the same performance of the equivalent CUTLASS kernel with a fraction of the code. A new operation (conv2d) was written in 130 lines by swapping TileIO. A new data format (block-scaled matmul) was added in 200 lines by parameterizing TilePayload. The benefits of the architecture continue to compound.
Three principles
Separation of concerns. TileIO, TilePipeline, TileOp: each component owns its domain. The conv2d port proved this directly: swapping TileIO left TilePipeline and TileOp untouched.
Composition over specialization. Traits and parameterized types instead of template hierarchies. Three TilePayload implementations share one pipeline; conv2d shares the entire kernel infrastructure. Mojo's comptime system makes this the natural way to write reusable GPU code.
Resource management. GPU resources like TMEM, pipelines, and barriers must be explicitly acquired and released. In C++ kernels, that lifecycle is typically managed by hand, which means leaks and use-after-free bugs are possible. Mojo context managers tie resource lifetime to lexical scope: the compiler enforces release at scope exit.
What comes next
- The portable kernel. A single warp-specialized kernel running on both AMD and NVIDIA, with progressively specialized components.
- Attention fusion. Convolution is done. Attention is next; the same composition principles apply to multi-stage fused kernels.
- Automated scheduling. Using constraint solvers to find optimal instruction orderings, replacing hand-tuned schedules with systematically optimal ones.
- Your contributions. The code is open source. The architecture is designed to be extended by people who know their hardware.
Get started
The code is in the Modular repository:
- Blackwell Structured Matmul:
max/kernels/src/linalg/matmul/gpu/sm100_structured/ - Blackwell Conv2d:
max/kernels/src/nn/conv_sm100/ - AMD Matmul:
max/kernels/src/linalg/matmul/gpu/amd/
Performance and maintainability were never mutually exclusive. Mojo makes it practical to achieve both.
Summary
- AMD MI355X has a fundamentally different execution model. Static registers, no TMEM, no
mbarrier. The ping-pong pattern addresses the static register allocation constraint directly; the tile-based decomposition and layout algebra carry over unchanged. - Portability means progressive specialization, not source compatibility. The component boundaries make it possible to swap platform-specific implementations without rewriting kernel logic.
- Composition beats specialization because of Mojo's metaprogramming. CUTLASS uses C++ template specialization: 500K+ lines, NVIDIA-only. Structured kernels use composition: small components, clean interfaces, platform-agnostic kernel logic. That difference follows from the language itself.
- The numbers hold up at scale. 48% code reduction, conv2d in 130 lines, block-scaled matmul in 200 lines, zero performance cost. The reductions compound as you build more kernels on the architecture.
- This is a foundation. Portable warp-specialized kernels, attention fusion, and automated scheduling are next. The principles stay the same but the scope of this work will continue to expand.


