
.png)

In Part 2, we built the three pillars of Structured Mojo Kernels: TileIO for data movement, TilePipeline for coordination, and TileOp for compute. These three pillars form a strong structured abstraction of kernel programming - enabling composition of modular typed and testable pieces rather than a large monolithic block of interleaved logic.
This post shows the practical benefit of this modular design. We take two real kernel families, conv2d and block-scaled matmul, and trace exactly how they are built around the matmul foundation. In both cases, a new kernel family requires changing one component while leaving the rest untouched. The conv2d kernel adds roughly 130 lines of new code, whileBlock-scaled matmul adds roughly 200 with no performance degradation.
The Blackwell execution model
Both examples in this post target NVIDIA Blackwell (SM100). Two hardware features shape the kernel design. TMA (Tensor Memory Accelerator) handles bulk asynchronous transfers between global and shared memory, freeing compute warps from data movement entirely. TMEM (Tensor Memory) is a dedicated 256 KB on-chip buffer for accumulator storage, separate from shared memory, so MMA (Matrix Multiply-Accumulate) warps accumulate results without competing for shared memory bandwidth (more on these hardware features in this blog post).
The structured matmul kernel assigns each of its 7 warps a fixed role:
| Warps | Role | Responsibility |
|---|---|---|
| 0–3 (128 threads) | Epilogue | TMEM → registers → SMEM → global memory via TMA |
| 4 (32 threads) | Scheduler | CLC-based work distribution |
| 5 (32 threads) | Load | TMA loads for A and B tiles |
| 6 (32 threads) | MMA | Tensor core operations, TMEM accumulation |
Warp specialization enables full overlap: the load warp prefetches tile N+1 while the MMA warp computes tile N. The pipeline uses 5 to 7 stages to hide memory latency (~500 to 800 cycles) behind compute (~100 cycles per tile).
Context-managed warp lifecycle
Each warp role runs inside a Mojo context manager that owns its resources. The MMA warp’s MmaWarpContext manages the full TMEM lifecycle:
Context managers in Mojo are just like in Python: they guarantee that a call to `enter` will be paired with a call to `exit`. In this case, __enter__ signals the epilogue warps that TMEM is allocated and ready. __exit__ waits for the epilogue to finish reading, then deallocates. This simple approach makes sure that the kernel author doesn't accidentally use TMEM before it is ready, forget to coordinate with the epilogue, or leak TMEM on an early return. The compiler enforces all of it: it is "correct by construction".
The epilogue side mirrors this: EpilogueWarpContext.__enter__ is a no-op (the MMA warp drives the sync), and __exit__ calls signal_complete() to tell the MMA warp it is safe to deallocate.
Composition axis 1: Conv2d via TileIO swap
The first composition pattern is substitution: replace one component while keeping the other components as a constant.
Convolution can be expressed as matrix multiplication through the im2col transformation. Rather than materializing the im2col buffer explicitly (which costs O(M × K) memory), we can use the TMA to perform the coordinate transformation on the fly during loads. This means conv2d is matmul with a different tile loader; the data access pattern changes, but the pipeline coordination and compute are identical. And this can all be done by swapping the TileIO component.
What changes
The matmul kernel’s TileLoaderTMA loads rectangular tiles from contiguous memory. Conv2d replaces it with TileLoaderTMAIm2col, which maps output spatial positions to input coordinates accounting for stride, padding, and dilation:
The call site is identical. The addressing logic, which decomposes linear indices into (N, H, W, C) coordinates, applies stride and padding offsets, and issues TMA im2col transactions, lives entirely inside the loader.
What stays the same
Everything else. The conv2d kernel reuses the matmul infrastructure unchanged:
- TilePipeline:
InputTilePipelinewith the sameproducer()/consumer()interface - TileOp:
MmaWarpContextwith identical TMEM lifecycle - Epilogue: Same
TileWriterandEpilogueWarpContext - Scheduler: Same CLC-based
TileScheduler - Shared memory layout: Same pipeline storage, same barrier arrays
The conv-specific code is ~130 lines in the Modular repository: the im2col tile loader, a shared memory layout that accounts for activation tile shapes, and the kernel entry point that wires them together.
The 8th warp: fused residual add
Conv2d with fused residual add (D = Conv(A,B) + beta*C) adds one more warp role to the 7-warp matmul architecture:
| Warps | Role | Responsibility |
|---|---|---|
| 0–3 | Epilogue | TMEM → registers, add residual, store |
| 4 | Scheduler | CLC-based work distribution |
| 5 | MainLoad | TMA im2col loads for activation and filter |
| 6 | MMA | Tensor core operations |
| 7 | EpilogueLoad | TMA loads for residual tensor C |
The EpilogueLoad warp pre-fetches the residual tensor overlapped with MMA computation. When the epilogue warps read the accumulator results from TMEM into registers, the residual data is already residing in shared memory. The add operation happens at register level with no shared memory round-trip for the fusion.
The result is zero overhead. Fused residual add runs at the same speed as standard conv2d because the load is fully hidden behind compute.
| Layer | Conv only | Conv + Residual | Overhead |
|---|---|---|---|
| 16×16, 128→128 | 0.037 ms | 0.037 ms | ~0% |
| 32×32, 256→256 | 0.068 ms | 0.066 ms | ~0% |
| 64×64, 256→128 | 0.068 ms | 0.066 ms | ~0% |
Adding the 8th warp required no changes to the existing 7 warps.
What others do instead
Let's compare against CUTLASS, since it provides the cleanest implementation. CUTLASS implements conv2d as a separate 870-line kernel largely duplicated from their matmul kernel. Pipeline setup, warp coordination, barrier management, and TMEM lifecycle are all reimplemented. Every optimization to the matmul kernel must be manually ported to the conv2d kernel and verified independently. This is because CUTLASS's template instantiation model couples the pipeline, barrier, and epilogue logic to concrete tile and layout types, so there is no abstraction boundary at which a different loader can be substituted without duplicating the surrounding infrastructure.
With structured components, the conv2d kernel imports the matmul infrastructure and replaces a single piece. Bug fixes and optimizations to shared components propagate automatically.
Composition axis 2: Block-scaled matmul via TilePayload
Conv2d composed by swapping a component. Block-scaled matmul shows the second pattern: parameterizing a component so it handles a structurally different data flow without changing the pipeline that moves it.
Block-scaled matrix multiplication extends standard matmul with per-block scaling factors for FP8/FP4 quantized inference:
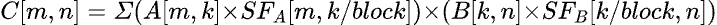
This changes the data flow: 4 TMA loads instead of 2, additional shared memory for scale factor tiles, and a scale-aware epilogue that applies the factors during output. In a monolithic kernel, these changes scatter across thousands of lines. With structured components, they localize in a single place: the payload. This composition pattern is applicable to any kernel where the payload type is updated but the pipeline structure is unchanged.
The TilePayload trait
The key design decision in InputTilePipeline is that the pipeline is parameterized by its payload type. The pipeline manages synchronization: barrier waits, stage advancement, producer/consumer roles. The payload manages what is being synchronized: which tiles, how many, and what layout. The trait itself is a marker; the structure comes from the implementations:
Three payloads, one pipeline
StandardTilePayload carries A and B tiles for standard matmul:
BlockScaledTilePayload adds scale factor tiles for MXFP8/NVFP4:
BlockwiseFP8TilePayload carries A, B, and A-scales (B-scales are read from global memory during the epilogue):
As a result, InputTilePipeline is generic over any type that satisfies TilePayload.
The generic pipeline
The InputProducer and InputConsumer returned by producer() and consumer() provide acquire() context managers. with producer.acquire() as tiles: waits for the barrier on entry, provides access to the payload's tiles, and advances the stage on exit.
Mojo's compile-time metaprogramming monomorphizes each InputTilePipeline[StandardTilePayload] and InputTilePipeline[BlockScaledTilePayload] into fully specialized code. As a result, there is zero overhead due to vtable dispatch, and you get the zero cost abstraction.
What you change vs what you reuse
| Component | Standard | Block-Scaled | Blockwise FP8 | Shared? |
|---|---|---|---|---|
| InputTilePipeline | ✓ | ✓ | ✓ | Yes |
| InputProducer/Consumer | ✓ | ✓ | ✓ | Yes |
| ProducerConsumerPipeline | ✓ | ✓ | ✓ | Yes |
| MmaWarpContext | ✓ | ✓ | ✓ | Yes |
| EpilogueWarpContext | ✓ | ✓ | ✓ | Yes |
| TileScheduler | ✓ | ✓ | ✓ | Yes |
| TilePayload | Standard | BlockScaled | BlockwiseFP8 | No |
| Epilogue | Standard | Scale-aware | Per-K scales | No |
Adding block-scaled support is around ~200 lines. Adding the equivalent to a monolithic kernel requires ~1,500 lines of scattered modifications.
Zero-cost abstractions
Abstractions earn their keep only if they do not cost performance. We verified this by comparing SASS (GPU assembly) output between the structured and legacy Blackwell matmul kernels. The instruction sequences are identical. We also verified the performance on an E2E model, for example benchmarking Llama shows the same performance with 50% less code:
| Benchmark | Mean Delta | Notes |
|---|---|---|
| Llama 8B Decode | -0.2% | Performance parity |
| Llama 8B Prefill | -0.1% | Performance parity |
| Llama 405B TP8 | +0.2% | Slightly faster |
What these two examples show
Conv2d and block-scaled matmul represent the two most common ways kernel requirements change in practice: you need a different data access pattern (TileIO swap), or you need a different data type with more operands (TilePayload parameterization). The structured design handled both without touching the shared infrastructure.
These composition patterns are generalizable to other use cases. If what changes is the path data takes from memory to shared memory, swap TileIO. If what changes is the structure of what flows through the pipeline once loaded, parameterize the payload.
That predictability matters for anyone building or maintaining a kernel library. When a bug is found in shared pipeline or epilogue code, it is fixed once and every kernel using that component gets the fix. When a new quantization scheme appears, the incremental cost is on the order of 200 lines, not a full reimplementation. When a new GPU architecture arrives, platform-specific code stays inside its own layer and kernel logic does not change. The architecture does not accumulate debt with each new variant.
Part 4 takes that last point to AMD. We show what it actually means to port these kernels to a fundamentally different memory hierarchy and execution model, and where the architecture goes from there.
TL;DR
- Conv2d composes by swapping TileIO. Replace the contiguous tile loader with an im2col-aware variant; reuse the entire matmul pipeline, compute, epilogue, and scheduler. ~130 lines of conv-specific code vs CUTLASS's 870-line separate kernel.
- Block-scaled matmul composes by parameterizing TilePipeline. The
TilePayloadtrait separates synchronization from tile storage. Three payload implementations share one pipeline with zero changes to barrier management. - The 8th warp extends without forking. Conv2d's fused residual add adds one warp role without touching the existing seven. Zero overhead because the residual load hides behind compute.
- The abstractions are zero-cost. SASS output is identical between structured and legacy kernels. Llama benchmarks confirm performance parity.
- Changes stay localized. New kernels compose from existing components. Fixes propagate automatically. Each new kernel variant costs a predictable number of incremental lines, not a full reimplementation.


