Blog

Democratizing AI Compute Series
Go behind the scenes of the AI industry with Chris Lattner


Bring your own PyTorch model
The adoption of AI by enterprises has surged significantly over the last couple years, particularly with the advent of Generative AI (GenAI) and Large Language Models (LLMs). Most enterprises start by prototyping and building proof-of-concept products (POCs), using all-in-one API endpoints provided by big tech companies like OpenAI and Google, among others. However, as these companies transition to full-scale production, many are looking for ways to control their AI infrastructure. This requires the ability to effectively manage and deploy PyTorch.
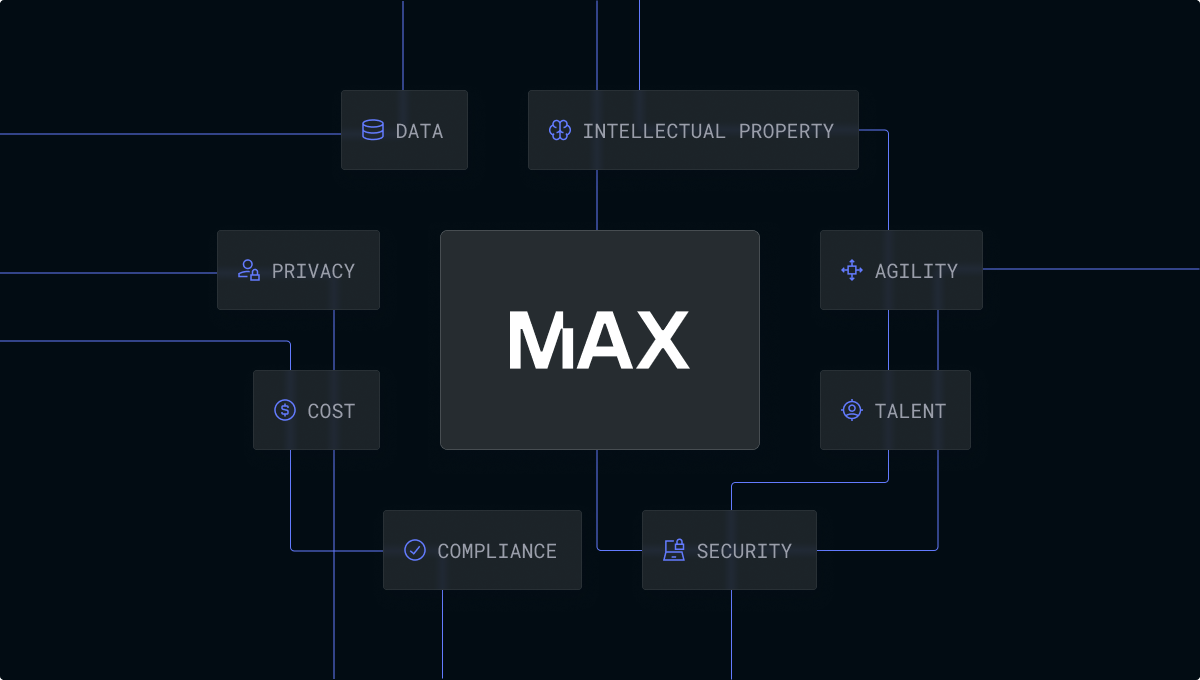
Take control of your AI
In today’s rapidly evolving technology landscape, adopting and rolling out AI to enhance your enterprise is critical to improving your organization’s productivity and ensuring that you are delivering a world-class product and service experience to your customers. AI is without question, the single most important technological revolution of our time—representing a new technology super-cycle that your enterprise cannot be left behind on.
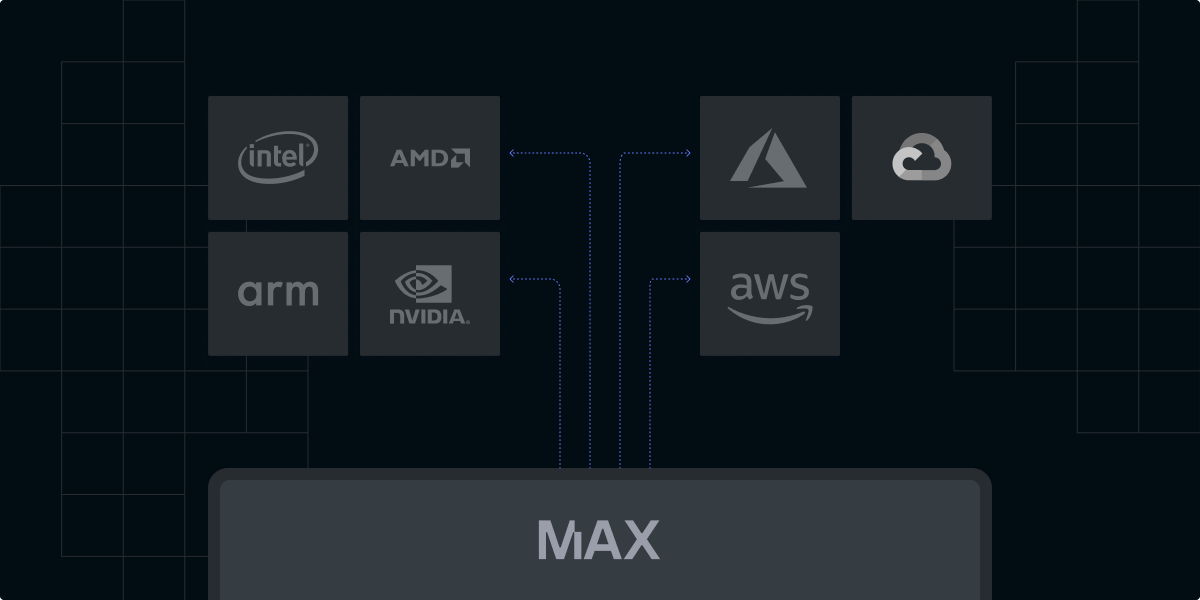
Develop locally, deploy globally
The recent surge in AI application development can be attributed to several factors: (1) advancements in machine learning algorithms that unlock previously intractable use cases, (2) the exponential growth in computational power enabling the training of ever-more complex models, and (3) the ubiquitous availability of vast datasets required to fuel these algorithms. However, as AI projects become increasingly pervasive, effective development paradigms, like those commonly found in traditional software development, remain elusive.

MAX 24.4 - Introducing quantization APIs and MAX on macOS
Today, we're thrilled to announce the release of MAX 24.4, which introduces a powerful new quantization API for MAX Graphs and extends MAX’s reach to macOS. Together, these unlock a new industry standard paradigm where developers can leverage a single toolchain to build Generative AI pipelines locally and seamlessly deploy them to the cloud, all with industry-leading performance. Leveraging the Quantization API reduces the latency and memory cost of Generative AI pipelines by up to 8x on desktop architectures like macOS, and up to 7x on cloud CPU architectures like Intel and Graviton, without requiring developers to rewrite models or update any application code.


Announcing MAX Developer Edition Preview
Modular was founded on the vision to enable AI to be used by anyone, anywhere. We have always believed that to achieve this vision, we must first fix the fragmented and disjoint infrastructure upon which AI is built today. As we said 2 years ago, we imagine a different future for AI software, one that rings truer now than ever before

.png)
Mojo🔥 is now available on Mac
We released Mojo local download for Linux systems on September 7th, and in just over a month we’ve seen tens of thousands of downloads and amazing community projects such as llama.🔥and Infermo. We deeply value your feedback, as Mojicians, and we appreciate every single PR, feature request, and bug report.

Mojo🔥 - It’s finally here!
Since our launch of the Mojo programming language on May 2nd, more than 120K+ developers have signed up to use the Mojo Playground and 19K+ developers actively discuss Mojo on Discord and GitHub. Today, we’re excited to announce the next big step in Mojo’s evolution: Mojo is now available for local download – beginning with Linux systems, and adding Mac and Windows in coming releases.

Democratizing Compute
Go behind the scenes of the AI industry in this blog series by Chris Lattner. Trace the evolution of AI compute, dissect its current challenges, and discover how Modular is raising the bar with the world’s most open inference stack.

Matrix Multiplication on Blackwell
Learn how to write a high-performance GPU kernel on Blackwell that offers performance competitive to that of NVIDIA's cuBLAS implementation while leveraging Mojo's special features to make the kernel as simple as possible.

Structured Mojo Kernels
Learn how Mojo simplifies GPU programming with modular kernel architecture, compile-time abstractions, and zero-cost performance across modern GPU hardware.

Software Pipelining for GPU Kernels
Explore software pipelining for GPU kernels from first principles. We formalize dependencies as a graph, solve for the optimal schedule with a constraint solver, and show how it all integrates into MAX via pure Mojo.

Why LLM Inference Needs a New Kind of Router
This series walks through why traditional HTTP routing breaks down under LLM workloads and how Modular Cloud solves it with a three-layer architecture built for cache-aware routing.

TileTensor
This series walks through how Modular built TileTensor, a Mojo tensor type that lets kernel authors express complex memory layouts precisely, safely, and efficiently.
No items found within this category
We couldn’t find anything. Try changing or resetting your filters.

Sign up today
Signup to our Cloud Platform today to get started easily.
Sign Up
Browse open models
Browse our model catalog, or deploy your own custom model
Browse models