

.jpeg)
On May 2nd, we announced our next-generation AI developer platform with two exciting breakthrough technologies — the Mojo programming language and the Modular AI Engine. In just over two months, more than 110k developers have signed up for the Mojo Playground to learn Mojo and experience its performance firsthand, over 30k developers have signed up to our waitlist for the AI engine, and our Modular community on Discord has grown to 17k developers! We’re incredibly excited to see developers sharing their experience with Mojo, providing product feedback, and learning from each other.
Since our announcement, a question we continue to receive frequently from our community members is — what’s the difference between the AI Engine and the Mojo programming language?
We’re glad to see questions from our community members and their enthusiasm to learn more about these products. We’ll first discuss the AI Engine, which will be less familiar to our readers, given that it is still in closed preview. We will then discuss how Mojo integrates with the AI Engine and finally wrap the post up with how we think they’ll join forces to unlock many AI and other use cases that are bottlenecked by performance and usability constraints.
What is the AI Engine?
The AI Engine is a high-performance inference engine for leading AI frameworks like PyTorch and TensorFlow. It supports importing trained model artifacts from TensorFlow (SavedModel), PyTorch (TorchScript), and ONNX and uses state-of-the-art compiler and runtime technologies to deliver up to 7.5x higher throughput vs. native framework runtimes. Our earlier blog post shared its performance on TensorFlow and PyTorch models across different CPU architectures (Intel, AMD, ARM). For the most up-to-date performance benchmarks, visit performance.modular.com. The AI Engine is still in closed preview — you can sign up here to be considered for early access.
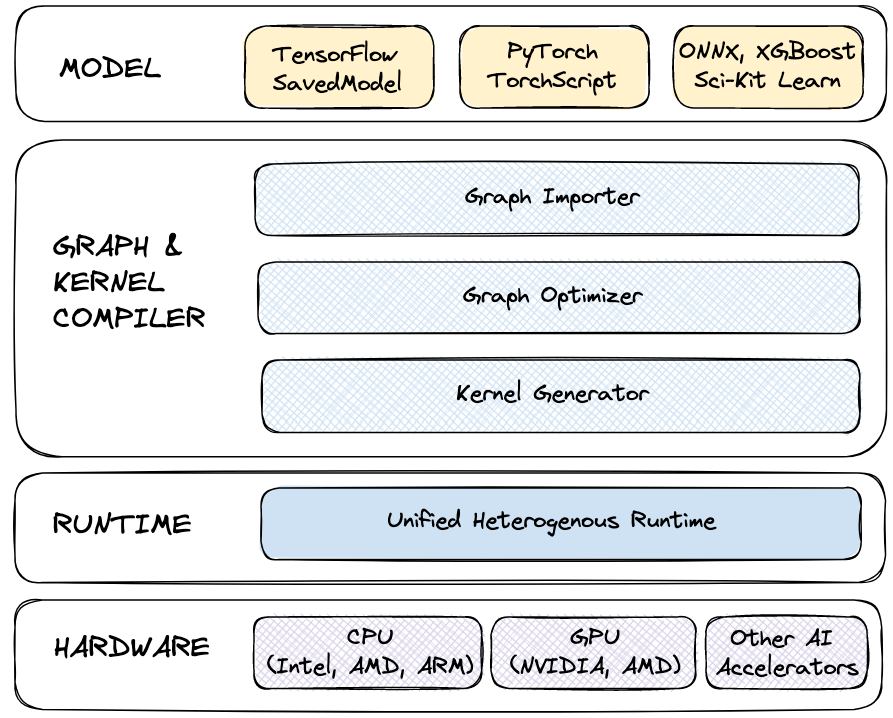
Under the hood, like most compiler toolchains, the AI Engine has four key components:
- The Importer takes a serialized model (e.g., a TensorFlow SavedModel) and converts it to a graph representation that the compiler can optimize.
- The Graph Optimizer takes this graph representation and performs graph-level optimizations (e.g., constant folding, shape inference).
- The Kernel Generator produces high-performance machine learning kernels tailored to individual architectures and microarchitectures, including advanced techniques like operator fusion.
- The Runtime executes the optimized kernel graph with low overhead to deliver state-of-the-art performance.
For the user, the AI Engine offers both Python and C/C++ APIs and integrates into popular serving frameworks like NVIDIA’s Triton Inference Server and TensorFlow Serving to deliver high-throughput inference in production. You can read more about how it achieves that in this blog post. The AI Engine is still in closed preview - sign up here to express interest in testing the AI Engine.
How Mojo integrates with the AI Engine
The AI Engine’s kernel generator generates hardware-specific optimized implementations of machine learning operators. Modular engineers initially wrote this code in MLIR directly but found it to be a productivity challenge. We decided things would be much more productive in a high-level language with Python-like usability and safety and predictability guarantees of systems programming languages like C and Rust. As such, Mojo was born to satisfy the needs of Modular’s internal development efforts on the AI Engine.
Today all of the AI Engine’s optimized kernels are written in Mojo, allowing the Engine’s capabilities to be extended to support new and exotic model architectures where custom kernels for operators can be authored directly in Mojo without resorting to low-level C, C++, or CUDA programming. While you can use the AI Engine as a drop-in replacement for your existing models without Mojo, if you’re an AI developer creating custom operators and model architectures, Mojo can dramatically improve your productivity in authoring custom kernels enabling you to deploy models to production in the shortest possible time.
Sign up for early access to the AI Engine and learn more:
- AI Engine overview: https://www.modular.com/engine
- AI Engine performance dashboard: https://www.modular.com/engine
- Modular launch blog post: A unified, extensible platform to superpower your AI
- Model serving blog post: Accelerating AI model serving with the Modular AI Engine
- Documentation: https://docs.modular.com/engine/
What is Mojo🔥 ?
While Mojo’s origin story was for authoring kernels for the AI Engine, thats not its only purpose. Mojo is designed to become a superset of Python over time by preserving Python’s dynamic features while adding new primitives for systems programming.
It’s a brand-new programming language that combines the usability of Python with powerful compile-time metaprogramming, integration of adaptive compilation techniques, caching throughout the compilation flow, and other features that are not supported by existing languages. In his blog post, Jeremy Howard described Mojo as “Python++” since it enhances Python’s capabilities, enabling it to enter new domains.
Mojo is still in early development, but the value of Mojo is in its “depth” as a language. Mojo is not the first programming language to execute Python-like syntax on accelerators, but it is the first to enable high-level AI developers direct low-level control over hardware — unlocking researchers to innovate at all levels of the stack.
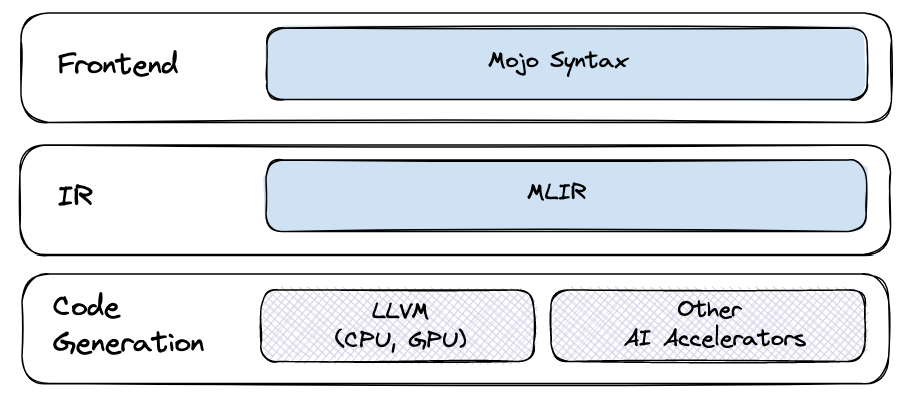
Mojo has a syntax that looks like Python, but unlike the default “CPython” implementation, which uses an interpreter, Mojo is compiled. The Mojo compiler lowers Mojo code, performs optimizations, and generates code for specific hardware targets. Mojo also offers low-level types like the SIMD type, which represents a low-level vector register directly in hardware for writing hardware-optimized code.
Mojo has already had its first success story — the AI Engine. The AI Engine’s performance results on the performance dashboard are the result of the improved engineering velocity of the AI Engine’s team in supporting popular models on a variety of hardware to deliver state-of-the-art performance. Of course, Mojo was not only built for Modular’s use cases, but our community users have already started creating amazing projects like mojo-libc.
You can get started with Mojo today on the Mojo Playground environment, which allows you to walk through Jupyter Notebook examples, create your own and share them with the Mojo community on Discord. One of the most frequently requested features is the ability to download Mojo and run it on your local computer — we’re working on this, so stay tuned!
Here are additional resources to get started with Mojo:
- Mojo overview: https://www.modular.com/mojo
- Mojo Playground: https://playground.modular.com/
- Modular launch blog post: A unified, extensible platform to superpower your AI
- LLM language post: Do LLMs eliminate the need for programming languages?
- Documentation: https://docs.modular.com/mojo/
Mojo and the AI Engine - better together!
The AI Engine and Mojo were designed to be used together. In the near term you will be able to use the AI Engine to deploy widely used models for production and deliver high-performance, low-latency inference on a range of hardware architectures. With Mojo’s Python-like usability, you can easily extend the AI Engine’s capabilities for tasks such as writing performant pre- and post-processing operations (e.g. tokenization, image transformations, non-max suppression, etc.), replacing high-latency operations and custom fused kernels to deliver even greater performance. Together the AI Engine and Mojo will allow you to accelerate all parts of your AI development pipeline.
In the longer term, we expect the AI Engine and Mojo together to accelerate workloads in several domains beyond AI. Python is used in multiple domains including data analytics, image and signal processing, scientific and numeric computing, gaming, 3D graphics, network programming, database access and others. As AI proliferates into these and other domains, we expect the AI Engine and Mojo to play an important role in accelerating applications in these domains and unlock the next wave of AI innovations.
Ultimately they are productivity tools in a developer’s toolbox, and a tool’s potential is only limited by the user’s creativity. We’re excited to see what challenges you’ll solve with them and what new innovations they’ll help you unlock. We look forward to hearing from you about your use-cases, feature requests and product feedback.
In the meantime:
- Head over to the Mojo Playground to test the latest release of Mojo right now!
- Sign up here to express interest in testing the AI Engine
- Join our warm, welcoming and awesome community on Discord
- Discuss Mojo and the AI Engine topics on GitHub discussions
Until next time 🔥!


