

.jpeg)
AI Model Serving is more than an Engine
A few weeks ago, we announced the world’s fastest unified AI inference engine. The Modular AI Engine provides significant usability, portability, and performance gains for the leading AI frameworks — PyTorch and TensorFlow — and delivers world-leading execution performance for all cloud-available CPU architectures. Critically, it is a drop-in replacement to how you deploy AI today, including support for all AI operators, ensuring your workloads seamlessly capture these benefits out of the box.
.png)
However, as we previously discussed, running inference on a model is only part of the deployment story. Deploying AI models into production at scale requires significantly more software infrastructure and system design, as seen in the figure below as just one example. In addition to leveraging a model engine that supports multiple frameworks and hardware backends, the serving layer must account for other requirements such as high throughput (via techniques such as model concurrency and dynamic batching) and low latency, while providing ease of use, reliability, and scalability.
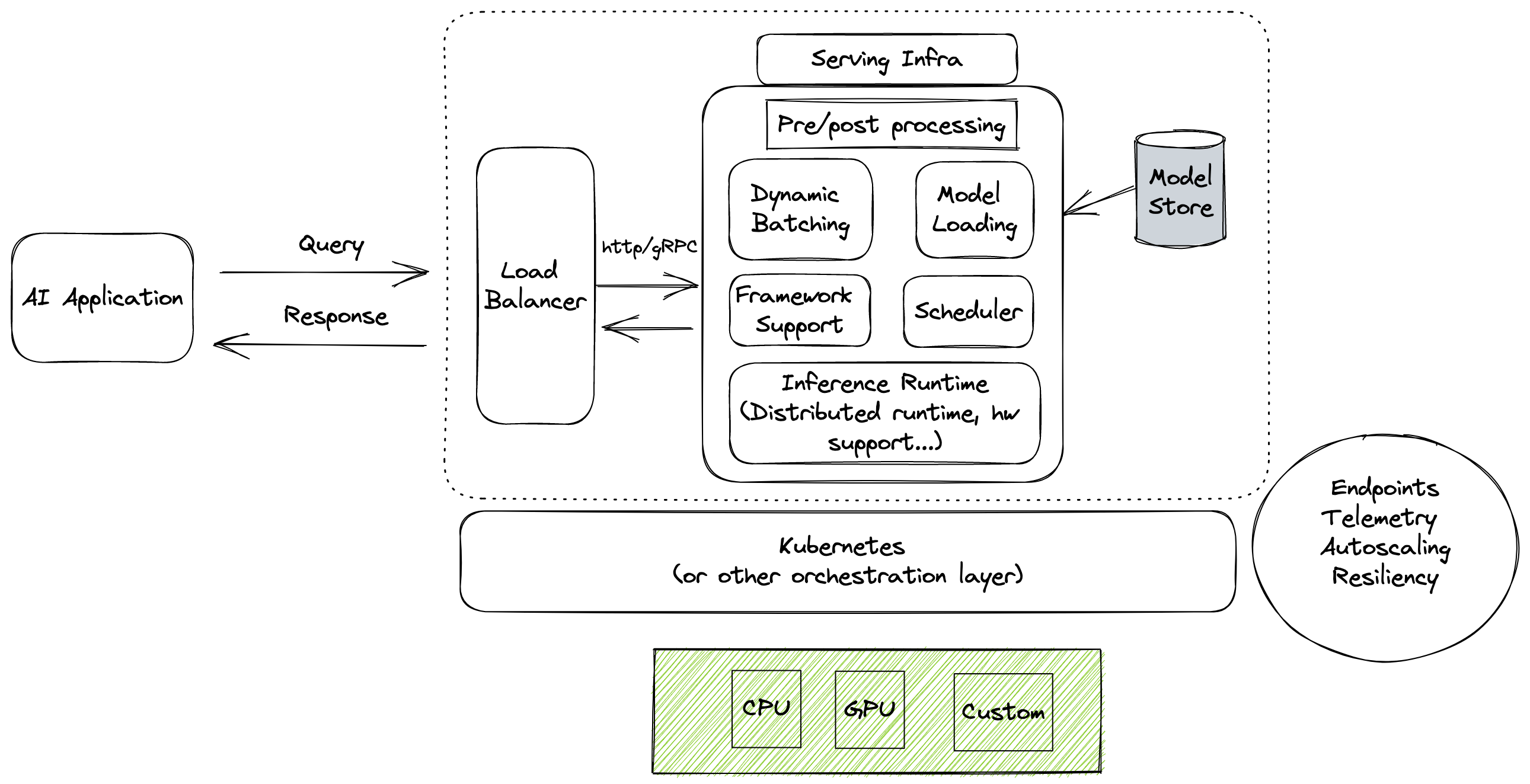
Given the complex nature of serving infrastructure, optimizing the performance of an AI application in production is not only about optimizing the backend runtime engine. Improving the engine's performance leads to bottlenecks in other parts of the stack, so tuning each stage of the end-to-end serving infrastructure, including model loading, batching, etc., is critical.
Integration into popular serving solutions
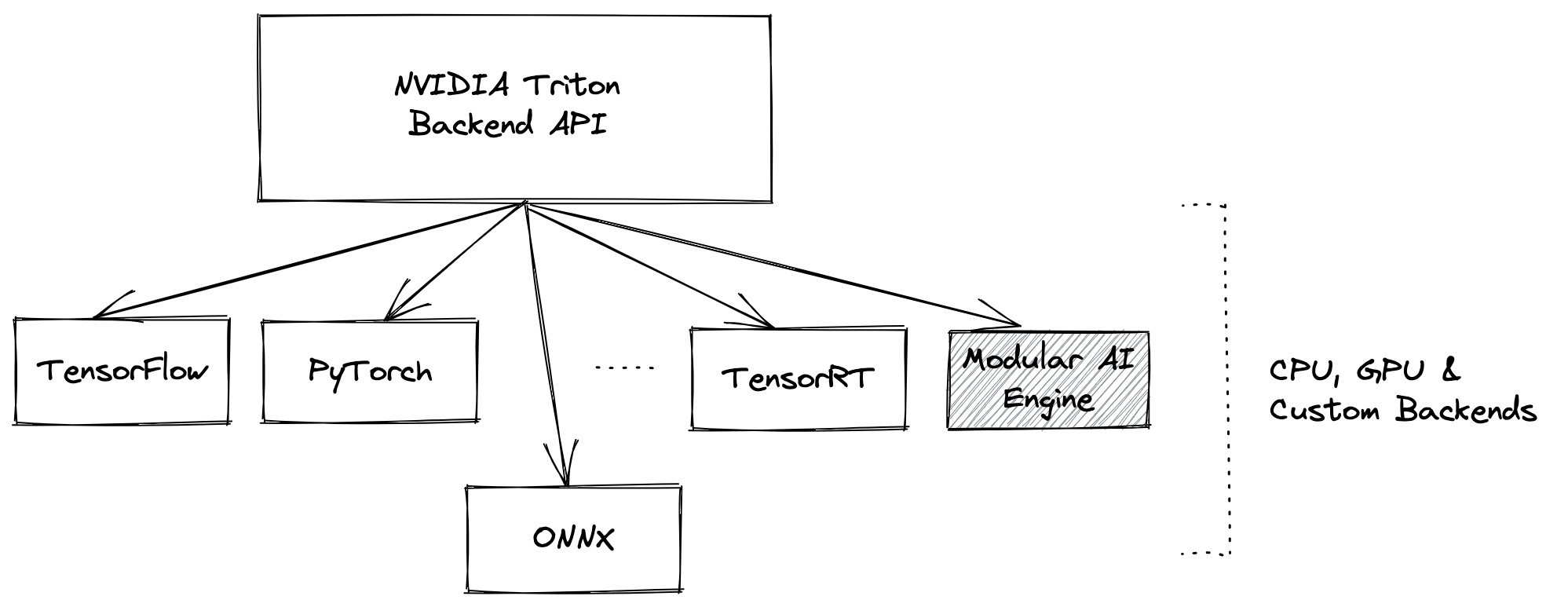
At Modular, we care about maximizing AI developer velocity by meeting customers where they are today. So in order to make deployment of the Modular AI Engine as seamless as possible, we have integrated it into NVIDIA’s Triton Inference Server and TensorFlow Serving. Both are open-source serving solutions that many of our customers are using today, and they provide useful features that simplify inference deployment, such as out-of-the-box support for metrics, dynamic batching, concurrency, and more. In the case of Triton, we used the backend API to implement a Modular AI Engine backend, as seen in the image below. With the Triton serving API remaining the same, we provide a drop-in option for customers to transparently capture all of the Modular AI Engine's benefits. We’ve worked hard to make it incredibly simple to roll out the world’s fastest AI inference engine.
Performance benefits of the Modular AI Engine for serving
To showcase the benefits of the Modular AI Engine, we analyze the performance of the Engine integrated into the Triton Inference Server on various hardware backends — Intel Skylake (c5.4xlarge on EC2), AMD EPYC (c5a.4xlarge), and AWS Graviton2 (c6g.4xlarge). We test the performance on a binary text classification problem using BERT-base, a popular transformer language model from HuggingFace. We use a sequence length of 128 and analyze the effects of increasing concurrency and enabling server-side dynamic batching on the Modular backend to simulate a production deployment of the model. And we compare the results of the Modular AI Engine to the out-of-the-box performance of TensorFlow and PyTorch backends. We also did not change any default settings (e.g., dynamic batch size) on Triton to keep this as consistent as possible with how our customers use it in production.
Throughput
The first set of charts below show throughput (queries per second) as we scale the number of concurrent threads on the serving system. Starting with our results on the AWS Graviton 2, we see that Modular is able to achieve 2.3x better throughput as compared to TensorFlow and 1.5x-1.7x as compared to the PyTorch 2.0 backend.

We see roughly the same improvement on AMD as well, with Modular 2.3x better than TensorFlow and 1.5x-1.7x as compared to PyTorch 2.0. Also interesting to note is that with dynamic batching enabled, we can see an improved scaling effect on the throughput as we increase the number of concurrent requests (or threads) being serviced. Not surprisingly, without dynamic batching, as the requests spend more time in the queue, the throughput stays constant.

On the Intel Skylake system, Modular has 3.6x better throughput on TensorFlow and 1.2x better throughput than PyTorch 2.0. Modular achieves a peak throughput at 42 QPS on the Intel Skylake system without changing hardware or numerics, or performing other “tricks”.

Latency
Since production deployments typically operate under a latency budget, we also measure the latency of the Modular AI Engine compared to both TensorFlow and PyTorch 2.0. On the Graviton2 system, at the peak throughput, Modular is able to achieve 2.3x lower latency compared to TensorFlow and 1.5x-1.7x lower latency compared to PyTorch 2.0 as the number of concurrent requests is increased.

Similarly, on AMD, Modular is 2.3x lower latency than TensorFlow and 1.5x-1.7x lower latency than PyTorch 2.0.

On the Intel Skylake system, Modular has 2x lower latency compared to TensorFlow and 1.2x lower latency compared to PyTorch 2.0. Note that the PyTorch implementation is using the optimized Intel OneDNN Graph BERT implementation, and as you can see, our ability to scale across multiple architectures while providing unmatched latency performance makes the Modular AI Engine world leading.

Further, we are showcasing significant wins against a very common and highly tuned model, and the generality of our stack enables enormous improvements across many other models. You can combine all these benefits for a truly industry defining solution — much greater flexibility, usability (e.g. full support for dynamic sequence lengths), integration with Mojo and of course performance portability across hardware architectures.
What’s Next?
You can check out the complete NVIDIA Triton serving results using Modular’s AI Engine on our Performance Dashboard. However, this is only the beginning. Modular is working on an accelerated AI compute platform that can serve performance-sensitive AI models at scale, and we have many more optimizations to come as we build out our platform. Stay tuned! In the meantime, visit www.modular.com to learn more and sign up for our newsletter to get product updates and notifications when new results are available on our performance dashboard.


