
Hippocratic AI partners with Modular to power flexible, high-quality inference for real-time patient conversations
<500ms
Time to first token (TTFT)
30%
Faster end-to-end latency (p99)
22%
Faster end-to-end latency (mean)
01
Time to first token (TTFT)
02
Faster end-to-end latency (p99)
03
Faster end-to-end latency (mean)

Problem
Hippocratic AI builds safety-focused AI health agents that converse with patients, helping to close the global shortfall of 15 million healthcare workers. Their Polaris system orchestrates dozens of specialized models in parallel to ensure every interaction is clinically safe, with error rates lower than human clinicians. Hippocratic AI’s systems scale to contacting tens of thousands of patients daily and build trust that AI products can be used in highly regulated industries.
For real-time voice to work, latency can't exceed 800ms per conversational turn. Each patient session runs 40–80 turns, with the first turn processing ~10,000 tokens of context, all while safety models analyze the same conversation in parallel. As Hippocratic AI scaled to more concurrent patients per GPU node, existing inference frameworks couldn't hold tail latencies tight enough to keep conversations feeling natural.
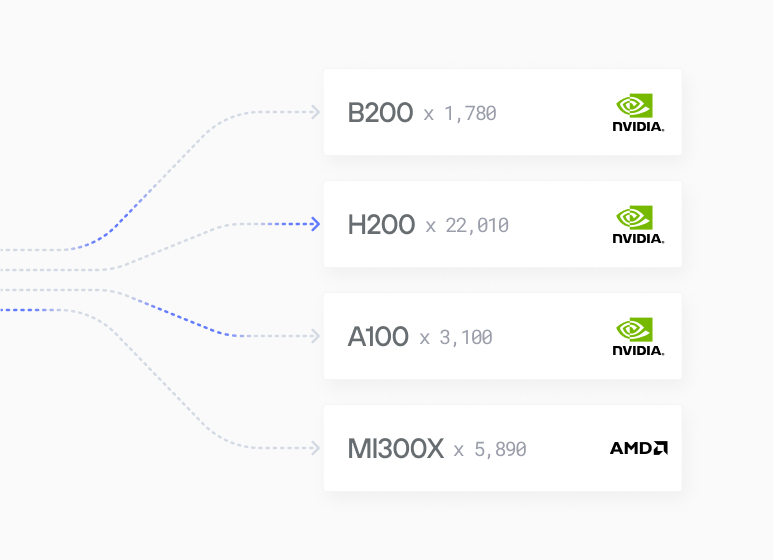
As Hippocratic AI scales globally, they face a challenge familiar to every team running large models in production: GPU supply is fragmented across vendors and clouds, costs vary widely, and being locked to a single accelerator limits both supply resilience and unit economics.
Solution
Our partnership with Hippocratic AI is a joint effort where both teams worked together to integrate Modular's MAX framework across both NVIDIA and AMD GPUs in Hippocratic AI's inference pipelines, running Llama 3.1 405B for their Polaris system.
Modular has rebuilt the AI infrastructure stack from the ground up. From highly optimized, portable kernels written in Mojo, to model serving infrastructure with MAX, to cloud orchestration that can be deployed in Modular's cloud or yours. This vertically integrated approach, built over years of deep infrastructure investment, is what enables Modular to extract performance that frameworks built on top of existing components can't match.
MAX's delivered across every dimension that matters:
- Keep every conversation instant. MAX delivers sub-second mean time to first token (TTFT. Patients get responsive, natural interactions with no perceptible delay.
- Performance without quality trade-offs. Many inference frameworks reach for aggressive optimizations that quietly degrade model accuracy. MAX takes a different approach: its kernels and serving stack are designed to preserve the numerical behavior of the underlying model, so the extensive clinical safety evaluations Hippocratic AI runs on Polaris carry over directly into production.
A faster path to new hardware. As new accelerators come to market, MAX's portable kernel architecture means Hippocratic AI doesn't have to wait for vendor-specific framework support to evaluate them.
Results
By standardizing on MAX, Hippocratic AI unlocks a heterogeneous deployment strategy that was previously out of reach.
Modular's collaboration with Hippocratic AI is just getting started. Because MAX's portability comes from its optimized kernel library and scheduling architecture rather than vendor-specific glue, these same benefits generalize to the large reasoning models becoming the backbone of production AI deployments. MAX is ready to deliver flexible, hardware-agnostic deployment for the most advanced frontier LLMs used in production.
About Hippocratic
Hippocratic AI has developed the safest generative AI Agents for healthcare. The company believes that generative AI has the ability to bring healthcare abundance to every person in the world. The company focuses on building non-diagnostic patient-facing clinical AI agents and does not allow its agents to be used to prescribe or diagnose. Hippocratic AI has received a total of $404 million in funding and is backed by leading investors, including Andreessen Horowitz, General Catalyst, Kleiner Perkins, Avenir, NVIDIA’s NVentures, Premji Invest, SV Angel, Google’s CapitalG, and numerous health systems. Learn more at https://hippocraticai.com/.
Request a demo of this use case
If you're deploying large language models for inference, request a demo today. Excited to chat!
Case Studies





Scales for enterprises


Sign up today
Signup to our Cloud Platform today to get started easily.
Sign Up
Browse open models
Browse our model catalog, or deploy your own custom model
Browse models