
🔥 Modular 2025 Year in Review
Our four-part series documenting the path to record-breaking matrix multiplication performance became essential reading for anyone serious about LLM optimization. The series walks through every optimization step—from baseline implementations to advanced techniques like warp specialization and async copies—showing you exactly how to extract maximum performance from cutting-edge hardware.

The path to Mojo 1.0
While we are excited about this milestone, this of course won’t be the end of Mojo development! Some commonly requested capabilities for more general systems programming won’t be completed for 1.0, such as a robust async programming model and support for private members. Read below for more information on that!


Modular 25.7: Faster Inference, Safer GPU Programming, and a More Unified Developer Experience
Today, we’re excited to release Modular Platform 25.7, an update that deepens our vision of a unified, high-performance compute layer for AI. With a fully open MAX Python API, an experimental next-generation modeling API, expanded hardware support for NVIDIA Grace superchips, and a safer, more capable Mojo GPU programming experience, this release moves us closer to an ecosystem where developers spend less time fighting infrastructure and more time advancing what AI can do.




Modular 25.6: Unifying the latest GPUs from NVIDIA, AMD, and Apple
We’re excited to announce Modular Platform 25.6 – a major milestone in our mission to build AI’s unified compute layer. With 25.6, we’re delivering the clearest proof yet of our mission: a unified compute layer that spans from laptops to the world’s most powerful datacenter GPUs. The platform now delivers:
.png)
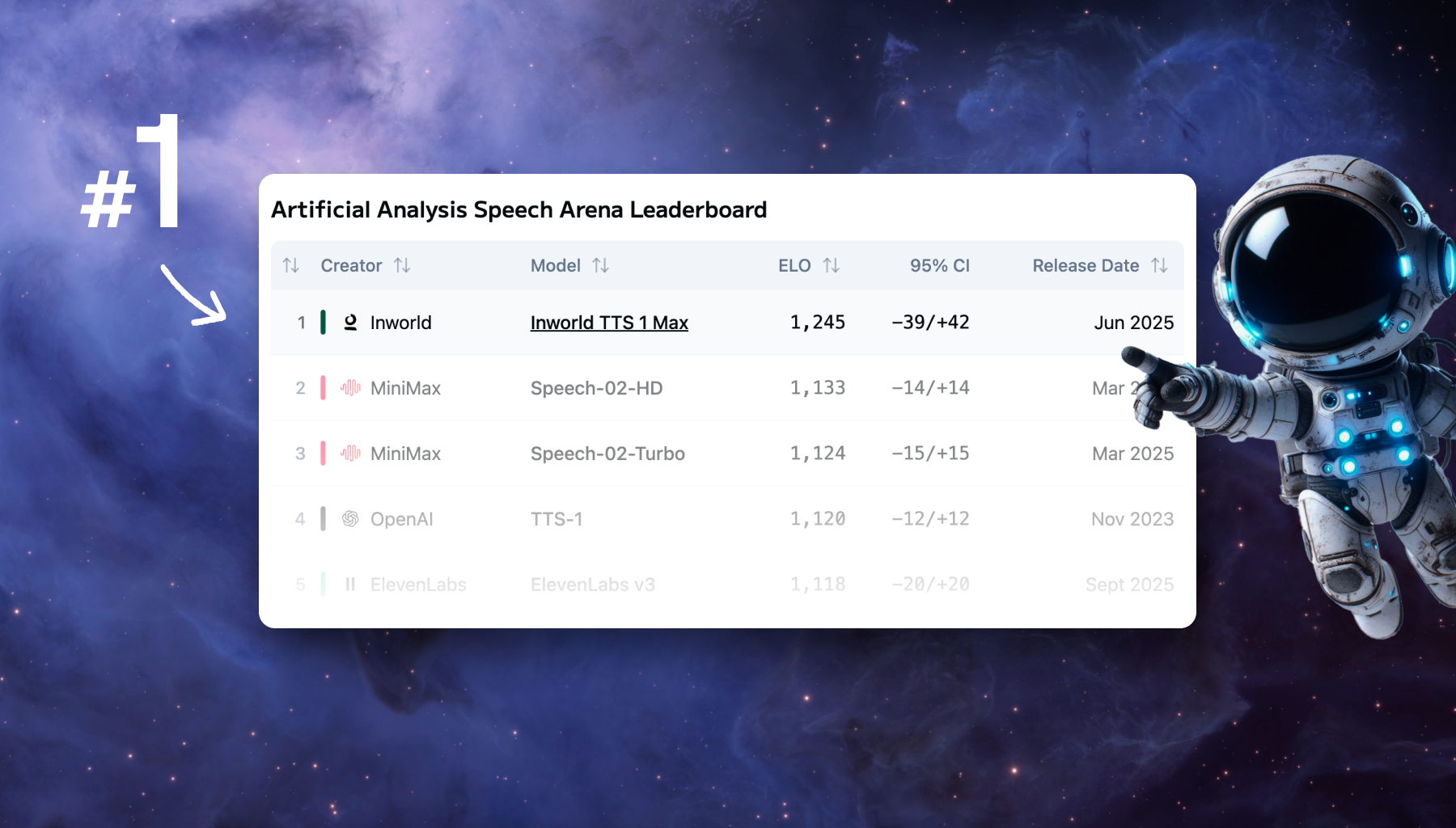
Modverse #51: Modular x Inworld x Oracle, Modular Meetup Recap and Community Projects
The Modular community has been buzzing this month, from our Los Altos Meetup talks and fresh engineering docs to big wins with Inworld and Oracle. Catch the highlights, new tutorials, and open-source contributions in this edition of Modverse.
Start building with Modular
Quick start resources
Get started guide
With just a few commands, you can install MAX as a conda package and deploy a GenAI model on a local endpoint.
Browse open source models
500+ supported models, most of which have been optimized for lightning fast speed on the Modular platform.
Find examples
Follow step by step recipes to build Agents, chatbots, and more with MAX.