Blog

Democratizing AI Compute Series
Go behind the scenes of the AI industry with Chris Lattner
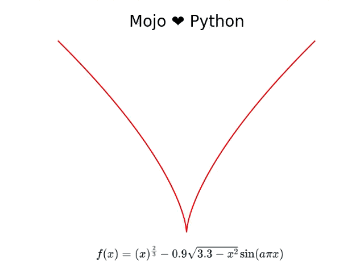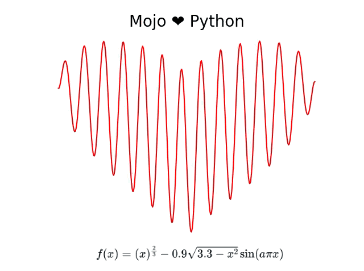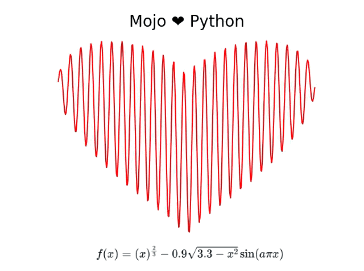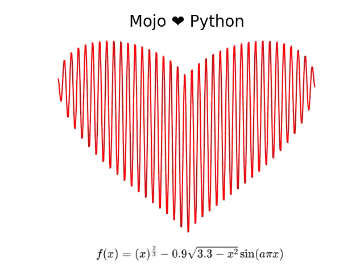
Mojo🔥 ♥️ Python: Calculating and plotting a Valentine’s day ♥️ using Mojo and Python
On Valentine’s Day yesterday, I wanted to create something special to celebrate my love for Mojo and Python. My search on the interwebs led me to a nifty little equation that plots a heart. The equation is quite simple and I’ll refer to this as the “heart equation” through the rest of this blog post

Mojo vs. Rust: what are the differences?
Mojo is built on the latest MLIR compiler technology, an evolution of LLVM which Rust lowers to. This enables programmers to write code optimized for different CPU architectures, and use the same ergonomic programming model to compile and run native GPU kernels

What is loop unrolling? How you can speed up Mojo🔥 code with @unroll
Open any introductory programming book and you’ll find several pages dedicated to structured programming concepts, i.e. making use of loops, conditions and functions extensively for better clarity and maintainability for your code. It helps you express your ideas and solutions neatly and elegantly in code. However, these benefits come at a cost: performance overhead.

Mojo🔥 SDK v0.7 now available for download!
Mojo SDK v0.7 is the first big release of Mojo🔥 in 2024, and it’s chock full of new language and standard library feature goodness. In this blog post, I’ll share some of the key highlights from this release with examples, and discuss what they are and when to use them. I’m only going to cover the new features, for a complete list of what’s new, what’s changed, what’s removed, and what’s fixed in this release, be sure to check out the changelog in the Mojo documentation.

Mojo 🔥 lightning talk ⚡️ one language for all AI programming!
Did you catch Fabian's presentation at SINTEF? If you missed out, he'll be doing it again in Oslo, Norway on the 15th of February!By popular request, we're publishing the slides here, and will soon have video to go with it. Make sure to subscribe to our YouTube channel to get the alert!



What’s new in Mojo SDK v0.5?
Mojo SDK v0.5 is now available for download and includes exciting new features. In this blog post, I’ll discuss what these features are and how to use them with code examples. ICYMI, in last week’s Modular community livestream, we dove deep into all things Mojo SDK v0.5 with live demos of the examples shared in this blog post, while answering your questions live!

.png)
Using Mojo🔥 with Python🐍
Mojo allows you to access the entire Python ecosystem, but environments can vary depending on how Python was installed. It's worth taking some time to understand exactly how modules and packages work in Python, as there are a few complications to be aware of. If you've had trouble calling into Python code before, this will help you get started.

Democratizing Compute
Go behind the scenes of the AI industry in this blog series by Chris Lattner. Trace the evolution of AI compute, dissect its current challenges, and discover how Modular is raising the bar with the world’s most open inference stack.

Matrix Multiplication on Blackwell
Learn how to write a high-performance GPU kernel on Blackwell that offers performance competitive to that of NVIDIA's cuBLAS implementation while leveraging Mojo's special features to make the kernel as simple as possible.

Structured Mojo Kernels
Learn how Mojo simplifies GPU programming with modular kernel architecture, compile-time abstractions, and zero-cost performance across modern GPU hardware.

Software Pipelining for GPU Kernels
Explore software pipelining for GPU kernels from first principles. We formalize dependencies as a graph, solve for the optimal schedule with a constraint solver, and show how it all integrates into MAX via pure Mojo.

Why LLM Inference Needs a New Kind of Router
This series walks through why traditional HTTP routing breaks down under LLM workloads and how Modular Cloud solves it with a three-layer architecture built for cache-aware routing.

TileTensor
This series walks through how Modular built TileTensor, a Mojo tensor type that lets kernel authors express complex memory layouts precisely, safely, and efficiently.
No items found within this category
We couldn’t find anything. Try changing or resetting your filters.

Sign up today
Signup to our Cloud Platform today to get started easily.
Sign Up
Browse open models
Browse our model catalog, or deploy your own custom model
Browse models