.png)
Today’s 26.2 release expands the Modular Platform’s modality support to include image generation and image editing workflows. This extends our existing support for text and audio generation. In the 26.2 version Black Forest Labs' FLUX.2 model variants are supported with over a 4x speedup over state-of-the-art.4
Mojo 26.2 makes the language significantly more productive for AI-assisted GPU kernel development. This release introduces simplifying language features alongside new AI coding skills purpose-built for writing high-performance, portable GPU kernels. Combined with over 750K lines of open-source Mojo kernel code, coding agents like Claude, Cursor, and Codex can now easily write, port, and optimize kernels across any hardware target. Mojo’s Python-like readability keeps generated code correct and easy to understand.
MAX: FLUX image generation, built into the stack you already use
The Modular Platform unifies AI under a single framework. We started with text, we quickly expanded to audio, and today we’re adding image generation along with image editing — all with the state-of-the-art performance you’d expect from Modular.
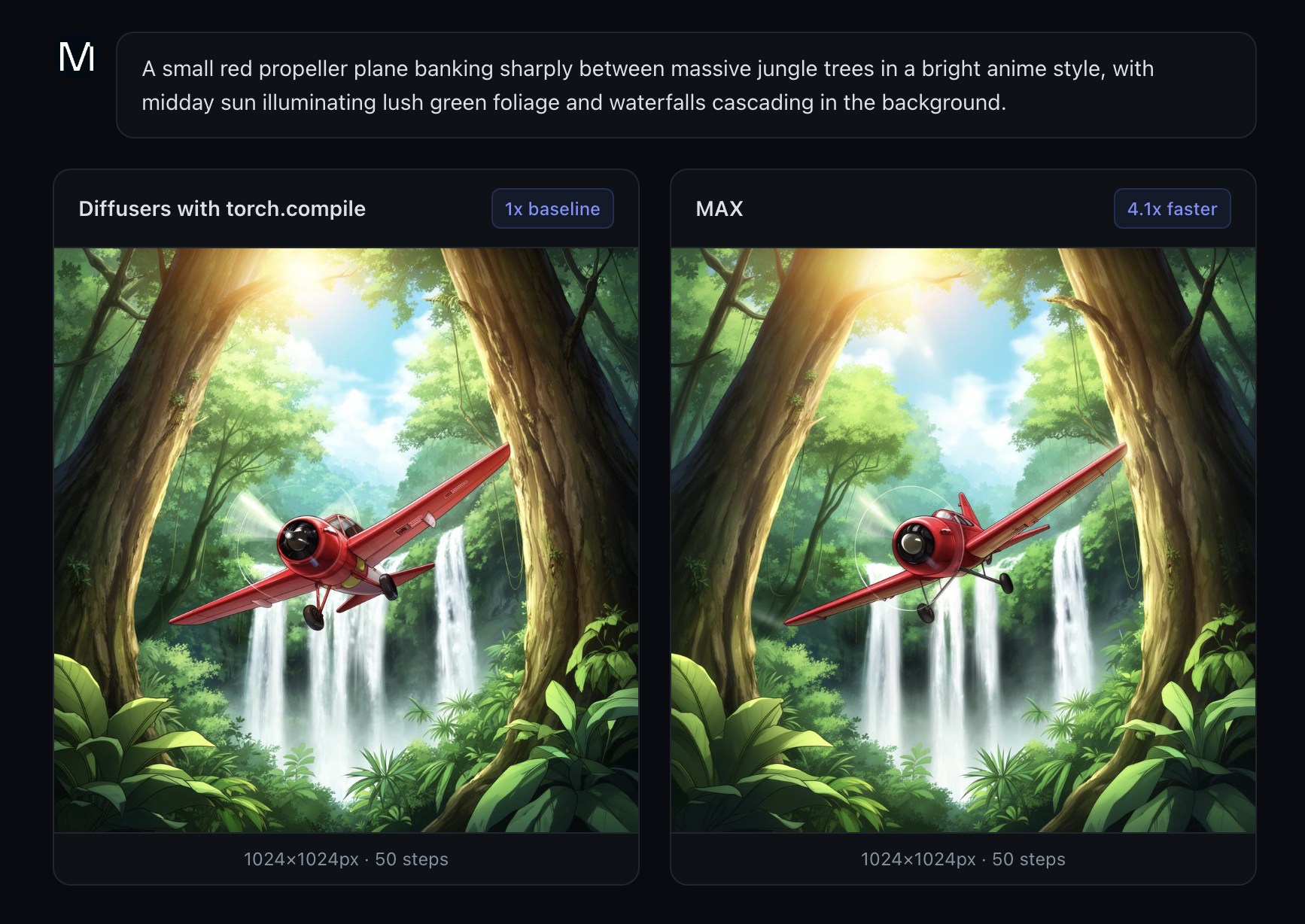
If you’re already running the Modular Platform in production, adding image generation requires no changes. Just swap the endpoint. As a result, you'll experience around a 4x latency speedup on the FLUX.2 family of models (compared to PyTorch Diffusers with torch.compile). The results are image resolution dependent:
| Image resolution | Diffusers vs. MAX speedup |
|---|---|
| 1024x1024 | 4.1x |
| 1360x768 | 3.4x |
| 768x1360 | 4.0x |
These performance wins you get from MAX come with no noticeable quality degradation. The figure below shows the results from both torch.compile (left) and MAX (right). The image quality is virtually identical, while the performance of MAX is noticeable - a 4x that of torch.compile. The tolerance for image quality is configurable, and we are able to get good quality images in sub-second. This opens up a large amount of workflows that were otherwise blocked because the lack of almost real time image generation.
FLUX.2-dev performance translates to AMD MI355X with MAX exceeding the performance of torch.compile by 1.25x and only 4% slower against B200 for time-to-generation.
When looking at this from the TCO lens, this means immediate TCO savings for Modular Platform users. To estimate the TCO savings, we surveyed the GPU market and found that the MI355X rates are usually around 70-80% that of B200. Applying that to our benchmark generation times, this translates to a 25% TCO savings when deploying a model on AMD hardware without a significant tradeoff in generation speed.
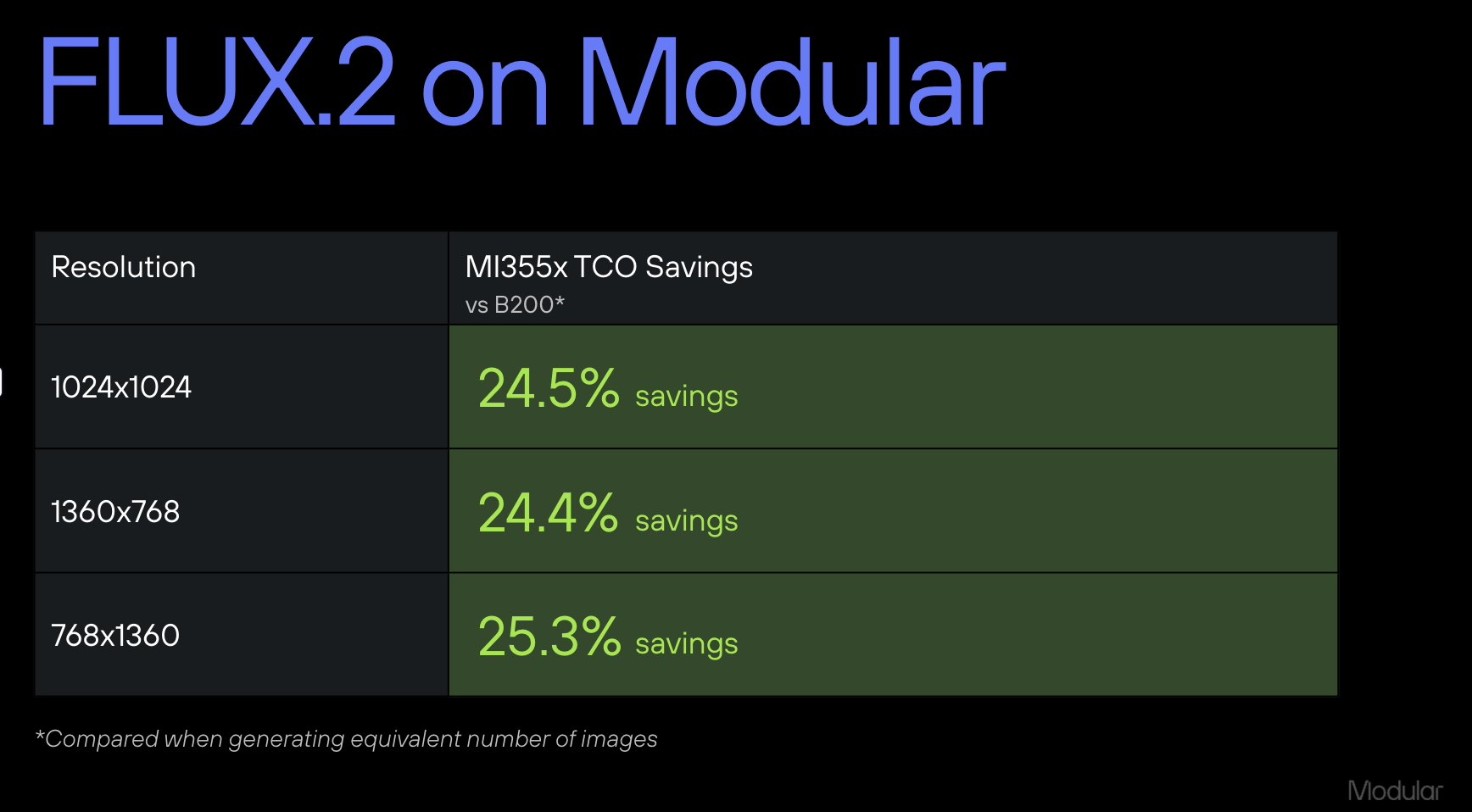
Image generation with MAX is available today in our cloud and enterprise offerings. We are continuously improving the performance of image generation workflow, and project up to 7x speedup over SOTA over the next few weeks. If you use image generation as part of your workflow and interested in the TCO and performance wins, then contact us.
Mojo: designed for the AI coding era
AI coding agents need the right foundation to build good software. In our recent analysis of Anthropic’s experiment recreating a C compiler with a team of agents, Modular CEO Chris Lattner highlighted a key insight: agents are only as effective as the systems they build on. Mojo is a new foundation for the AI systems of the future.
Its Python-like syntax, minimal boilerplate, and strong type safety make it ideal for agents: common errors are caught at compile time, cycle times are shorter, and clear error messages mean fewer tokens spent on debugging. At the same time, its unique metaprogramming capabilities enable zero-cost abstractions — including readable memory layouts and composable kernel design patterns — that still deliver bare-metal performance across a wide range of hardware.
To help agents write better Mojo code, we’ve open-sourced Modular’s Mojo kernel implementations and continuously refined agent guidance through CLAUDE.md files and READMEs across the repo. In 26.2, we’re taking this further with a new set of
Mojo coding agent skills that plug directly into AI coding assistants, correcting outdated patterns and enforcing idiomatic code.
Install our Mojo skills with this command:
The skills are especially useful for translating existing CUDA or Triton kernels to Mojo — point your agent at a kernel and the skill handles structural translation while you focus on Mojo-specific optimizations.
Our initial skills are just the beginning. We're working to expand them to cover hardware-specific optimizations, PyTorch-to-MAX model translation, and kernel profiling and debugging. We’ll continue to evolve these skills, and welcome future external contributions to expand their capacity.
In addition, with the release of the new 5th edition of the Programming Massively Parallel Processors book, we have open sourced Mojo versions of all of the examples in the book. This provides both a great learning resource for CUDA to Mojo and excellent example resources for fueling translation of existing CUDA kernels to Mojo. You can also explore our Mojo GPU puzzles to dive deeper.


