

As 2025 draws to a close, we want to reflect on the extraordinary year we've had at Modular. This year, we committed ourselves fully to a singular mission: building the AI infrastructure for the future—a unified compute layer that empowers developers and enterprises to deploy AI at any scale, on any hardware, without compromise. With that, here are the 'top ten' highlights from the year. Thank you for being a part of them.
Top Ten Highlights of 2025
1. Launching AMD Support and Achieving SOTA on AMD MI355X
When AMD launched the MI355, we achieved state-of-the-art performance in just two weeks. This accomplishment came only three months after our first AMD GPU support. The rapid achievement demonstrates how MAX's unified abstraction layer lets you deploy optimized models on new hardware without rewriting code or waiting months for vendor-specific implementations.

2. Setting Performance Records on NVIDIA Blackwell
Our four-part series documenting the path to record-breaking matrix multiplication performance became essential reading for anyone serious about LLM optimization. The series walks through every optimization step—from baseline implementations to advanced techniques like warp specialization and async copies—showing you exactly how to extract maximum performance from cutting-edge hardware.

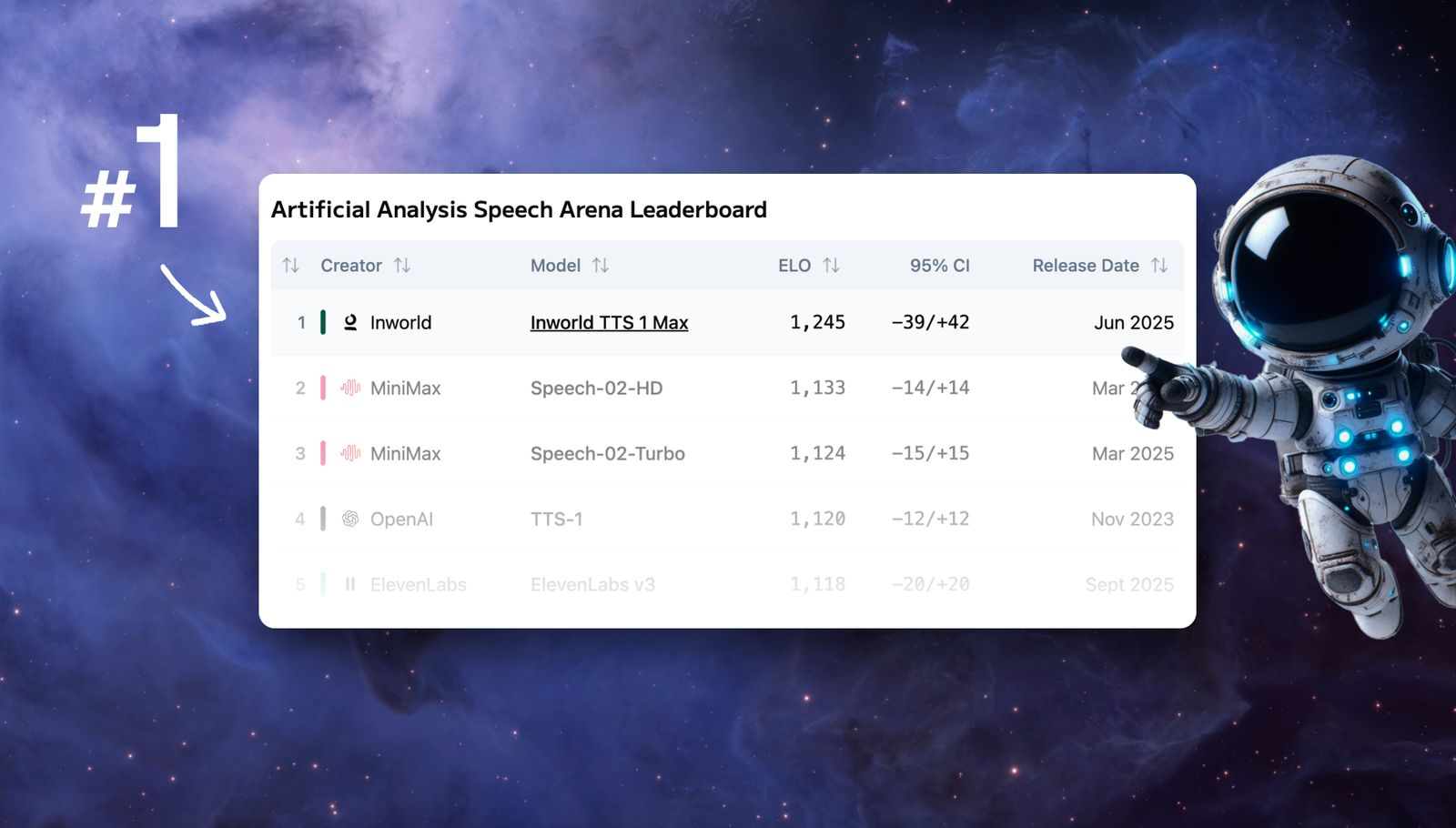
3. Powering the #1 Speech Model
Inworld TTS 1 Max, running on the Modular Platform, claimed the top spot on the Artificial Analysis Speech Leaderboard—with 70% faster latency and 60% lower costs. This means production-ready text-to-speech that's both higher quality and more economical than alternatives, proving that performance and cost efficiency don't have to be tradeoffs.
4. MAX AI Kernels and Mojo Standard Library Go Open Source
Throughout 2025, Modular open-sourced substantial portions of the Mojo and MAX codebase. We completed opening up the Mojo standard library (started in 2024), revealing our low-level GPU interactions. We then released over 450,000 lines of Mojo code for MAX kernels—the world's largest Mojo code repository. This gives developers a comprehensive reference for writing high-performance GPU kernels with memory safety guarantees and the low-level control needed for optimal hardware utilization.

5. MAX Python API Goes Fully Open Source
The MAX Python API is now fully open-sourced on GitHub—giving developers complete visibility into how MAX models are built, executed, and served across hardware. You can now inspect, modify, and contribute to the entire model execution stack, from high-level Python APIs down to the hardware-specific optimizations.

6. Mammoth Launched: Infinite scale made easy for the largest AI workloads
Our Kubernetes-native control plane for enterprise-scale GenAI deployments. Disaggregated inference, intelligent routing, multi-model orchestration—coming to a managed endpoint near you in 2026. Mammoth handles the complexity of running multiple models across distributed infrastructure, automatically scaling resources and routing requests to optimize both performance and cost.

7. New Ways to Learn GPU Programming
We launched Mojo GPU Puzzles for hands-on learning and a YouTube tutorial series for developers new to GPU concepts. Whether you're learning GPU fundamentals or sharpening advanced optimization skills, these resources let you build intuition through interactive problems and clear explanations.

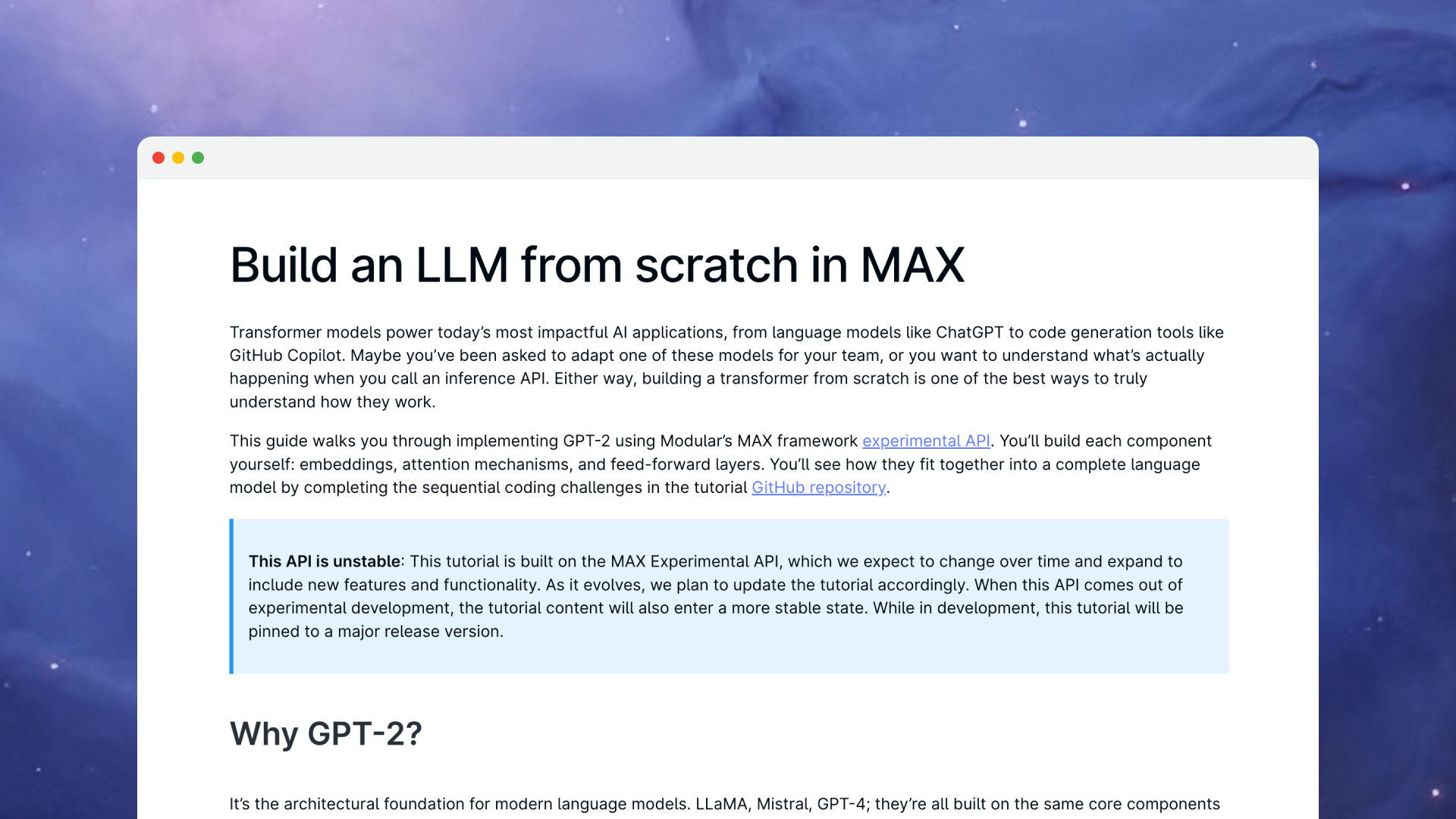
8. New MAX API
We released our new API for building custom models in MAX—and created a hands-on tutorial to showcase it. Build a transformer from scratch: embeddings, attention mechanisms, feed-forward layers, all the way to a working language model. The tutorial demonstrates how to construct production-quality models from first principles, giving you the foundation to implement novel architectures tailored to your specific use cases.
→ Build an LLM from scratch in MAX
9. Two Hackathons, One Amazing Community
From the GPU Kernel Hackathon at AGI House to Hack Weekend at our Palo Alto office—you showed up, built incredible things, and made 2025 unforgettable. Multiple hackathon projects directly contributed to the Mojo ecosystem. We also hosted community meetings throughout the year, including a Modular Meetup on December 11th that offered a look inside the MAX Framework. In the livestream below, watch Chris Lattner explain his vision for MAX as the best and most open Generative AI framework.

10. $250M to Scale AI's Unified Compute Layer
We raised $250 million to accelerate our mission—building the infrastructure layer that makes AI portable, performant, and accessible everywhere. This funding enables us to expand hardware support, grow our engineering team, and deliver enterprise-grade features that make deploying AI workloads simpler and more reliable across any infrastructure.

Thank You
To our community members who contributed code, filed issues, and shared knowledge in our forums—you shaped what Modular has become. To our design partners who pushed our platform with real-world workloads and invaluable feedback—you made us better. To everyone who joined us at conferences, hackathons, meetups, and community discussions—this year belonged to you.
2026 is going to be even bigger. Stay tuned.
— The Modular Team 🔥
Join the community · Book a demo

Discover what Modular can do for you


