

TL;DR: I took a quantization challenge designed for CUDA experts, solved it in Mojo with AI assistance, and ended up 1.07x to 1.84x faster than the state-of-the-art C++/CUDA implementation. If you've ever wanted to write GPU code but bounced off the inherent complexity, this is your sign to try Mojo.
Why This Matters
Traditional GPU programming has a steep learning curve. The performance gains are massive, but the path to get there (CUDA, PTX, memory hierarchies, occupancy tuning) stops most developers before they start. Mojo aims to flatten that curve: Python-like syntax, systems-level performance, no interop gymnastics, and the same performance gains.
I wanted to test that with a real benchmark. So I took Unsloth's NF4 dequantization puzzle, a practical workload with a published baseline, and tried to beat it using only Mojo.
Here's what happened.
The Challenge: NF4 Dequantization
NF4 is a 4-bit quantization format from the QLoRA paper. Standard 4-bit quantization divides the number line into equal parts, but this approach wastes precision. Neural network weights usually follow a bell curve or normal distribution. NF4 improves this by using quantile quantization, which places the buckets to capture an equal share of the probability mass.
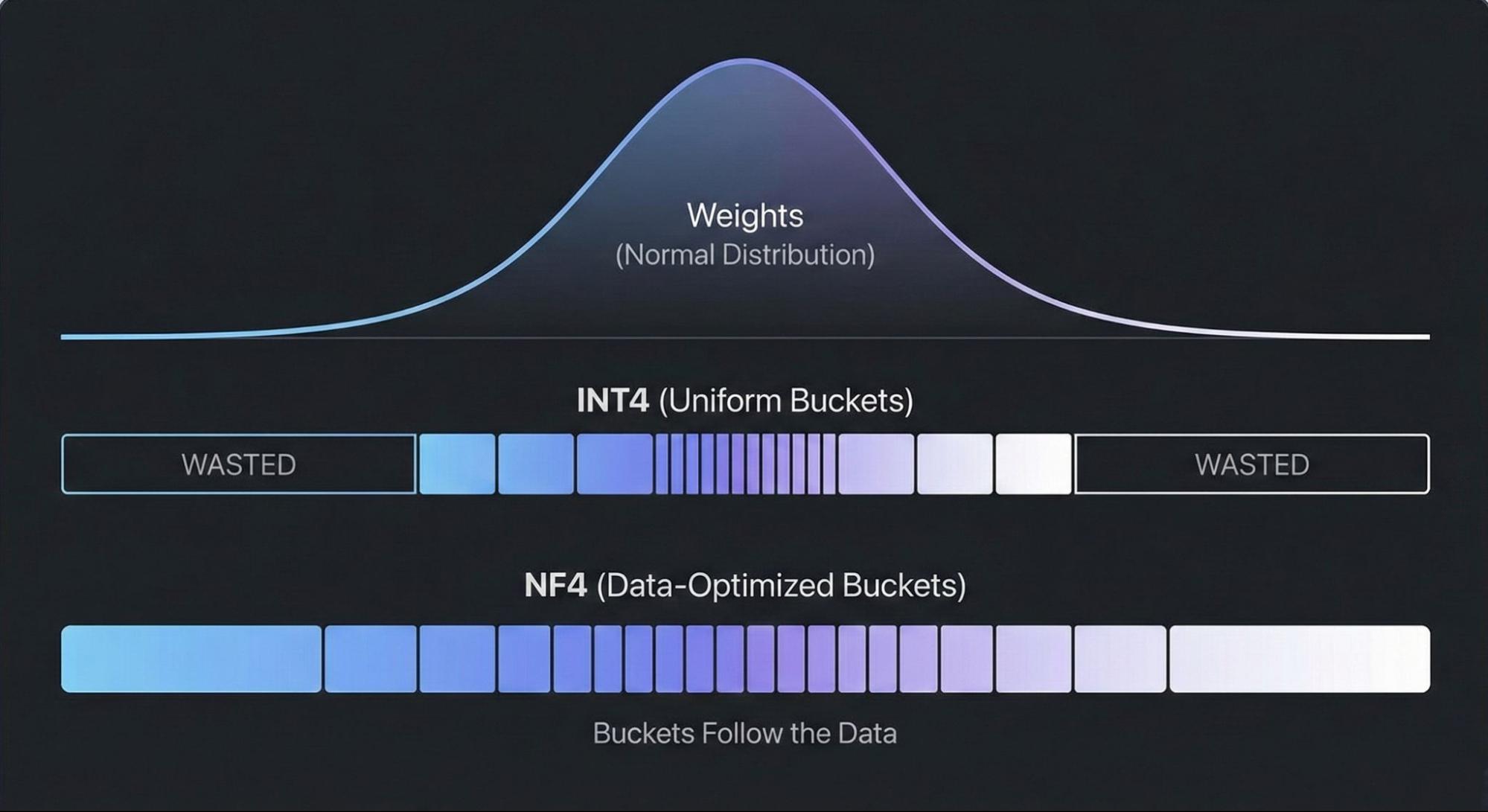
The tradeoff: NF4 dequantization is computationally heavier than standard formats, making it a good optimization target.
The puzzle rules:
- Convert NF4 weights to FP16/BF16 in a single kernel
- No large intermediate buffers
- No
torch.compile - Must run on a Tesla T4
- Target: beat Unsloth's reference time of 5.33 seconds by at least 1.15×
My Starting Point
I'm not a CUDA expert. I don't dream in PTX. But I can code in Python and TypeScript, and I'm comfortable working through problems systematically.
My workflow:
- My role: research, logic, constraints, system design
- AI tools: ChatGPT Pro + a custom Modular docs agent
- Testing: native Mojo benchmark harness (three model configs, mixed precision, 1,000 launches per matrix, strict sync for timing)
First result: 25 seconds. Five times slower than baseline.
The Optimization Path
Iteration 1: Two Kernel Designs
Within a few hours of brainstorming with AI, I had two approaches running around 8 seconds. Progress, but not enough.
Breakthrough: Packed Stores
The T4's bottleneck is memory bandwidth. Writing a single 16-bit float is inefficient; it's like sending a half-empty delivery truck. I modified both kernels to calculate two weights, pack them into a 32-bit integer, and write once.
Result: 4.25s and 4.51s. I'd passed the original 5.33s target.
Plot Twist: The Baseline Moved
When I verified against the current Unsloth implementation, it had improved to 3.70s. Ten months of optimization since the puzzle was published. Back to work.
The L4 Mystery
I ran the same kernels on an L4 GPU to understand cross-hardware behavior. The results were counterintuitive:
| Kernel | T4 | L4 |
|---|---|---|
| Unsloth Reference | 3.70s | 3.02s |
| Mojo (2D Tiled) | 4.25s | 2.59s |
| Mojo (Warp-Per-Block) | 4.51s | 2.45s |
My "slower" kernel won on L4. Why?
L2 cache. The T4 has 4 MB, which is unforgiving if your memory patterns aren't aligned. The L4 has 48 MB, which absorbed my simpler kernel's inefficiencies and let raw compute shine.
Final Push: Occupancy Tuning
Each SM can hold 64 warps. A 1024-thread block consumes 32 slots at once. With high register pressure, you fit one block per SM, leaving you with 32 warps. When those warps stall on memory, nothing else runs.
I restructured to 512-thread blocks (16 warp slots each), allowing 3-4 blocks per SM. More resident warps = more work available when others stall.
Final T4 result: 3.46 seconds.
Final Results
| GPU | Unsloth (CUDA) | GB/s | Mojo | GB/s | Speedup |
|---|---|---|---|---|---|
| T4 | 3.70s | 162.6 | 3.46s | 173.7 | 1.07× |
| L4 | 3.00s | 200.3 | 2.40s | 250.2 | 1.25× |
| A100-40GB | 1.21s | 498.2 | 0.66s | 916.2 | 1.84× |
| H100-PCIe | 0.62s | 973.9 | 0.41s | 1474.1 | 1.51× |
Layout Constants
The Final Kernel
Three optimizations:
- 512-thread blocks for better occupancy
- Packed 32-bit stores to reduce memory transactions
- Manual unrolling to process two bytes per thread
What I Learned
Mojo's advantage is that it stays out of your way. I tried a similar kernel in Triton recently but there was no obvious path for packed stores or manual unrolling. I spent time fighting the abstraction instead of experimenting. With Mojo, I could quickly test different layouts and juggle two kernel architectures simultaneously.
AI-assisted development works for GPU code. The combination of a custom docs agent and systematic experimentation let me move fast despite my lack of CUDA background.
Hardware differences matter more than I expected. The same kernel can win on one GPU and lose on another. Understanding why (in this case, L2 cache size) is where the real learning happens.
Try It Yourself
If you've been "GPU curious" but bounced off the tooling complexity, Mojo's GPU Puzzles are a good entry point. The fundamentals transfer, and you might find it more approachable than you expected.
Credit to the Unsloth team for the puzzle notebook; this work builds on theirs.
If you have questions, reach out on X @davidrobertson or follow my work on GitHub @drobertson-dev.


