.png)

Today we’re releasing Modular 26.1, a major step toward making high-performance AI computing easier to build, debug, and deploy across heterogeneous hardware. This release is focused squarely on developer velocity and programmability—helping advanced AI teams reduce time to market for their most important innovations.
Modular 26.1 centers on a new MAX Python API that simplifies building and deploying high-performance GenAI models across heterogeneous hardware. This release also improves the strength and ergonomics of our APIs within Mojo and includes new DevEx improvements to error reporting, language features to catch more bugs at compile time, and expanded Apple silicon GPU support.
26.1 release highlights include:
- MAX Python API out of experimental – PyTorch-like modeling with eager mode for debugging,
model.compile()for production - MAX LLM Book now stable – build transformers from scratch at llm.modular.com
- Growing community contributions – Qwen3 embeddings, BERT, Mamba, visual generation pipelines, and more from external contributors
- Mojo API and ergonomics improvements – including compile-time reflection, linear types, typed errors, better error messages
From Prototype to Production, Faster with MAX
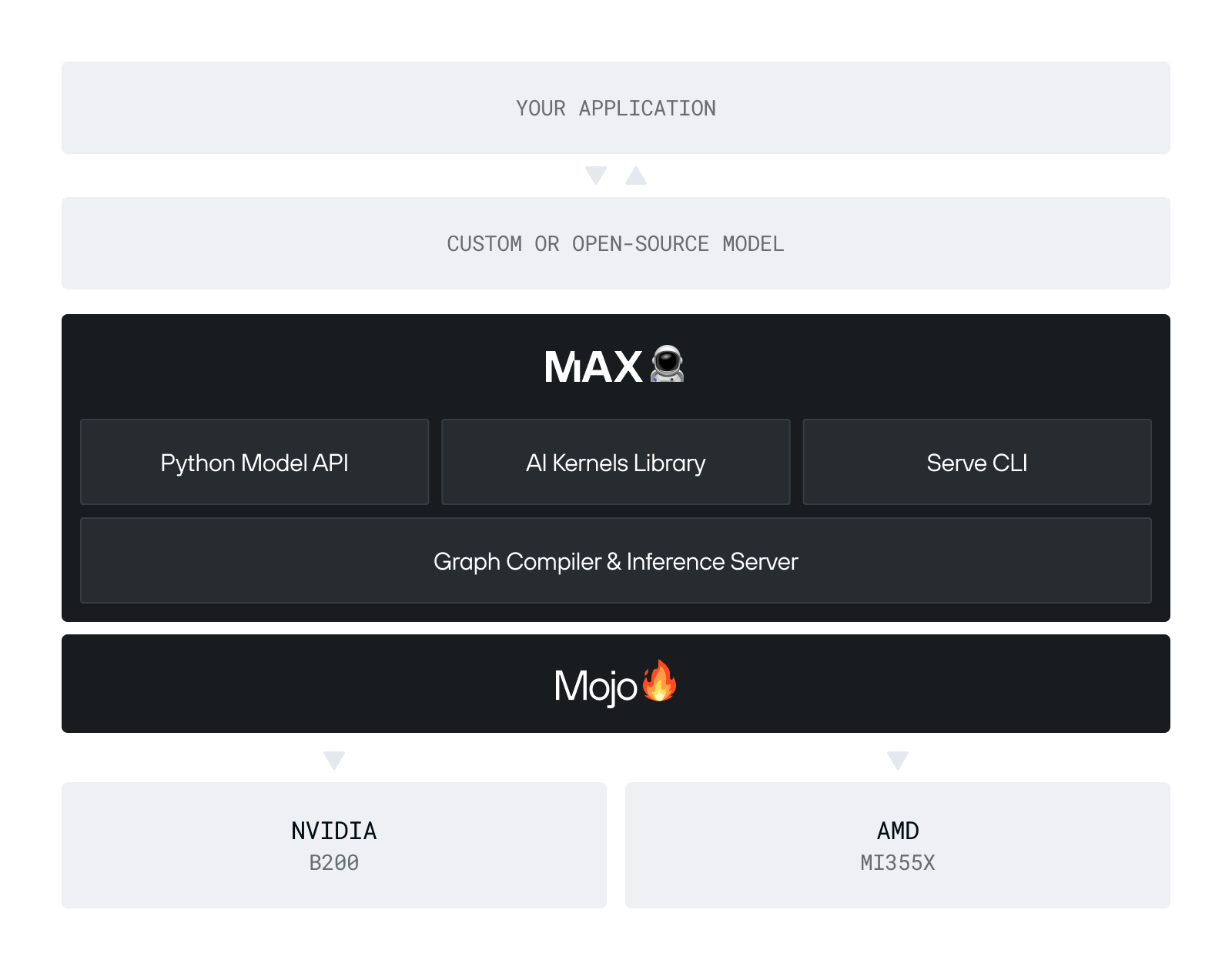
We generally describe MAX as an AI modeling and serving framework that delivers state-of-the-art performance and cost efficiency for production inference. But one of MAX’s most distinctive strengths is its programmability and extensibility, and Modular 26.1 brings that into sharper focus.
The MAX Python API makes it easy to port custom GenAI models — often trained in PyTorch — into a high-performance format that runs across diverse hardware. With 26.1, the eager execution APIs graduate out of experimental, offering a PyTorch-like modeling interface backed by more robust documentation and a growing developer community.
The result is that MAX is no longer just a faster way to serve models — it’s a platform for building and serving GenAI models end to end, without sacrificing performance, portability, or control.
A More Natural Python Modeling Experience
In 26.1, MAX takes a major step toward feeling intuitive to users coming from PyTorch:
- PyTorch-like modeling APIs are no longer experimental while retaining MAX’s portability and performance characteristics. See the model developer guide for more details.
- Eager mode support reduces friction during experimentation and interactive development. This significantly improves the developer experience and makes MAX feel far more natural during debugging, experimentation, and model bring-up. Although we’re still improving compile time, his release meaningfully closes the gap between PyTorch’s eager UX and MAX’s performance-first execution model. Check out the tensor fundamental guide and get the latest performance improvements in the nightly builds.
- Compile your MAX model for production by simply calling
model.compile(). You’ll get all the benefits of ahead-of-time graph compilation with the full speed and memory efficiency benefits you can expect from the MAX graph compiler and its high-performance GPU kernels.
Together, these improvements bring MAX much closer to the “just works” experience users expect, while preserving the ability to scale seamlessly into fully compiled, production-grade execution when performance and efficiency matter most.
A Hands-On Guide to Building an LLM with MAX

Our comprehensive guide to building an LLM from scratch (the MAX LLM book) is now stable and maintained alongside API changes in the nightly builds. If you saw the experimental version, take another look—we completely updated the sequence so the code you write in each step builds upon the last one, until you've built a fully executable OpenAI LLM in MAX.
The MAX LLM Book walks through every component of a transformer—from tokenization and embeddings to attention and decoding—while teaching you how to express these ideas using the MAX Python APIs. It’s designed for two audiences:
- Developers who want a deep, concrete understanding of how transformers actually work.
- Practitioners who need to customize or extend models for real production use cases.
Each chapter includes executable code and detailed explanations, making it both a learning resource and a practical reference. Start building now.
Expanded Apple Silicon GPU Support
Building on our initial Apple silicon GPU support in 25.7, we've significantly expanded coverage in 26.1. Simple MAX graphs can compile and run on Apple silicon GPUs, and all the Mojo GPU puzzles now run on Apple GPUs (excluding NVIDIA-specific puzzles). Future updates will expand our support all the way to LLM inference on Apple Silicon GPUs. Please join our community if you'd like to help build into this support.
The latest features are landing regularly in our nightly releases, so keep up with those to get the best support. You can also help by contributing new Apple silicon GPU support to many of our existing open source Mojo kernels.
A Growing Community of MAX Models
The past few months have marked a turning point in MAX’s evolution — from an internal framework to a community-grown modeling platform. Contributors from across the ecosystem are extending MAX with new model architectures, performance improvements, and infrastructure enhancements that benefit everyone. Here are a few highlights:
- Community member Sören Brunk contributed production-ready Qwen3 embedding support, including performance optimizations that match vLLM throughput, and infrastructure enhancements that improve MAX's architecture registry for all future multi-task models.
- Ryan Wayne added BERT embedding model support specifically to replace his CUDA-dependent text embeddings infrastructure, demonstrating MAX's appeal for simplifying production ML stacks.
- Tolga Cangoz is developing an ambitious Z-Image visual generation pipeline that will bring state-of-the-art diffusion-based image generation to MAX
We’ve already open-sourced the MAX Python API, our entire GPU kernel library (for NVIDIA, AMD, and Apple silicon), all our model architectures, serving pipelines, and more. If you're interested in contributing model architectures, performance optimizations, or expanding MAX's capabilities, check out our contribution guidelines and join the conversation in our MAX forum.
Mojo: More powerful and more ergonomic APIs
Mojo 26.1 delivers a set of foundational language features that move the language meaningfully closer to Mojo 1.0. Our objective with 1.0 is to provide a language that’s capable of high-performance computing for diverse hardware but is still a joy to use.
This release drives us toward that by incorporating research directions in language design for compile-time safety, improving the experience when you encounter errors, and enhancing the overall ergonomics of Mojo code. Specifically, this release adds:
- Compile-time reflection: A new system for compile-time reflection on types further enhances Mojo’s already versatile metaprogramming system. This powerful new capability allows, among other things, automatic conformance to traits that are defined in libraries. For example: automatic equatability, JSON serialization, or CLI argument parsing. Members of the Mojo community are already doing exciting things with this using nightly builds.
- Explicitly destroyed types: Mojo now supports explicitly destroyed types (aka "Linear Types" in programming language jargon), enabling compile-time guarantees that certain values cannot be forgotten. This is an example of Mojo drawing from leading research languages, exceeding the safety and power of most other widely used languages.
- Typed errors: Functions can now raise types other than Error, enabling error-handling on GPUs and embedded systems without overhead. Mojo also supports “parametric raise-ability”, enabling powerful and concise expression of generic algorithms.
- Improved error messages: We’ve fixed the biggest user-painpoint in Mojo error messages, where it would complain that it couldn’t infer a parameter instead of saying types don’t match. Mojo now also will diff two similar types and tell you which sub-parameter disagree when the types are almost the same!
- Mojo LSP server improvements: LSP users will see dramatically reduced CPU usage when typing, the compiler has experimental support for applying fix-it suggestions.
As always, there are far more interesting and useful additions to Mojo and its tooling than those listed above, so check out the full Mojo changelog.
Try 26.1 Today
Get everything you need to build LLMs with MAX and write high-performance GPU kernels with Mojo by installing the modular package with pip, uv, pixi, or conda. For more details, see our quickstart guide.
Once you’re set up, you can explore everything in Modular Platform 26.1:
- Follow the MAX LLM Book lessons to build a transformer model from first principles
- Run GPU puzzles and build MAX models on your Mac with Apple silicon
- Explore linear types and compile-time reflection in Mojo
For a complete breakdown, see the MAX and Mojo 26.1 changelogs.
Modular 26.1 is another step toward making high-performance AI development accessible to everyone. Your questions, feedback, and contributions directly shape the platform — join the discussion on our forum and report any issues or feature requests.
We can’t wait to see what you build!
Discover what Modular can do for you


