.png)

Each spring, San Jose fills up with people who have strong opinions about GPUs, and we're happily among them. Find us this week at NVIDIA GTC, Booth #3004, where we’ll be running demos all week on Blackwell.
Here’s a sneak peek of what we’ll be showing:
FLUX image generation on a DGX Spark, served with MAX
We're running Black Forest Labs’ open-source FLUX.2-klein diffusion model on an NVIDIA DGX Spark at the booth, using the MAX framework. You choose a prompt and watch it generate live, then scale remotely: the same code driving the FLUX.2-dev model on B200.
MAX handles the full pipeline: graph compilation, kernel dispatch, and serving, written in Mojo from the ground up, not assembled from third-party pieces. If image or video gen is on your team’s roadmap, stop by the booth to see for yourself how MAX handles a full diffusion pipeline.
Porting a CUTLASS Blackwell conv2d kernel to Mojo, using AI-assisted development
Last year at GTC, the most common thing people said at our booth was: "Yours is the only booth actually showing us how to program GPUs." This year, we’re doing it again.
This demo walks through porting NVIDIA's CUTLASS Blackwell conv2d kernel (76_blackwell_conv_fprop) from CUDA C++ to Mojo. The result: 130.7 TFLOPS on B200 (matching CUTLASS throughput) in roughly 770 lines of Mojo, versus ~3k lines in CUTLASS.
Mojo's structured kernel architecture let us reuse about 90% of our existing matmul infrastructure: warp specialization, TMA pipelines, TMEM management, CLC scheduling. The only new code was the im2col tile loader. The performance gap comes from Mojo's built-in autotuning and direct hardware access, with no black-box library and no hidden translation layer.
The entire port was done in a single session using Cursor and Claude. The agent analyzed CUTLASS source, implemented barrier synchronization, debugged GPU kernel hangs, and iterated from 0.16 TFLOPS to 130.7 TFLOPS. We'll show the git history so you can see every optimization step.
This is also a preview of where Mojo is headed: Mojo 1.0 is planned for later this year, bringing semantic versioning and a stable API surface. All kernel code is open source in our modular/max GitHub repository.
DeepSeek V3 on B200, via Modular Cloud
We're running DeepSeek V3 on NVIDIA B200 GPUs in the cloud, served through Modular Cloud. You send a prompt (text or code) and watch tokens stream back with live metrics: tokens per second, time-to-first-token, latency under load.
Deploying DeepSeek V3 at production scale means dealing with slow first-token latency, unstable tail latency, and inefficient GPU utilization. Modular Cloud is a fully managed endpoint, and optimized end to end with MAX and Mojo kernels. It scales with your usage so you don't have to manage the deployment yourself.
Unlike other inference platforms, we control the full stack through MAX and Mojo, which means we can tune performance at every layer. Enterprise teams interested in a dedicated endpoint for evaluation can talk to us at the booth.
Find us on the expo hall floor
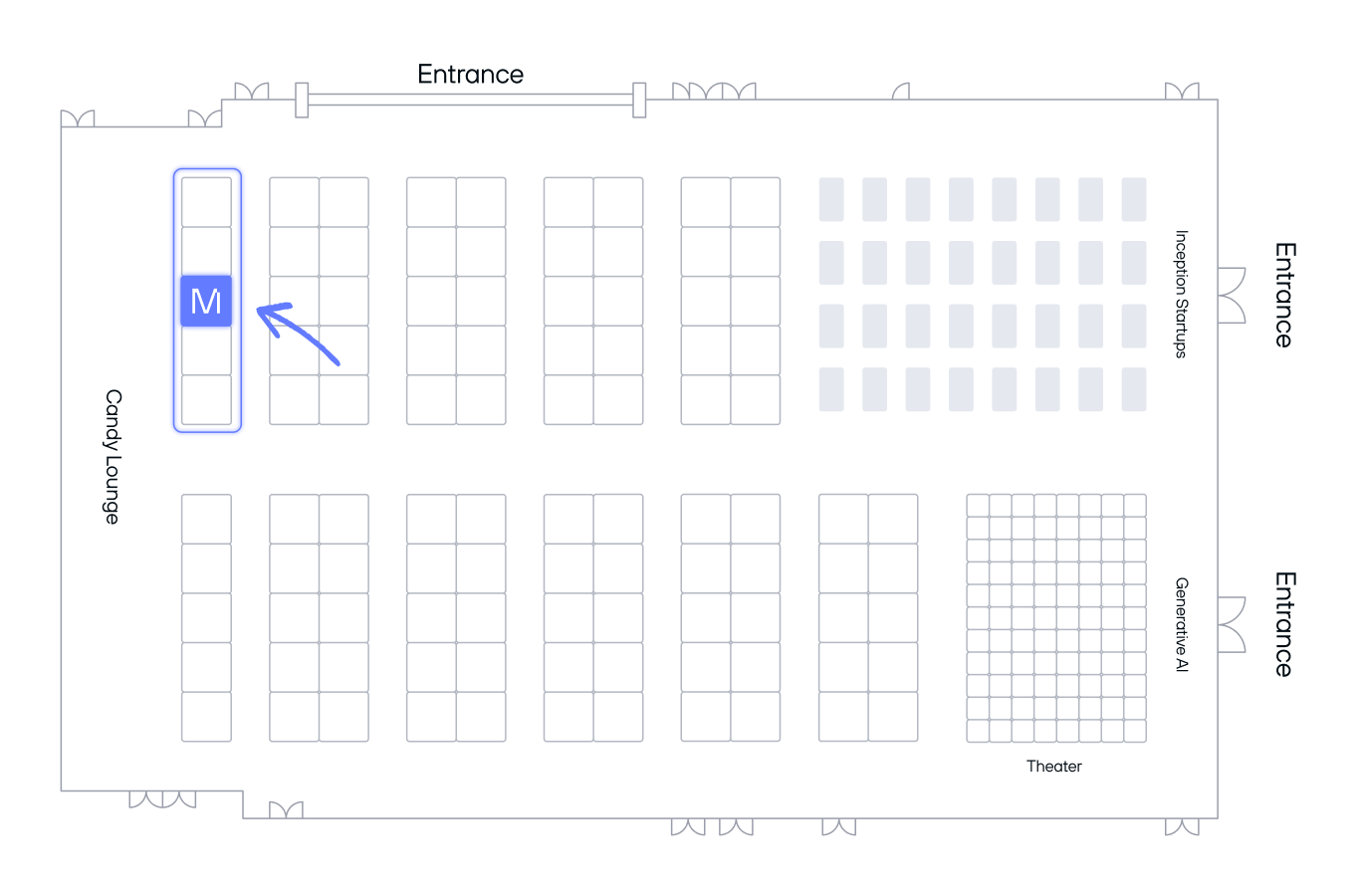
The full team will be at booth #3004 all week. We're happy to go deep on compilation, kernel optimizations, scaling inference, and more.
RSVP for updates on everything we have going on at the booth during GTC. We'll email you the full schedule and booth location details.
We're also co-hosting an Inference Happy Hour on Wednesday, March 18 (5-9pm PT, downtown San Jose) alongside Massed Compute, Rapt AI, Amaara, and Qwerky AI. Evening drinks and dinner, focused on AI founders and builders working through real inference problems at scale. No GTC pass required. RSVP here.
See what we were up to at GTC 2025
Want to evaluate MAX with your workloads?
If you're exploring options for inference infrastructure or open source model deployment, we'd love to show you what MAX can do on your specific use case. Stop by Booth #3004 this week, or book time with our team for a deeper technical demo after GTC.


