.png)

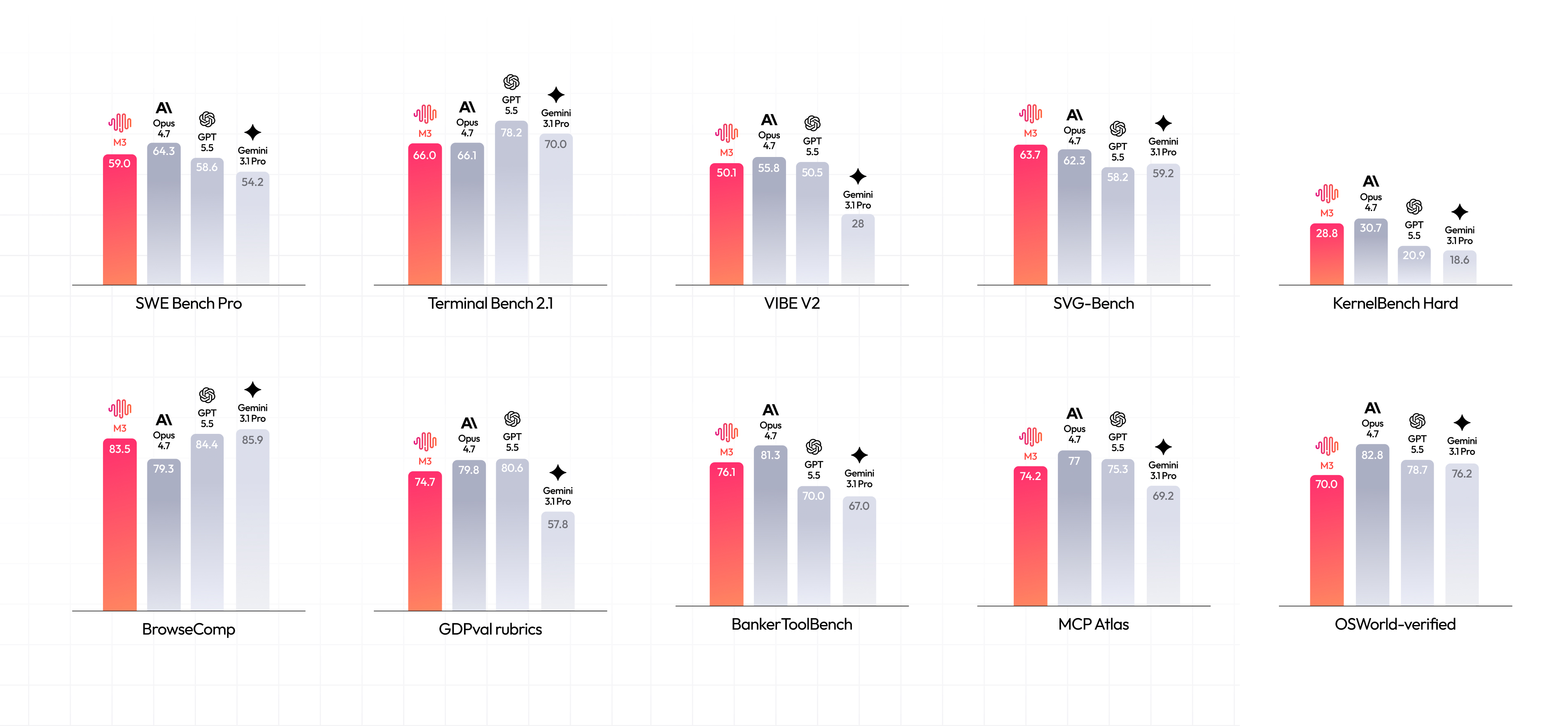
MiniMax M3 is the newest open-weights model that has been optimized for coding, agentic work, and native multimodality for MiniMax. A few things that make this a frontier model are:
- A 1M-token context window (with a guaranteed minimum of 512K), built for long-running agent tasks, large coding workloads, and long-video understanding.
- Native multimodality. M3 is trained on both text and images, so it is multi-modal by design.
- MiniMax Sparse Attention (MSA). This is the key that keeps attention efficient as context grows.
A look into MiniMax’s Sparse Attention
Behind M3 is a new MiniMax Sparse Attention (MSA) operation. MSA is what enables a 1M context to be served, and a big part of what makes M3 demanding to run well. But, if optimized, MSA’s design allows it to cut the per-token attention compute to roughly 1/20th of its full-attention predecessor. This results in around 9.7× speedup on prefill and 15.6× speedup on decode, while matching full attention across the vast majority of workloads.
MSA splits every attention layer into two parts: which KV to look at, and how to attend to it. The first is solved by introducing an indexing layer. For each query, the indexer scores candidate KV blocks and chooses the top-k blocks. The indexer also maintains a cache of index keys with a single shared head and a small head dimension. By focusing only on top scoring KV cache blocks, MSA only computes the attention of the relevant 128 tokens in the KV caches rather than the full block.
The model produces selection in query-major form: for each query, a list of top-k block IDs. The natural kernel follows that shape — loop over queries, gather their selected KV blocks, and then attend. Executing in query-major order would mean each query independently gathers its selected blocks, the same KV block may be fetched from HBM many times (which is not very efficient).
To avoid the repeated loads, MSA inverts the mapping by grouping the queries by the KV block they selected; i.e. executing in key-block-major form and what MiniMax calls “KV outer gather Q”. As a result, we can improve the arithmetic intensity since the blocks are loaded once, before computing partial attention for all of those queries, and then merging the partial results.
This structure has an added benefit of simplifying the online softmax computation. Remember that in query-major attention one needs to perform online softmax. But in the block-major format, a thread block only ever sees one KV block per query group. Thus the softmax can be performed on a single tile without the need for an online correction. This is very much similar to the split-kv reduction step in flash decoding.
Minimax M3 available today on Modular Cloud
The MiniMax M3 model bring novel innovations that require whole stack optimizations - from kernels to cloud. This is only possible in the Modular platform. MiniMax M3 is available on Modular Cloud today for enterprise customers. Talk to our AI engineers to request access today.
Discover what Modular can do for you


