

Introduction
Key–Value Cache (KV cache/KVCache) is a foundational building block of modern LLM serving systems. It stores past attention states so the model can generate new tokens efficiently without excessive re-computation.
There are two phases to LLM inference: Prefill and Decode. In the Prefill phase, the attention states are computed for each token in the input prompt. In the subsequent Decode phase, new tokens are generated one by one in an autoregressive fashion by attending on the Key-Value associated with previous tokens.

vLLM, SGLang, TensorRT-LLM, and MAX Serve are all built on top of increasingly sophisticated KV cache management. This blog explores the evolution and role of the KV cache in these inference engines
Era 0: Pre-GenAI (<2017)
Before transformers took over, deep learning was dominated by stateless, feed-forward architectures like ResNet, YOLO, VGG, and Inception. These models did not require persistent state across inference steps, so the concept of a KVCache simply didn’t exist even in inference frameworks like ONNX or TensorRT.
Era 1: Continuous KV Cache (2017)
The original transformer (2017) established the architecture that would eventually dominate ML. This design was a departure from prior models, requiring a KVCache to efficiently keep track of the state associated with each request. Nevertheless, the major step-change in intelligence enabled by transformers more than justified their added complexity.
At the time, early LLM serving engines implemented KV caches naively:
- For each request, they preallocated a contiguous KV tensor with
max_seq_lentokens. - The storage was
2 x num_layers × num_heads × head_dim × max_seq_lenper request.

This Contiguous KV cache design was extremely wasteful, but still offered huge performance gains over recomputing attention keys/values for each token:
- ✔ Simple
- ✘ Memory usage scales aggressively due to the
max_seq_len × batch_sizefactor - ✘ Constrained
max_batch_sizedue to limited memory capacity - ✘ High memory fragmentation due to variable-length requests
- ✘ Most request are far shorter than
max_seq_len, leaving much wasted capacity
This was the approach of early inference engines like HuggingFace Transformers.
Era 2: PagedAttention (2023)
A breakthrough arrived with PagedAttention, introduced by vLLM. The key idea was to borrow a technique from Operating Systems by allocating KV in fixed-size pages that could be dynamically allocated as sequences grew.

Benefits:
- ✔ Dramatically improves memory utilization and reduces fragmentation
- ✔ Enables hundreds / thousands of concurrent requests
- ✔ Drives up throughput via larger batch sizes
- ✔ Allows for efficient KV cache reuse via Prefix Caching, a huge throughput multiplier for multi-turn chat workloads
PagedAttention became the de-facto standard for LLM serving, leading to new inference engines like TensorRT-LLM and SGLang.
Era 3: Heterogenous KV Caches (2024)
The world of ML and the LLM serving landscape is far more complex now. New optimizations along with modern multimodal and hybrid models require multiple different kinds of state, each with separate caching requirements. In this Era, the term “KV Cache” is being stretched far beyond its original meaning.
- Speculative decoding accelerates LLM inference by having a small draft model generate multiple tokens ahead and then using a larger target model to verify and accept those tokens in a single pass. With this technique, a separate KV cache needs to be maintained for the draft and target model.
- Vision encoders in Vision–Language Models (VLMs) generate large image embeddings that can be cached and reused across requests. While this differs from the traditional notion of a “KV cache” or prefix caching, it follows the same underlying principle of memoizing expensive intermediate states. Models which benefit from this cache include QwenVL and InternVL.
- Quantized KV Cache: Low precision datatypes like FP8 help reduce the storage requirements of the KV cache and rely on per-tensor/row/block scaling factors to preserve numerical range. This requires the KV cache implementation to also manage memory for these scaling factors.
- Sliding Window Attention (SWA) limits each token to attend only to the preceding
window_sizetokens instead of the entire sequence, reducing memory and compute. As a result, KV cache management and prefix caching must track which tokens fall within the current window, making cache hits and evictions more complex than in full attention.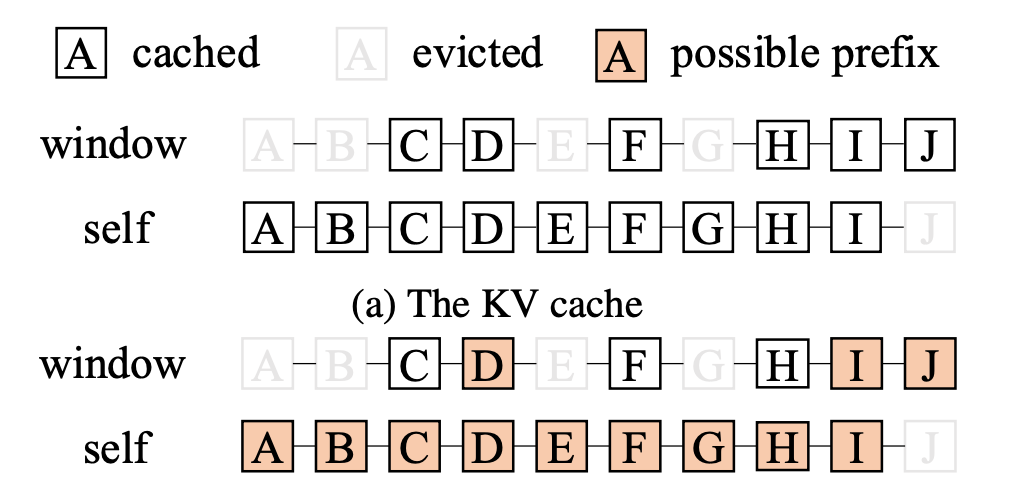
Fig 11. https://arxiv.org/pdf/2503.18292 - Mamba / State Space Models replaces attention with a recurrent state that updates a single large vector for each new token. This makes prefix caching more complex because serving systems must decide when and how to checkpoint or store the evolving state vector for future reuse.
- Composite Models are composed of multiple sub-models. For example, it is a common pattern to combine an LLM backbone with an audio decoder. Each of these sub-models may require maintaining separate KV caches.
- Hybrid Models combine multiple layer types within a single model, which often necessitates maintaining multiple KV caches to handle each layer’s distinct attention or state mechanism. Examples include:
- Sliding Window Attention + Full Attention (Gemma2/3, Ministral, GPT-OSS, Cohere)
- Mamba + Full Attention (Jamba, Bamba, Minimax)
- Local Chunked + Full Attention (Llama4)
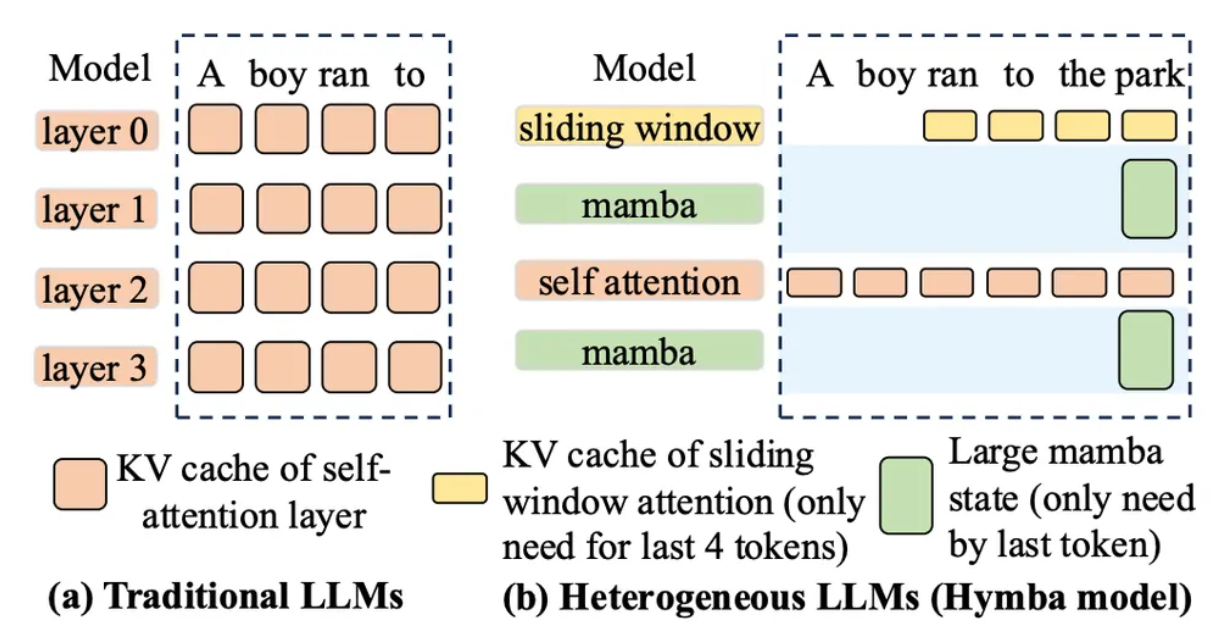
Fig 1. https://arxiv.org/pdf/2503.18292
This heterogeneity and diversity of KV cache’s with different shapes, lifetimes, and properties led to the creation of specialized managers in modern LLM serving engines. For example, vLLM has the Vision Encoding Cache, Mamba Cache, etc, in additional to its normal KV cache.
There are several challenges emerging with this design:
- ✘ Memory fragmentation due to multiple KV cache managers can lead to small batch sizes
- ✘ Challenging to predict at server startup how much memory to allocate per KV cache
- ✘ Disjoint Prefix Caching implementations lead to suboptimal cache hit rates
- ✘ Diversity makes feature composition challenging
Era 4: Distributed KV Cache (2025+)
As LLMs grow in size and handle increasing workloads, a single GPU or node becomes insufficient. Now LLM serving and the KV cache is becoming multi-node and distributed, often spanning an entire datacenter. Managing the massive scale of the KV cache requires new techniques as such:
- Disaggregated Inference: LLM inference is divided into Prefill and Decode phases, deployed and scaled on separate model instances to reduce interference and optimize resource usage. A key challenge is efficiently transferring the KV cache from Prefill nodes to Decode nodes. Recently new variants of disaggregation have emerged like Encoder Disaggregation.
- KV Cache-aware Load Balancing: Request routing prioritizes instances that already hold the relevant KV cache, maximizing prefix cache hits. This requires a cluster-wide view of the current state of the KV cache on each of the individual instances.
- Hierarchical KVCache: To increase KV cache capacity, cold pages can be spilled from GPU memory to more abundant CPU RAM or SSD. This extends the effective KV cache size while keeping the hot, frequently accessed pages in GPU memory for low-latency access. The higher latency of loading/storing of KV cache for one model layer from a lower tier of the cache can be hidden by overlapping it with the GPU execution for the prior layer.
Many new kubernetes-native inference solutions like Nvidia Dynamo, vLLM Production Stack, llm-d, or AIBrix have emerged to tame this complexity. However, distributed LLM inference is still very hard:
- ✘ Many existing optimizations or architectures are still incompatible with distributed inference like speculative decoding or VLMs
- ✘ Despite the wide availability of open-source solutions, it still requires expert knowledge and a lot of patience to deploy
- ✘ Inter-node GPU networking over Infiniband or RoCE is challenging and many libraries like NIXL are nascent
- ✘ There are many inherent problems for large-scale distributed systems such as managing failover, stragglers, hardware defects, auto-scaling, etc
Era 5: Unified Hybrid KV Caches (2025+)
The next stage is building unified KV memory systems where many heterogeneous KV types share a common memory pool rather than isolated allocators. Another overarching theme in this era is striving for composability between all available optimizations.
This evolution is happening today!
Emerging approaches:
- vLLM / Jenga – Huge Pages + LCM Sizing
- Use huge pages with sizes chosen as the least common multiple of smaller page formats so different KV shapes can co-exist efficiently.
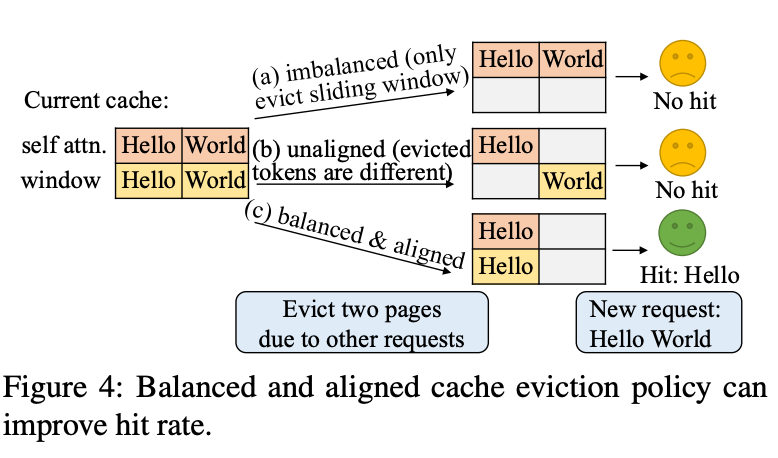
- Unified Prefix Caching design that takes into consideration many KV caches at once to improve balance and hit rate.
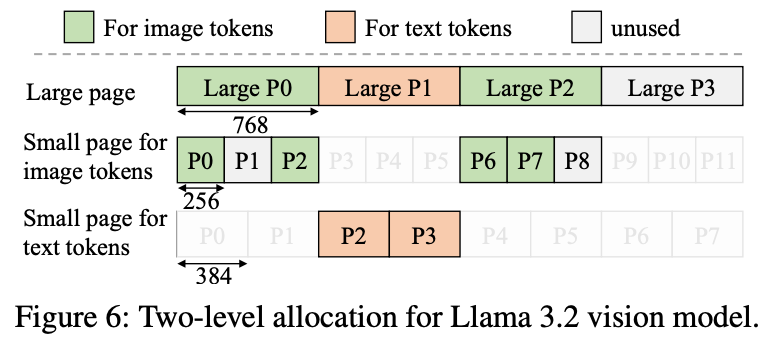
2. SGLang – CUDA Virtual Memory
- SGLang uses CUDA Virtual Memory APIs to dynamically remap device memory and unify different KV regions.
- his enables virtually contiguous but physically scattered KV pages
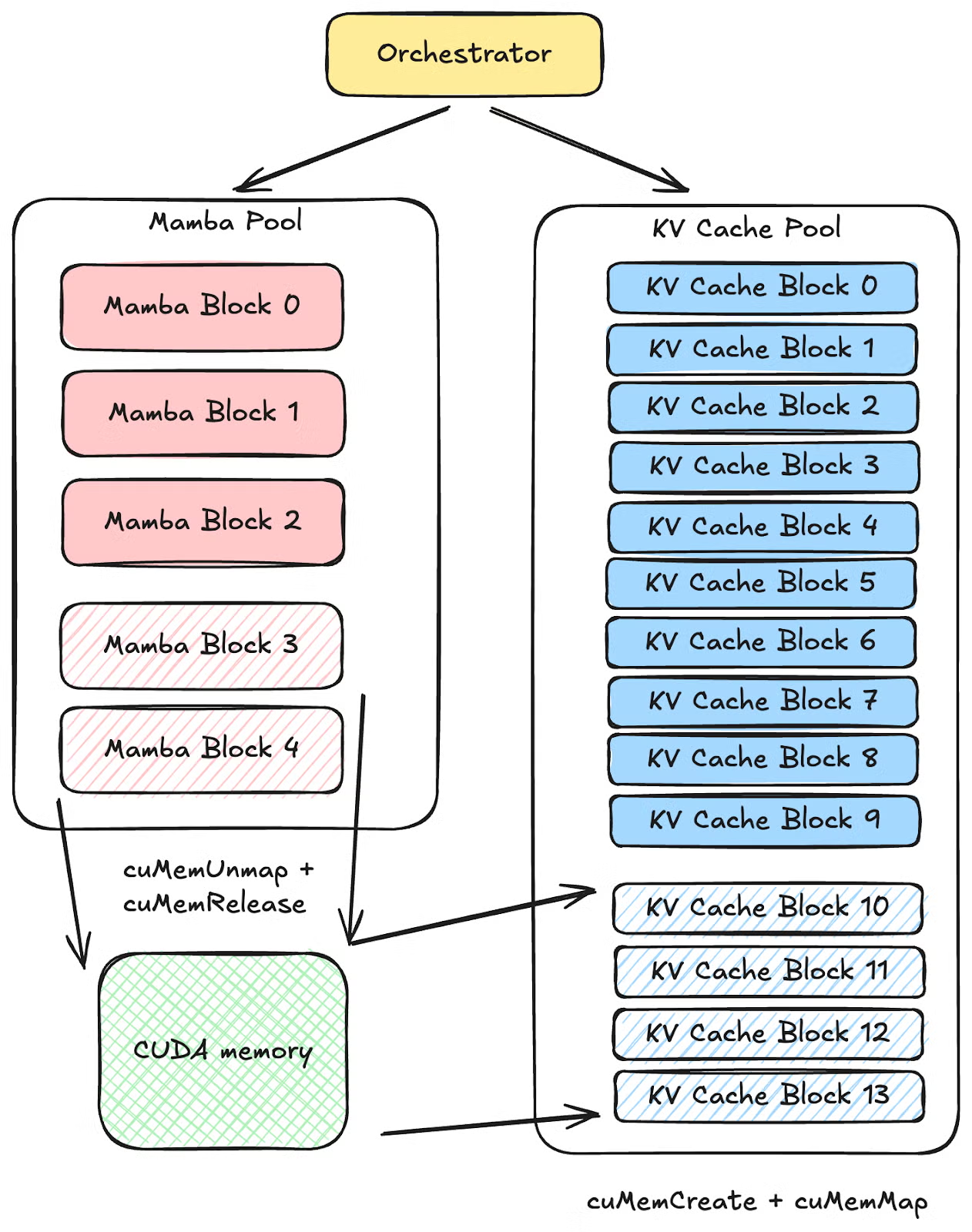
- Significant effort is also being invested into feature composability. In fact, this is one of the critical tenets of the 2025Q4 SGLang roadmap. For instance, one should be able to run a VLM model with Speculative Decoding across multiple nodes in a disaggregated setup. This will require long-term software investment and re-architecting core components of the inference engine.
Conclusion
What began as a simple optimization—caching attention states to avoid recomputation—has evolved into one of the most complex subsystems in modern AI infrastructure. Each era has brought new challenges: memory fragmentation, heterogeneous model architectures, distributed coordination, and now the need for unified systems that compose cleanly across all these dimensions. As new models, optimizations, and hardware emerge, KV cache management will require innovation across all layers of the LLM inference stack from GPU kernels to cluster-scheduling.
This complexity is precisely why we built MAX with a ground-up approach to KV cache management. Combined with Mojo's performance and flexibility, we're building infrastructure that handles today's models while adapting to tomorrow's innovations.
Interested in how MAX handles KV cache for your workloads? Get started here or join our community to discuss with the team.


