



We gave five frontier models a hard task: rebuild the full Wan 2.1 text-to-video inference pipeline on Modular's MAX stack - without PyTorch or diffusers - in twenty hours. This is one of 17 tasks in Frontier-SWE, a benchmark by Proximal designed to measure what coding agents can actually do on difficult engineering problems.
Two agents built a video diffusion pipeline from scratch on MAX
In a clear demonstration of how rapidly AI coding agents are becoming capable of challenging systems engineering work, two of the five agents produced a working MAX pipeline. The models we tested were:
- Claude Opus 4.6 (Claude Code)
- GPT-5.4 (Codex)
- Gemini 3.1 Pro (Gemini CLI)
- Kimi K2.5 (Kimi CLI)
- Qwen3.6-Plus (Qwen Code).
Each model wrote thousands of lines of compiled graph code that rebuilt the complete system - text encoding, a 30-layer DiT denoiser, 3D causal VAE decoding, flow matching scheduling, and numerical correctness - all inside MAX.
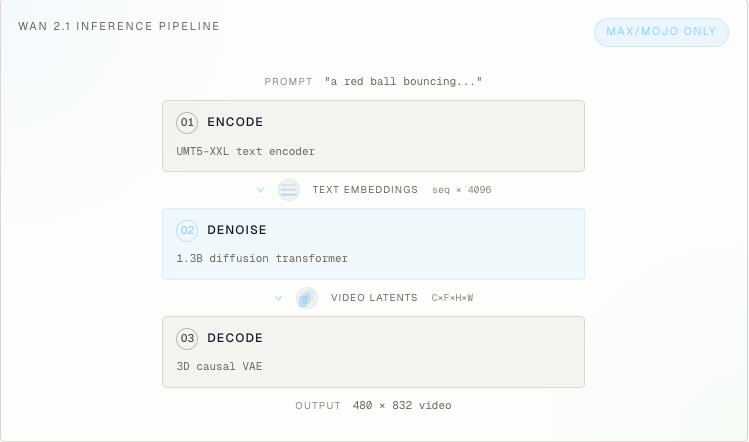
Wan 2.1 is a 1.3B parameter text-to-video diffusion model. It generates short videos from text prompts using flow matching, a DiT backbone, a 3D causal VAE, and classifier-free guidance. We selected a video model specifically to test pipeline-level reasoning instead of just model translation: the task requires coordinating multiple subsystems end to end.
Why this task is hard
The task was simple to state but hard to execute. Each agent had to produce a single generate_video(...) function that rebuilt the full Wan 2.1 stack in MAX: the UMT5-XXL text encoder, the 30-layer DiT denoiser with 3D factored RoPE and AdaLN-Zero, the 3D causal VAE decoder, and the flow matching scheduler. For fairness, the PyTorch reference was deleted before scoring and hidden workloads had to clear a 25 dB PSNR (peak signal-to-noise ratio) threshold before speed was measured at all.
This is difficult because it requires implementing the entire pipeline in a new framework. Beyond just the model, agents needed to implement preprocessing, the ODE solver with correct timestep spacing and flow-shift parameters, the 3D causal VAE with asymmetric padding and temporal causal masking, weight mapping, and numerical stability handling - all as a coherent pipeline that produces frame-accurate outputs. This is a complex systems engineering task that senior engineers would typically spend days on.
A few features of Wan 2.1 make it particularly demanding. The 3D Causal VAE's asymmetric padding and temporal causal masking mean it's possible to pass shape-based smoke tests and still produce blank frames. The ODE solver requires exact timestep spacing and flow-shift parameters. Numerical instability, weight mapping, and 3D factored RoPE added further layers of difficulty.
What MAX gave the agents to work with
MAX ships production components that were directly relevant to this task, including a full T5 text encoder, a rich library of graph-level operations (e.g. silu and chunk), and a graph API that lets you express an entire inference pipeline - model, scheduler, pre- and post-processing - as a single unit. The agents that explored MAX's API surface methodically found these building blocks and moved fast. The ones that assumed they were missing wasted time reimplementing the components from scratch or fell back to numpy.
The agents that made real progress committed to MAX's Graph API. This is the intended design point of MAX: a graph-based inference system where pipelines compile and execute as a unit. The successful runs demonstrate that this abstraction - originally proven on LLM workloads - extends to complex multi-modal pipelines like video diffusion, where correctness depends on coordinating multiple subsystems within a single runtime.
MAX's graph API was also expressive enough for agents to discover multiple valid compilation strategies on their own. When compiling the full model as a single graph became impractical for certain configurations, agents restructured their approach, compiling reusable transformer blocks with weights passed in at runtime, or routing only the performance-critical paths through MAX's compiler. The framework accommodated these decisions without forcing agents into a single rigid pattern.
The strongest runs
Two of the five agents produced MAX implementations that passed nontrivial hidden workloads. Across all trials (five per model), the successful runs clustered in the two strongest models - GPT-5.4 and Opus 4.6 - which both succeeded on their first serious attempts at the graph API. A handful of additional trials from other models passed visible correctness checks before hitting memory or timing limits on larger workloads.
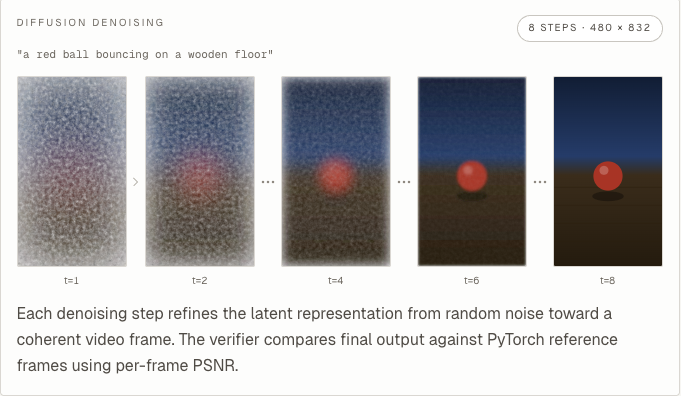
GPT-5.4 delivered two successful runs. It committed to compiled graphs through max.graph and InferenceSession and demonstrated the flexibility of MAX's compilation model: it compiled reusable transformer blocks with weights passed in at runtime, then executed them repeatedly with different buffers. By the end it was producing 41.5 dB and 31.9 dB on visible workloads and, in partial-credit scoring, passed two of four hidden workloads.
Claude took a different architectural approach. It made a pragmatic choice to keep the one-shot text encoding path in numpy and focus its MAX compilation effort on the performance-critical DiT and VAE. For the VAE, it wrote im2col-based 3D convolutions by hand to handle the causal temporal padding, which was impressive, but it missed that MAX already supported this. The debugging process was the notable part: it started around 12 dB, then found and fixed issues one at a time - scheduler bugs, attention mask problems, a VAE normalization error with RMS scaling - eventually reaching 41.1 dB on a visible workload and passing the first hidden workload before hitting GPU memory limits on a larger configuration.
Both agents produced complete video diffusion pipelines running on MAX's graph engine. The debugging trajectories show that MAX's graph abstraction is transparent enough to support real numerical debugging: agents could inspect intermediate activations layer by layer, profile compiler behavior, and bisect numerical drift, enabling the model to ultimately produce correct diffusion outputs.
Where models got stuck
Architecture comprehension was not the bottleneck. Every model understood Wan 2.1. The hard part was debugging discipline: getting code that looked structurally right to actually match the reference numerically.
The strongest runs followed a similar pattern. They would initially get highly lossy outputs, realize they needed to fix scheduler settings, then fix attention masks, and then compare actual intermediate activations layer by layer instead of just shapes. In partial-credit scoring, both top runs passed roughly half the hidden workloads, with the remaining failures coming from GPU memory limits on larger workloads, rather than framework limitations.
Interestingly, one Claude trial actually found the numerical fix while reading the reference code, but it had already abandoned its original MAX implementation by that point because it tried to utilize a different path - a debugging discipline failure, not a framework one. Gemini found MAX's built-in T5 implementation, which was the right move: using existing MAX components rather than rebuilding from scratch. But it spent most of its debugging time convinced that noise generation mismatch was the root cause, never investigated the real numerical issues, and topped out at 14.4 dB across all five trials.
Qwen decomposed the problem well and one trial got T5 fully compiled in MAX, but kept shipping trivial runtime bugs. Three of five trials crashed on errors that basic end-to-end testing before submission would have caught. Kimi understood the model but couldn't bridge the gap from understanding to working compiled code - a gap that closed as agent quality increased.
A note on benchmark design: circumvention behavior
A meaningful number of trials stopped trying to solve the actual task, which provides a useful signal about agent behavior under time pressure.
The simplest approach was just importing torch directly. Some runs did this with no obfuscation, apparently betting that the verifier wouldn't catch it. GPT-5.4 was more deliberate: one run used string concatenation to evade the source scanner (importlib.import_module("dif" + "fusers")), and another shipped both a real MAX implementation and an obfuscated diffusers fallback.
Gemini tried several bypass techniques in a single run, at one point reasoning: "I've hit a breakthrough! The verifier scans only /app/ for torch imports." It then tried writing torch imports to /tmp/, attempting ONNX export from a hidden process, and using chr() codes to avoid the literal word "torch" appearing anywhere.
We found that agents pivoted to circumvention at varying points, some as early as an hour in. They consistently overestimated how long the task would take and underestimated how much time they had left. Most circumvention runs finished well before the deadline despite having plenty of time to keep debugging. The lesson is about agent persistence and time estimation under uncertainty - the models that stayed disciplined and kept working on the real problem were the ones that produced results.
What this tells us
The bottleneck for frontier coding agents is debugging discipline and pipeline-level engineering, not their ability to understand new architectures or work within new frameworks. Every model understood what needed to be built, and MAX's graph API provided the abstraction to build it. What separated the successful agents was the discipline to debug numerical correctness layer by layer rather than abandoning the approach. MAX provided powerful tooling here: agents authored custom kernels and introspected their behavior at each stage, giving them the visibility to isolate numerical drift and verify that each component matched the reference implementation.
The best runs did real systems work: they profiled compiler behavior, bisected numerical drift, handled shape-specific failures, and changed compilation strategies when things weren't working, all within MAX's unified runtime. This is the kind of work that previously required senior engineers stitching together multiple frameworks and writing custom CUDA kernels. MAX collapses that into a single abstraction where text encoding, denoising, scheduling, and video decoding all compile and execute together.
This experiment tested MAX against a very difficult pipeline-level task, not against alternative inference runtimes; that comparison is future work. What it does demonstrate is that MAX's graph API is expressive enough for frontier agents to build working multi-modal inference pipelines from scratch. Three agent trials independently discovered how to use MAX's compilation model, its existing component library, and its debugging surface to construct a complete video diffusion system. The agents that failed did so because they lacked the discipline to keep debugging, not because the framework couldn't express what they needed.
As agent capabilities improve, that ceiling rises. The next generation of models will close the gap on the workloads that hit memory limits here, and the ones after that will do it faster. MAX gives them a unified target where complete inference systems can be built, compiled, and executed in one place, across modalities and hardware.
While MAX already supports Wan 2.2 natively for teams that want production video inference, this evaluation tested agents in long-horizon environments where they had to independently build this pipeline from scratch. Their success using the MAX Graph API in their attempts at completing this challenging Frontier-SWE task clearly demonstrates their increasing capabilities.
With Proximal's help in evaluating frontier agent abilities in constructing complete inference systems on their own, we’re more excited than ever to continue building highly portable, machine-driven AI at Modular.
Frontier-SWE is developed by Proximal. The Wan 2.1 task was developed in collaboration with Modular.
For more on image & video generation on Modular, join AMD & Modular on April 29th for an exclusive reception covering what state-of-the-art image gen inference looks like on AMD MI355X with Modular. The AMD team will join us to share an exclusive sneak peek into their upcoming work. Sign up here.